前言
《比特幣編程》是一本由 Jimmy Song 所撰寫的深入淺出的比特幣開發教學書籍。本書將會帶領讀者從基本的數學概念開始,逐步深入探討比特幣網路的核心運作原理,以及比特幣網路的交易和區塊結構。

《比特幣編程》的主要內容包含:
-
比特幣與區塊鏈的基本概念介紹
-
數學背景知識,包括橢圓曲線加密,SHA-256,RIPEMD160 等
-
比特幣網路的運作原理
-
比特幣的交易結構與驗證方法
-
比特幣區塊的結構與驗證方法
-
比特幣協議的實現方式
-
如何與比特幣節點進行溝通
此書將幫助讀者建立對於比特幣底層技術的深入理解,並學會如何使用 Python 語言實現相關的協議和算法。
1. 第一章 有限域
學習比特幣最困難的事情之一是不知道從何處下手。很多內容之間相互依賴,學習一個內容時會要求掌握另一個領域的前置知識點。而這個前置的知識點可能導向另一個新的不同領域的知識點。不充分掌握這些前置內容,就很難理解最初想要學習的知識。
本章將從一個易於理解的起點開始。儘管看上去有些奇怪,但為了理解橢圓曲線密碼學我們需要從基礎數學開始。作為回報,橢圓曲線密碼學的知識則導向數字簽名和驗證的算法,而這恰恰是一筆交易能正常流轉的核心。這裡所說的"交易"實際上也是比特幣價值轉移功能的基本單位。所以,先學習有限域和橢圓曲線,就能扎實地掌握我們深入學習比特幣所需要的基礎概念。
對於沒有經過長期且正式數學訓練的讀者,我們需要提示的是本章和之後兩章學習過程會像吃土一樣難以下嚥。但是我們還是希望讀者們能夠盡力一點點地讀完,因為這些概念和代碼將會在整本書中反復使用。
1.1. 學習更高等的數學
學習新的數學內容或許會有些令人生畏,在本章的學習過程中,希望能夠破除數學很難的錯誤觀念。具體的說,掌握有限域並不需要很多前置的數學知識,比如基礎的代數學。
把有限域想象成和三角學一樣容易獲取的知識,只不過三角學知識因為更有用所以安排在了我們的教育大綱內。總之有限域並不會太難掌握,只需要之前學習過代數學的相關知識。
如果你想瞭解橢圓曲線密碼學,本章知識是必須學習的。橢圓曲線是能理解數字簽名和驗證的前置條件,而數字簽名和驗證則是比特幣的核心內容。正如之前我們解釋的那樣,本章和後面兩章之間可能沒有什麼聯繫,但仍然鼓勵讀者去面對與接受。這些基礎知識不僅能幫助你更容易地理解比特幣,還有益於理解Schnorr 簽名、加密交易以及其他主流且前沿的比特幣技術。
1.2. 有限域的定義
有限域的數學定義是一個有限的數字集和兩個運算 +(加法)和 ⋅(乘法)並且滿足下面的性質:
-
如果a 和 b 屬於集合,則a+b 和a⋅ b也屬於集合。我們稱此性質為封閉性
-
存在0使得 a+0=a我們稱此性質為加法單位元。
-
存在1 使得 a ⋅ 1=a我們稱此性質為乘法單位元。
-
如果a屬於集合,則-a屬於集合,滿足a+(-a)=0 我們稱此性質為加法逆。
-
如果a屬於集合,則a-1屬於集合,滿足a⋅ a-1=1 我們稱此性質為乘法逆。
讓我們來進一步分析這些准則:
我們有一個有限的數的集合,因為集合是有限的,我們可以把集合大小定義為p,我們稱之為集合的階。
#1 要求我們對加法和乘法封閉。這意味著我們定義加法和乘法是要使其運算結果仍然屬於集合。比如集合 0,1,2並不對加法封閉,因為1+2=3,3 不在集合內;同理2+2=4 也不符合定義。當然我們可以對加法定義做一些修改來使其滿足有限域的性質,但是"常見"的加法並不能使這個集合組成有限域。另一方面,集合 -1,0,1 對正常的乘法是封閉的。任意兩個集合內的元素(共有九種組合)其乘積仍然屬於集合。
另一個選項是對乘法重新定義以滿足有限域的封閉性。我們會在之後的章節討論如何精確定義加法和乘法來使得集合封閉。但是其核心概念是我們定義的加法和減法不同於我們熟悉的加法和減法。
#2 & 3 意味著必須要有加法和乘法恆等元,也就是0和1 必須在集合內。
#4 我們有加法逆。如果a 在集合內,-a 也在集合內,通過使用加法逆運算,我們可以定義減法。
#5 意味著乘法有著相同的性質,如果a 在集合內,則a-1 也在集合內。使得a⋅ a-1=1,通過乘法逆,我們可以定義除法。這是定義一個有限域最難的部分。
1.3. 定義有限集合
如果集合的階(大小)是p,我們可以說該集合的元素有0,1,2,3,…p-1。我們把這些數稱之為集合的元素,而不必稱其為傳統的數字 0, 1, 2 等。這些集合的元素在很多方面和傳統數字一致,但是在如加法、減法和乘法等運算上仍有一些地方不太一樣。 如下為有限域的數學表示: Fp=0,1,2,...p-1
構成有限域的是集合的元素。Fp是一個特定的有限域讀作「階數為p的域」(field of p)或者「階數為29的有限域」 或者其他階數(重申:數學家把集合大小稱為階)。在之間的數字代表域中的元素。我們給這些元素命名1,2,3等,因為這些名字便於我們使用。 一個階數為11的域: F11=0,1,2,3,4,5,6,7,8,9,10 一個階數為17的域: F17=0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16 一個階數為983的域: F983=0,1,2...982 注意,域的階數總是比最大元素大1。你可能注意到了每次我們給出的域的階數都是質數。出於很多之後才能解釋得清楚的原因,域的階數必須為質數的整數次冪,其中階數為質數的有限域是我們特別關心的。
1.4. 使用Python 構建有限域
我們將會在Python內創建一個有限域元素的類(class)用於表示有限域內的每一個元素,這個類的名字是FieldElement。 這個類代表有限域`F_{prime}`的一個元素。所以這個類的大致結構為:
class FieldElement:
def __init__(self, num, prime):
if num >= prime or num < 0: (1)
error = 'Num {} not in field range 0 to {}'.format(
num, prime - 1)
raise ValueError(error)
self.num = num (2)
self.prime = prime
def __repr__(self):
return 'FieldElement_{}({})'.format(self.prime, self.num)
def __eq__(self, other):
if other is None:
return False
return self.num == other.num and self.prime == other.prime (3)#1 第一步我們檢查 num 是否在 0 和 prime-1 之間(包含0和prime-1)。如果不是,則這是一個非法的FieldElement,我們拋出 ValueError 異常。這是我們得到一個不恰當的值時,應當拋出的異常類型。
#2 __init__的其餘部分用來初始化對象
#3 __eq__ 方法檢查兩個FieldElement的對象是否相等。只有num 和prime 都一樣時才相等。
通過我們的定義,我們已經可以做下面的測試:
from ecc import FieldElement
a = FieldElement(7, 13)
b = FieldElement(6, 13)
print(a == b)
print(a == a)False
TruePython 允許我們使用__eq__ 方法對FieldElement類重載==運算符,我們在之後也會利用這一點。
你可以觀察隨書代碼的運行。一旦你啓動 Jupyter Notebook(參見第XV頁的「Setting
Up」),你可以打開
code-ch01/Chapter1.ipynb`運行代碼並觀察結果。有關本章的練習題,可以通過點擊Exercise
1 box 內的鏈接打開`ecc.py。如果遇到困難,所有的答案在AppendixA 內。
1.5. 模運算
我們可以使用模運算使得有限域在加、減、乘和除的運算下是封閉的。 我們可以使用模運算在有限域上定義加法,模運算可能在學習除法時就學習過。還記得如下圖[Figure 1-1]的問題嘛?
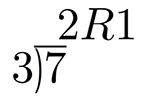
Figure 1-1. 長除法例1
(譯注:7除3商2余1)
不論是否整除,我們都可以獲得一個余數,即整除之後剩餘無法繼續被整除的數。我們也這樣定義模運算,使用%作為運算符:
7%3=1
[Figure 1-2] 是另一個例子。
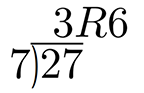
Figure 1-2. 長除法例2
正式的講,模運算是一個數被另一個數整除之後剩餘無法繼續被整除的值。我們看一個大一點數字的例子:
1747%241=60
如果把模運算想象成時鐘和指針旋轉會更好理解。想象下面的問題: 目前是三點,47小時後是幾點?應該是2點,因為(3+47)%12=2。([參考圖Figure 1-3])
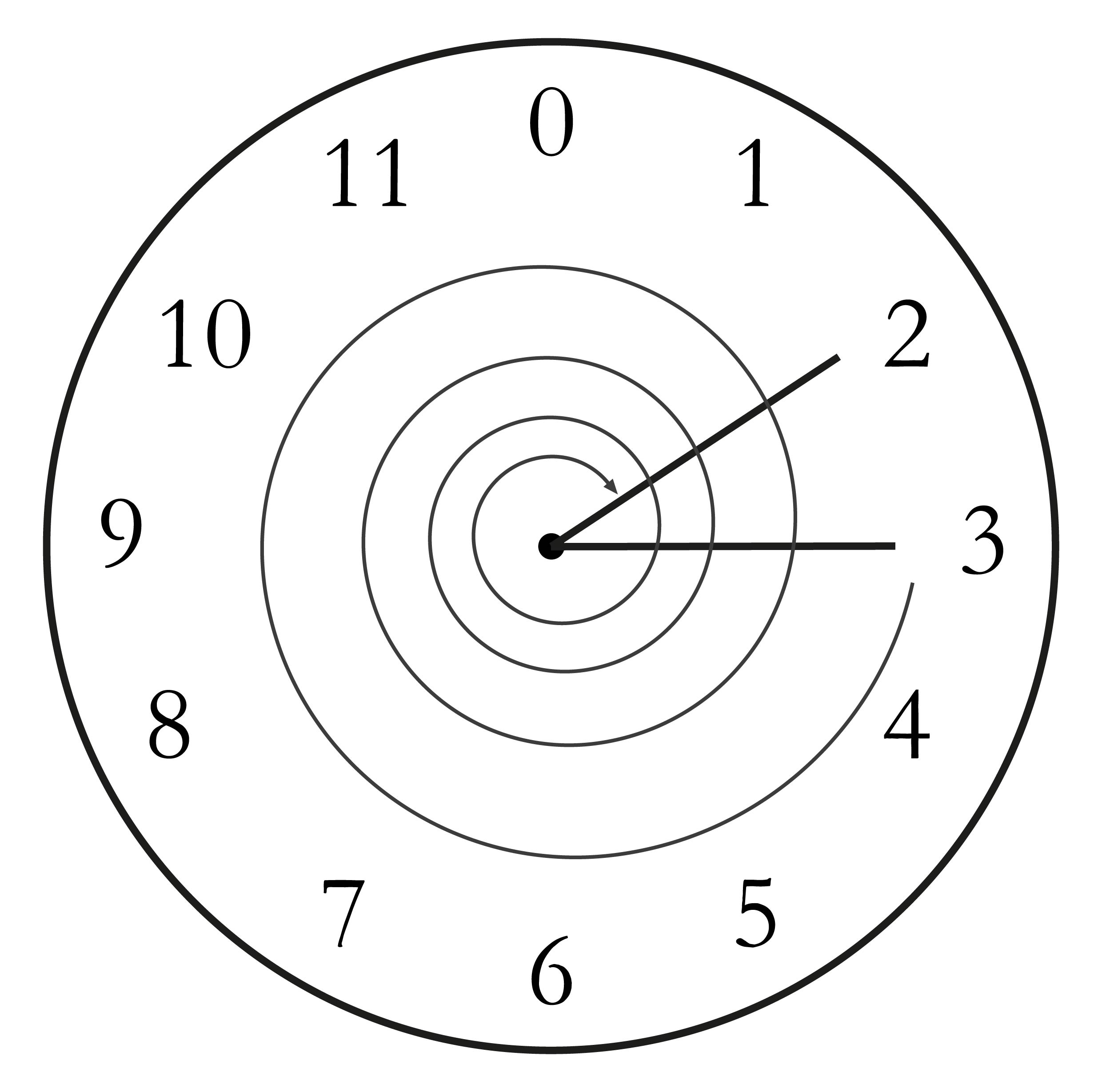
Figrue 1-3. 時鐘走了47個小時
我們可以看到,在這個模式下每過12小時,我們就會經過一次0時刻。我們也可以對負數做模運算,比如你可以問,目前是3點,16小時之前是幾點?
答案是11點,因為 (3-16)%12=11
分針同樣也是一種模運算。比如你可以問: 目前是分針是12分鐘,那麼在843分鐘之後分針在哪裡? 分針指向15分鐘。 (12+843)%60=15 類似的,我們可以問: 目前是分針指向23分鐘,97分鐘後指向哪裡? 在這種情況下,答案是0。 (23+97)%60=0 0表達了沒有餘數的情況。 模運算的結果總是在0 在 59 之間。這是一個非常好的性質,通過模運算,可以把非常大的數轉換成一個相對小的數字。
14738495684013 % 60 = 33 我們將要使用模運算來定義域的運算。在某種程度上,大部分的有限域的運算都使用了模運算。
1.6. 有限域的加法和減法
回顧前文,我們要在有限域上定義加法,使得任意兩元素其和仍然在集合內,也就是我們要求加法在有限域上是封閉的。
我們可以使用我們剛剛學過的模運算來使加法封閉。假設我們有個階數為19的有限域: F19=0,1,2,...18 如果a,b ∈ F19,注意,我們使用'∈'符號代表元素屬於集合內,這個例子中,指的是 a 和 b是F19的元素。 加法封閉意味著: a+ᶠ b ∈ F19 我們使用+ᶠ符號來代表有限域的加法,以免和常用的整數加法(+)混淆。
如果我們使用模運算,我們就可以保證滿足條件。我們可以這樣定義a+ᶠ b: a+ᶠb=(a+b)%19 比如: 7+ᶠ8=(7+8)%19=15 11+ᶠ17=(11+17)%19=9 我們對任意在集合內的兩個元素做加法,然後"旋轉"(按照時鐘例子的思路),最後得到和。此時我們定義了我們自己的加法運算符,雖然運算的結果有些反直覺。畢竟11+ᶠ17=9看上去就不正確,因為我們不習慣有限域的加法。
更通常的做法是像下面這樣定義有限域的加法:
當 a,b ∈ Fp,
a+ᶠ b=(a+b)%p
類似的,我們也可以定義加法逆運算。如果a∈ Fp 可以得出-ᶠ a ∈ Fp
-ᶠ a =(-a)%p
和之前一樣,為了使有限域的減法、負數和整數的減法、負數區分開,我們使用-ᶠ符號。 在F19中:
-ᶠ 9=(-9)%19=10
這意味著:
9+ᶠ10=0
結果證明這也是正確的。
類似的,我們可以定義有限域的減法:
當 a,b ∈ Fp,
a-ᶠb=(a-b)%p
比如在F19中:
11-ᶠ9=(11-9)%19=2
6-ᶠ13=(6-13)%19=12
1.6.2. 使用python 編寫有限域的加法和減法
我們現在可以對FieldElement 類增加__add__ 和 __sub__ 方法。我們想要我們增加的方法有下面的效果:
>>> from ecc import FieldElement
>>> a = FieldElement(7, 13)
>>> b = FieldElement(12, 13)
>>> c = FieldElement(6, 13)
>>> print(a+b==c)
True在python 中我們可以通過編寫__add__ 方法來定義加法(或者說+ 運算符)在有限域中的意義。所以我們怎麼實現它呢?我們結合我們之前學習的求模運算的知識,為FieldElement增加一個新方法:
def __add__(self, other):(1)
if self.prime != other.prime:
raise TypeError('Cannot add two numbers in different Fields')
num = (self.num + other.num) % self.prime(2)
return self.__class__(num, self.prime)(3)-
我們必須確保元素都來自相同的有限域,不然這個計算是沒有任何意義的。
-
如之前解釋的那樣,有限域的加法通過模運算定義。
3. 方法返回的應當是可以通過self.__class__方便獲取的類的實例。我們傳遞兩個初始參數, num 和self.prime 給我們之前定義過的__init__ 方法。 注意,我們可以使用FieldElement 來代替self.__class__。但這會使得這個類不方便被繼承,將來我們會設計FieldElement 的子類,所以在這裡使得將來方便繼承非常重要。
1.7. 有限域的乘法和指數運算
就像我們之前對有限域定義了新的加法(+ᶠ)且對域封閉,我們也可以定義一個新的乘法,也使得其對有限域封閉。在這部分,我們將會仔細的考察如何通過模運算定義乘法。
乘法是很多次的加法:
5⋅ 3=5+5+5=15
8⋅ 17= 8+8+8+..(共計17個8)+8=136
我們也可以使用同樣的方法在有限域上定義乘法。再一次使用F19:
5·ᶠ3=5+ᶠ 5+ᶠ 5
8⋅ 17= 8+ᶠ8+ᶠ8+..(共計17個8)+ᶠ8
我們已經知道如何處理等式右邊的部分了。結果會是一個屬於F19的數字:
5·ᶠ3=5+ᶠ 5+ᶠ 5=15%19=15
8·ᶠ 17= 8+ᶠ8+ᶠ8+..(共計17個8)+ᶠ8=(8⋅ 17)%19=136%19=3
第二個的計算結果非常反直覺。我們正常情況下,不會認為8·ᶠ17=3。 但是為了滿足乘法的封閉性這部分是必要的。所以域的乘法運算結果總是在屬於集合0,1,..p-1。
指數是簡單的乘以一個數許多次。 73=7·ᶠ 7·ᶠ 7=343%p 在有限域內,我們也可以利用模運算定義指數運算。 在F19 中: 73=7·ᶠ 7·ᶠ 7=343%19=1 912=7 指數運算也是同樣的反直覺。我們正常情況下也不認為 73=1 或者912=7。有限域必須這樣定義以滿足運算的結果仍在域內。
1.7.1. Exercise 4
在F97下解決下面的問題(同樣的,假設 ⋅ 和指數是有限域的運算符): * 97⋅ 45 ⋅ 31 * 17 ⋅ 13 ⋅ 19 ⋅ 44 * 127 ⋅ 7749
1.7.2. Exercise 5
對於 不同的k=1,3,7,13,18,如果在F19 運算下,下面的集合的結果是 k ⋅ 0,k ⋅ 1,k ⋅ 2,…k ⋅ 18 你觀察到了什麼?
|
為什麼域的階數是質數
Exercise 5 的答案就是為什麼域的階數一定是一個質數的冪。不論你選擇的k為何值,只要k>0,整個集合的元素乘上k後得到的集合會和原來的集合具有一樣的屬性。 直覺上,我們有一個質數階使得有限域內的元素都是等價的。如果域的階數是一個合數,整個集合的元素乘上一個除數k後我們會得到一個變小的集合。 |
1.7.3. 使用python 編寫乘法
我們已經瞭解域乘法在類FieldElement的性質,接下來我們定義mul方法來重載 * 運算符。我們希望有下面的功能:
>>> from ecc import FieldElement
>>> a = FieldElement(3, 13)
>>> b = FieldElement(12, 13)
>>> c = FieldElement(10, 13)
>>> print(a*b==c)
True就像加法和減法一樣,下面的練習內容是完成我們FieldElement 類的 __mul__方法。
1.7.5. 使用python 編寫指數運算
我們需要在有限域上定義指數。python可以通過定義__pow__
來重載 ** 運算符。這裡的不同的是指數部分不是一個FieldElement
類的對象。我們需要區別對待。我們需要類似下面的功能:
>>> from ecc import FieldElement
>>> a = FieldElement(3, 13)
>>> b = FieldElement(1, 13)
>>> print(a**3==b)
True注意指數的冪部分是一個整數,而不是另一個FieldElement的實例,所以指數方法的入參是一個整數,我們寫下以下代碼:
class FieldElement:
...
def __pow__(self, exponent):
num = (self.num ** exponent) %self.prime #1
return self.__class__(num, self.prime) #2#1 我們這樣做已經很好了,如果使用 pow(self.num, exponent, self.prime) 會更有效率。
#2 我們也必須返回這個類的一個實例。
為什麼我們不要求指數是一個FieldElement 的對象呢?是因為指數的冪部分不一定要是一個有限域的元素,這在數學上也是合理的。 如果指數的冪部分要求是域內的元素,指數的冪部分也不會像允許兩個同底數的相乘,指數相加那樣表現得符合我們直覺上的預期。
我們目前的代碼可能在數字較大的時候表現得非常慢,我們之後會使用一些更高級的技巧來提高這些算法的效率。
1.8. 有限域的除法
那些幫助我們建立加法、減法、乘法、甚至指數運算的直覺並不一定對除法一樣有效。因為除法是最難理解的運算。我們先從一些好理解的部分開始: 在「常見」 的數學中,除法是乘法的逆運算。
-
7⋅8=56 可以得出 56/8=7
-
12⋅2=24 可以得出 24/12=2
我們將使用這個除法的定義來幫助我們理解。注意像「常見」的數學那樣,你不可以把0作為除數。 在F_19 中,我們知道:
3·ᶠ 7 =21 % 19=2 可以得出 2/ᶠ7=3
9·ᶠ 5=45%9=7 可以得出7/ᶠ5=9
這是非常反直覺的,我們通常認為 2/ᶠ 7 或者 7/ᶠ 5是一個分數而不是一個有限域的元素(整數)。此外,有關有限域有一個值得注意的性質:有限域對除法封閉。這意味著,任意兩個有限域的元素,如果除數不是0,則結果一定還是一個有限域的元素。
你可能會問一個問題,如果之前不知道3⋅ 7=2,如何計算2/ᶠ7 呢?這的確是一個好問題,為了回答這個問題,我們將利用Exercise 7 的結果。
以防你沒有得到答案,exercise 7 的答案是 n(p-1) 的計算結果都是1,這對每個質數p 和大於0 的n 都成立。這是一個非常優美的數論知識,即費馬小定理給出的結論。該定理說的是:
當p為質數時,
n(p-1)%p=1
因為我們的運算是在有限域上的,所以這個性質總是成立的。
因為除法是乘法的逆運算,我們得知:
a/b=a·ᶠ(1/b)=a·ᶠ b-1
我們可以把除法化簡為乘法,只要我們能計算出b-1是多少。這部分就是費馬小定理生效的地方了。我們知道
bp-1=1
因為 p 是質數,因此:
b-1=b-1·ᶠ1=b-1·ᶠbp-1=b(p-2)
即:
b-1=b(p-2)
在F19,可以得出b18=1,進一步,對所有b>0,b-1=b17。這表明,我們通過指數運算來計算乘法逆。在F19:
2/7=2⋅7(19-2)=2⋅717=465261027974414%19 = 3
7/5=7⋅5(19-2)=7⋅517=5340576171875%19 = 9
因為指數函數增長非常快,這種計算方法是相對昂貴的。也是這個原因,除法是代價最大的運算了。為了降低計算量,我們可以使用python 中的pow 函數來做指數運算。在python 中,pow(7,17)和717有相同的結果。但是pow 函數有可選的第三變量,能使我們的運算更有效率。具體地說,pow 會使用第三個參數來做模運算。因此,pow(7,17,19)雖然和717%19結果一樣,但是要快很多。因為每一輪乘法,pow 函數都做一次模運算。
1.9. 重新定義指數運算
在結束本章之前,我們還要最後處理一下pow方法,該方法要允許負指數。比如 a3 需要是一個有限域的元素。但是我們目前的代碼並不能處理好這中情況。我們需要的是如下的功能:
>>> from ecc import FieldElement
>>> a = FieldElement(7, 13)
>>> b = FieldElement(8, 13)
>>> print(a**-3==b)
True不幸的是,我們之前定義的__pow__ 方法不能處理負指數,原因是python 內置的pow 函數的第二個參數要求必須為正。幸運的是,我們可以用一些已知的數學知識來解決這個問題。我們從費馬小定理得知: ap-1=1 這表明我們可以對一個元素乘以ap-1,直到我們想要的次數。所以,對於a-3,我們可以這樣計算: a-3=a-3⋅ ap-1=ap-4 這樣我們就可以處理負指數了。下面的代碼是一個簡單的實現:
class FieldElement:
...
def __pow__(self, exponent):
n = exponent
while n < 0:
n += self.prime - 1#1
num = pow(self.num, n, self.prime)#2
return self.__class__(num, self.prime)#1 加到n 為正數為止。
#2 使用內置的pow函數會更有效率。 我們還有更好的做法:我們已經知道如何使負數強行轉化為正數,我們的老朋友 %。因為ap-1=1,我們還可以一並把非常大的指數也化成比較小的指數。這使得pow函數也不會太耗時。
class FieldElement:
...
def __pow__(self, exponent):
n = exponent % (self.prime - 1)#1
num = pow(self.num, n, self.prime)
return self.__class__(num, self.prime-
使指數最後轉為0到p-2 的範圍內。
2. 第二章 橢圓曲線
在本章中,我們將學習橢圓曲線。在第三章我們將結合橢圓曲線和有限域的知識來理解橢圓曲線密碼學。 像有限域一樣,如果之前沒有接觸過,橢圓曲線看上去晦澀難懂。但是實際上其中的數學並不難。大部分你需要知道的橢圓曲線的知識很可能在你學完代數之後學過了。在下面這個章節里,我們會探索這些曲線和它們的應用。
2.1. 定義
橢圓曲線和很多你學習完基礎代數之後見過的方程差不多。y在等號的左邊,而x在等號的另一邊。橢圓曲線有如下的形式:
y2=x3+ax+b
你肯定接觸過其他類似的方程。比如,你可能在基礎代數課上就學習過線性函數:
y=mx+b
你可能還記得我們把m叫做斜率,b叫做截距。你也能畫出如下圖的[figure 2-1]線性函數圖像。
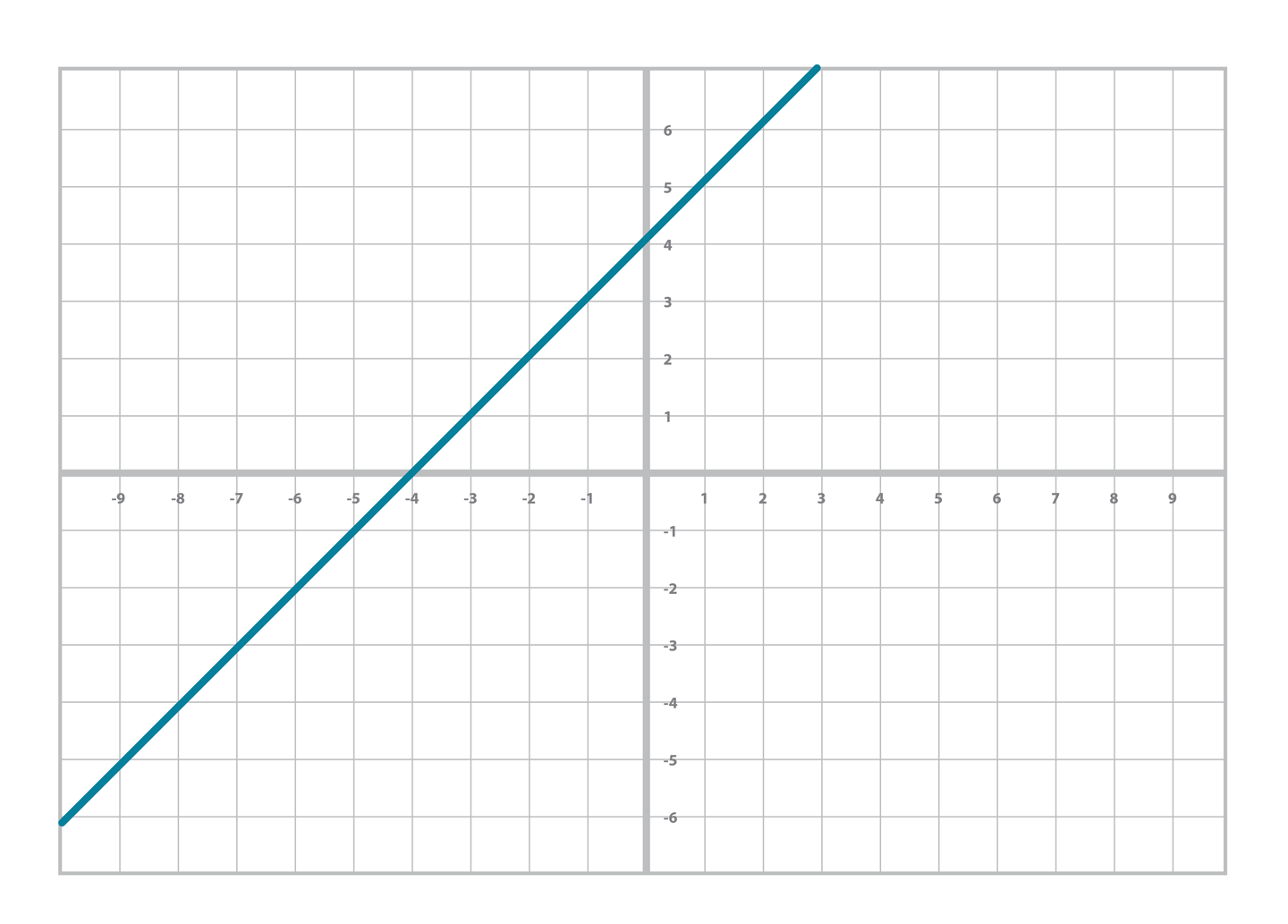
Figure 2-1.一次線性方程
類似的,你可能也熟悉二次函數和它的圖像([Figure 2-2]):
y=ax2+bx+c
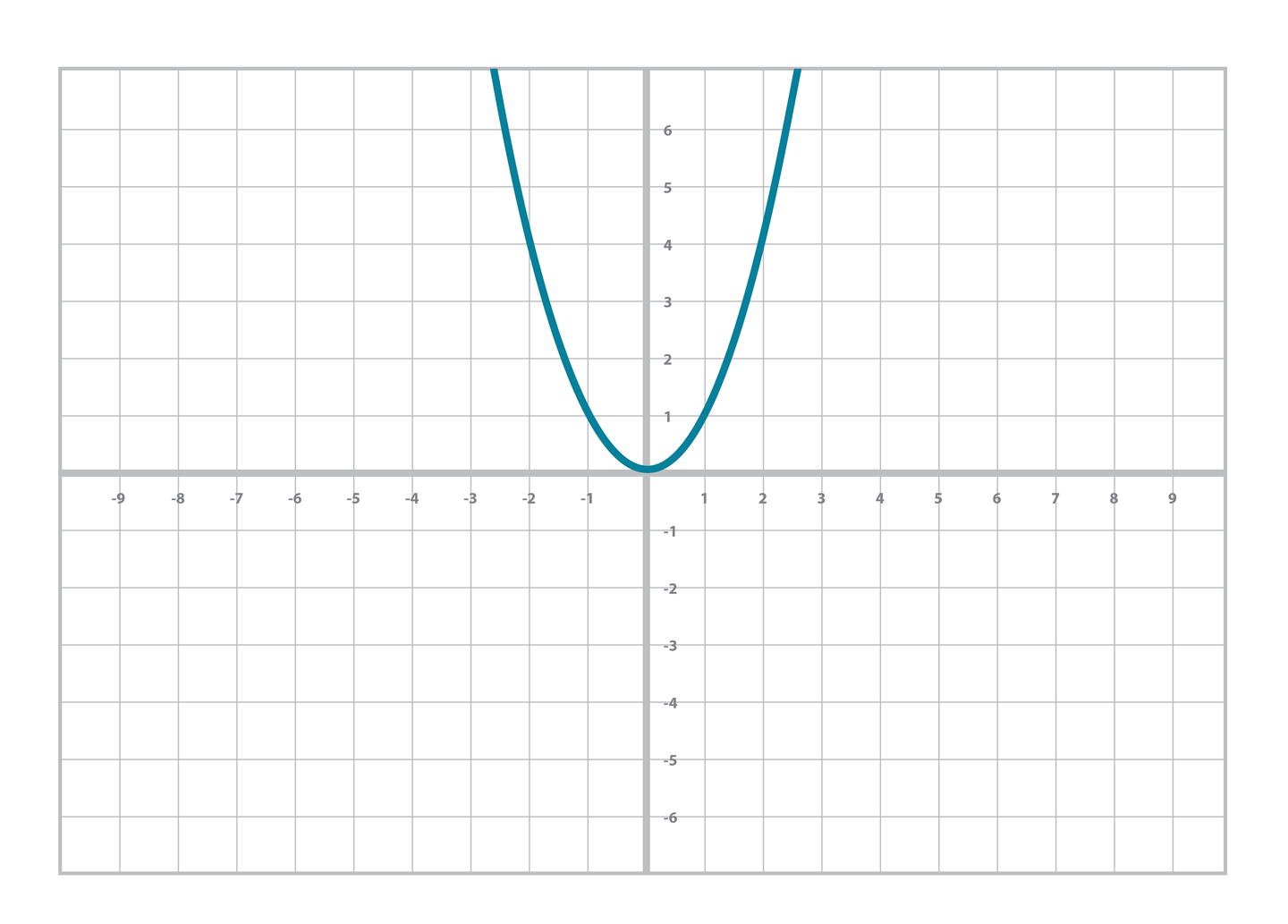
Figure2-2.二次函數
而在學習代數的某些時候,你還接觸過更高階的函數比如三次函數以及它的圖像
y=ax3+bx2+cx+d
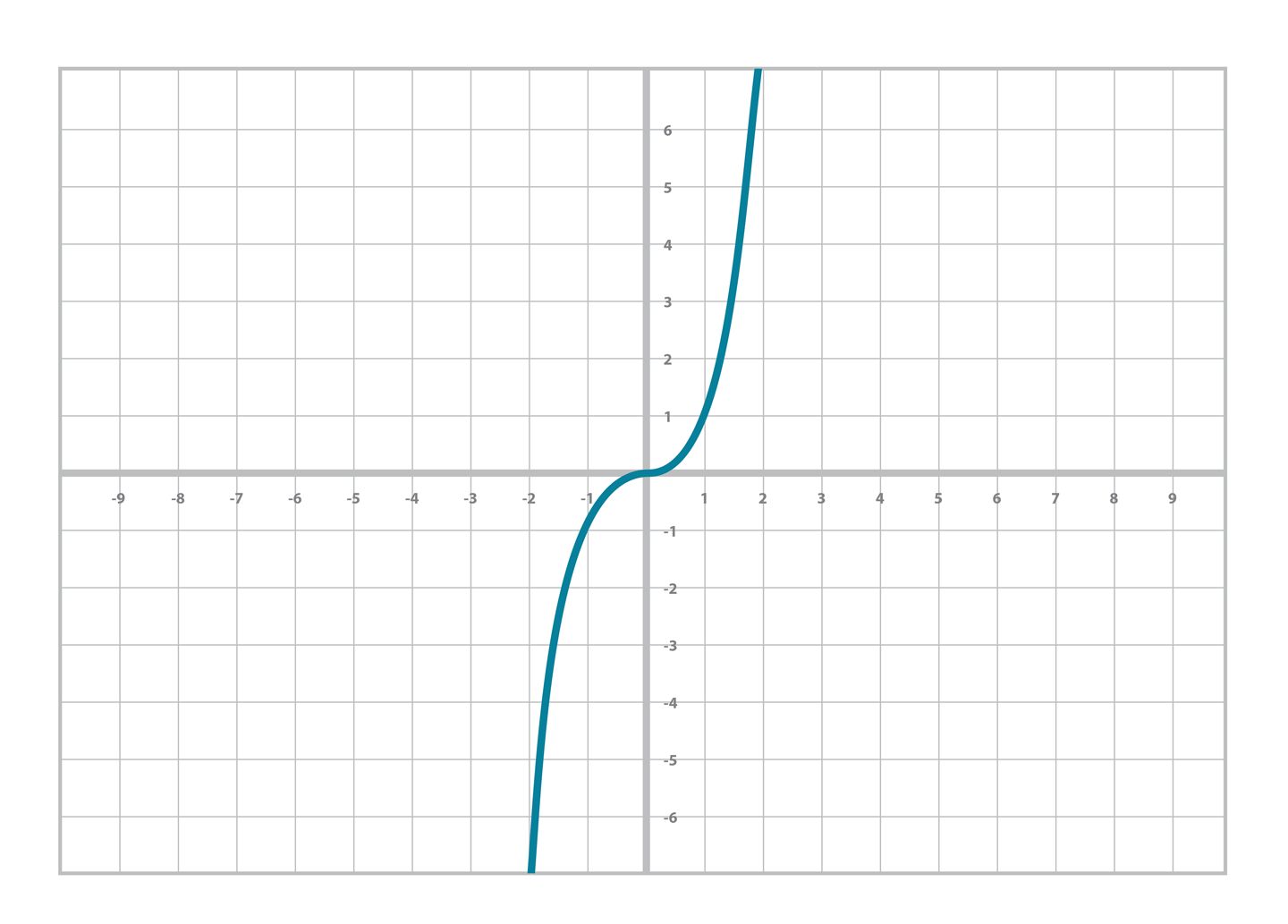
Figure2-3.三次函數
橢圓曲線也沒有和它們有太大的差別:
y2=x3+ax+b
橢圓曲線和三階函數不同的的地方是等號左邊是y2, 這使得函數圖像沿x軸對稱,如圖[Figure 2-4]所示。
Figure 2-4. 連續橢圓曲線
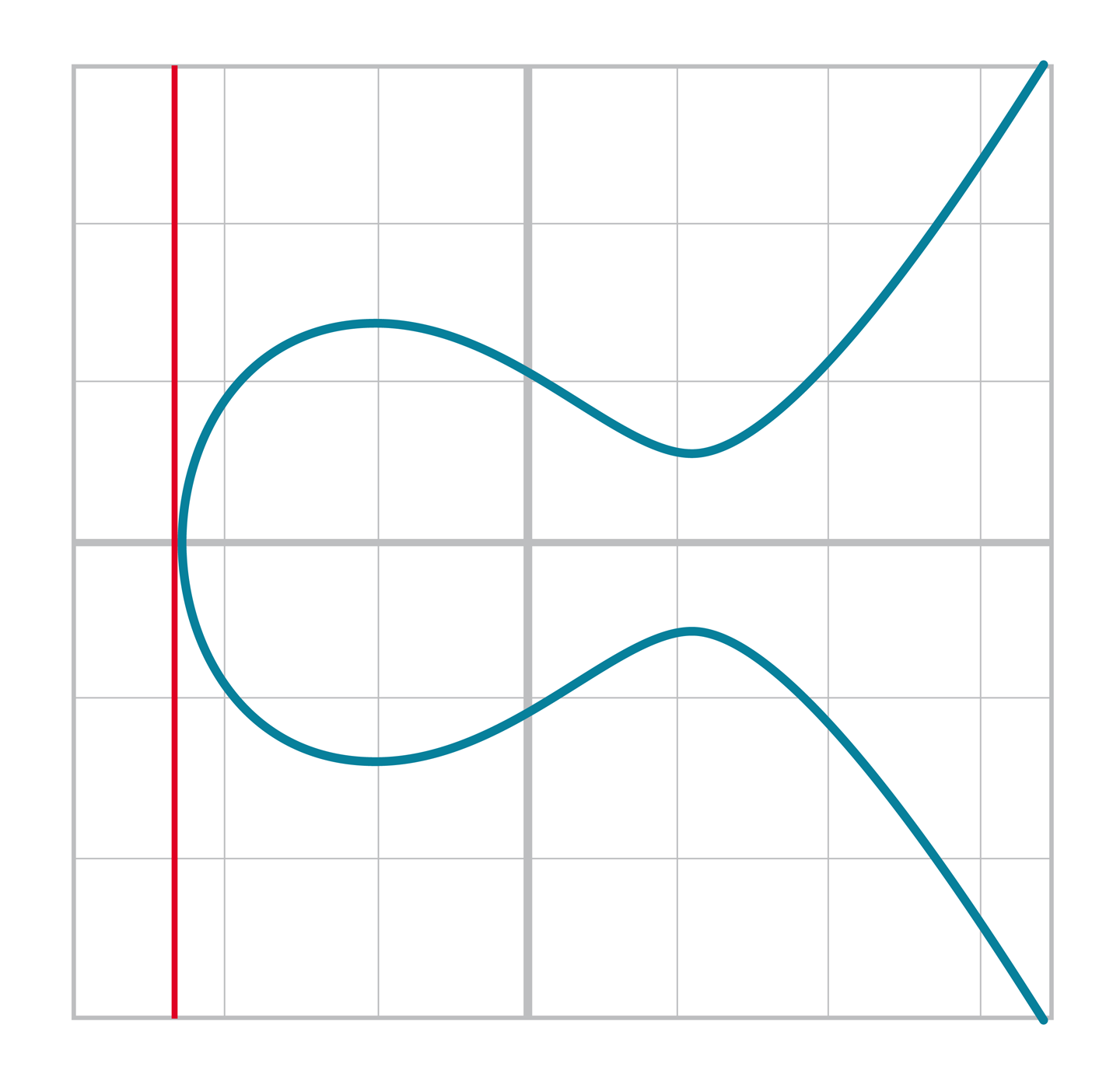
因為橢圓曲線的等號左邊是y2,所以它也不像三次函數陡峭。此外,橢圓曲線也可能是不相接(disjoint)的,如圖[Figure 2-5].
Figure2-5.不相接的橢圓曲線
可以想象有一個三次函數([Figure 2-6]),我們對x軸以上的部分拉伸([Figure 2-7]),然後再使之關於x軸對稱([Figure 2-8])。
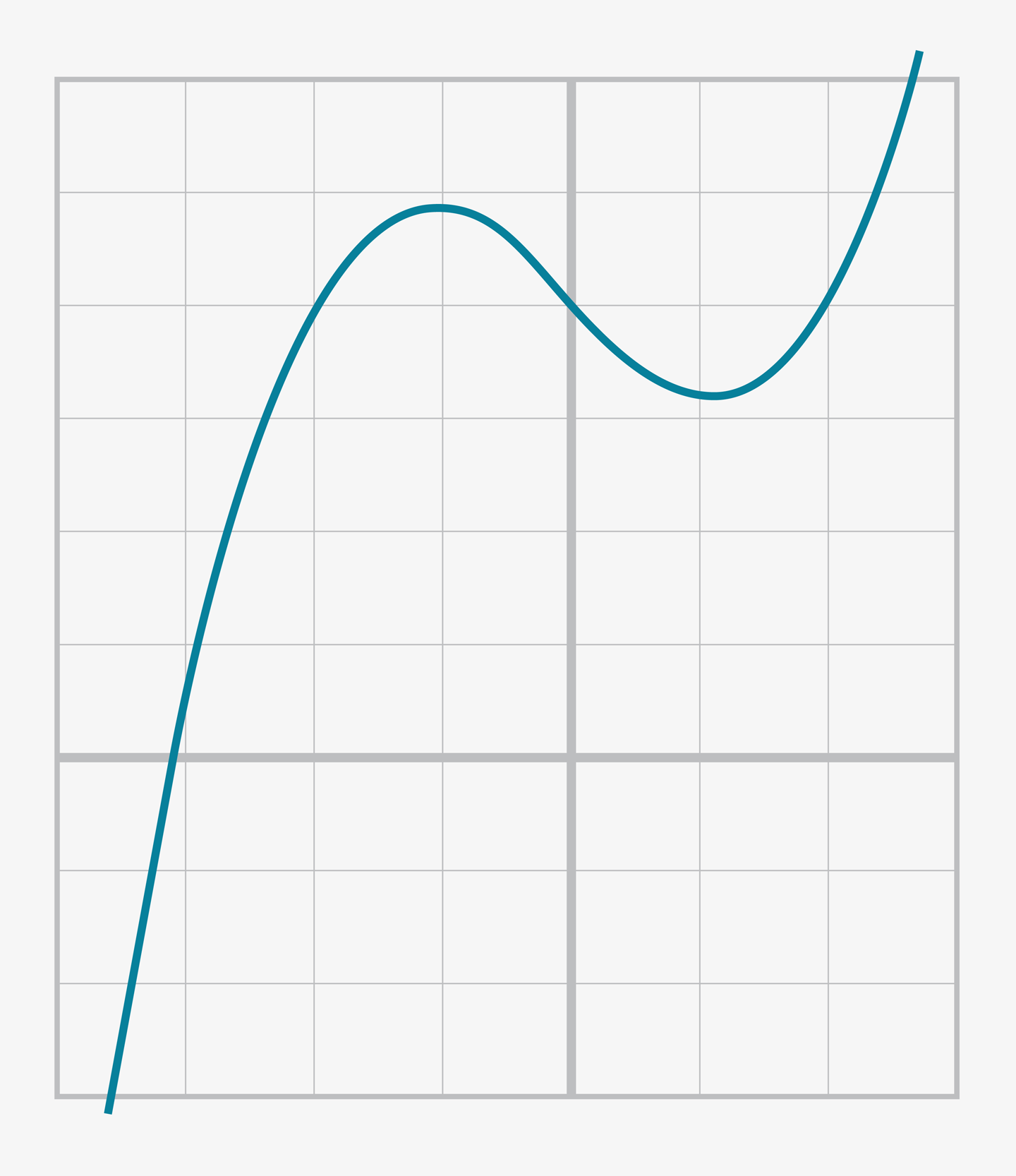
Figure 2-6. 第一步:一個三次函數
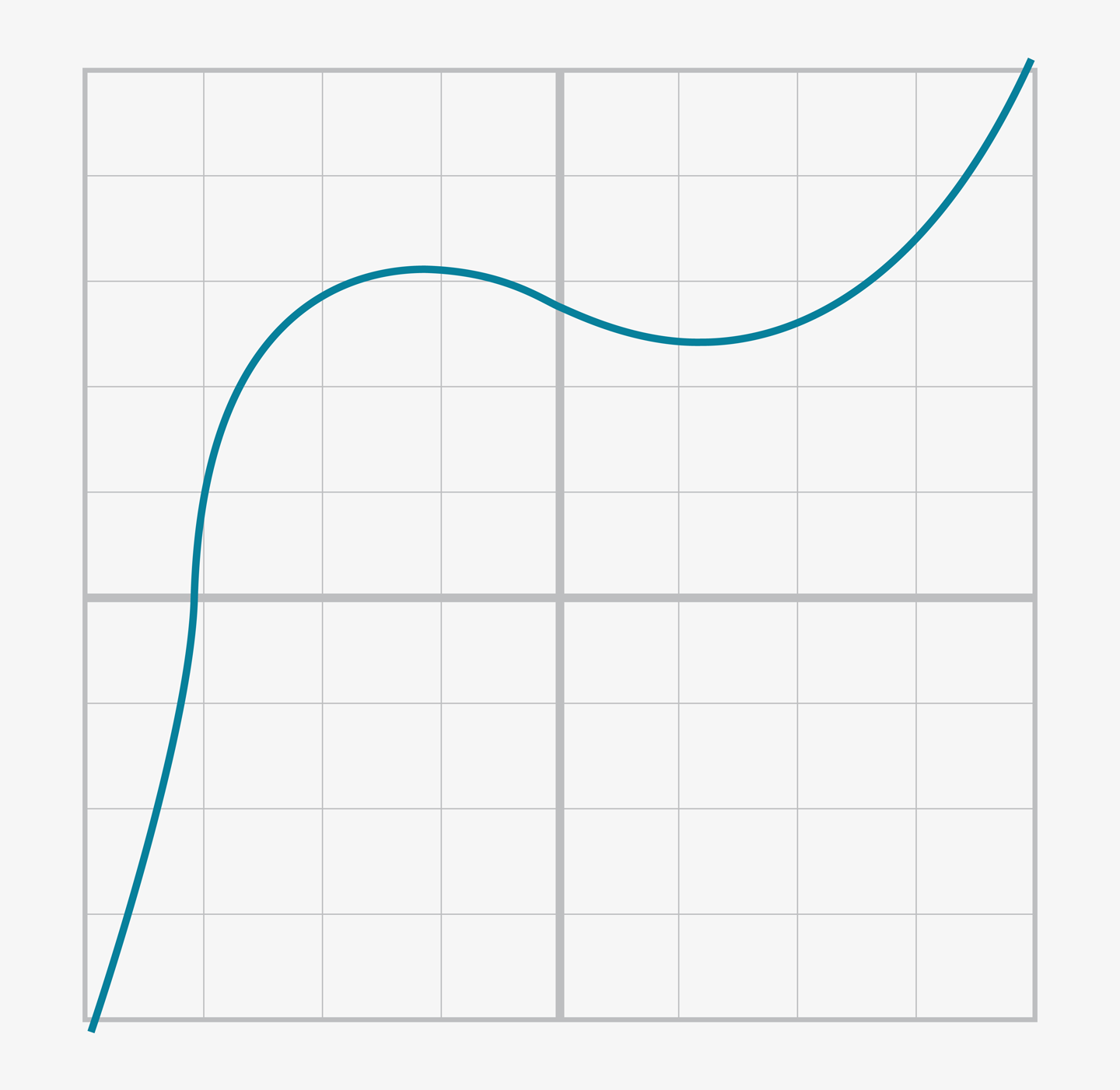
Figure 2-7. 第二步:拉伸三次函數
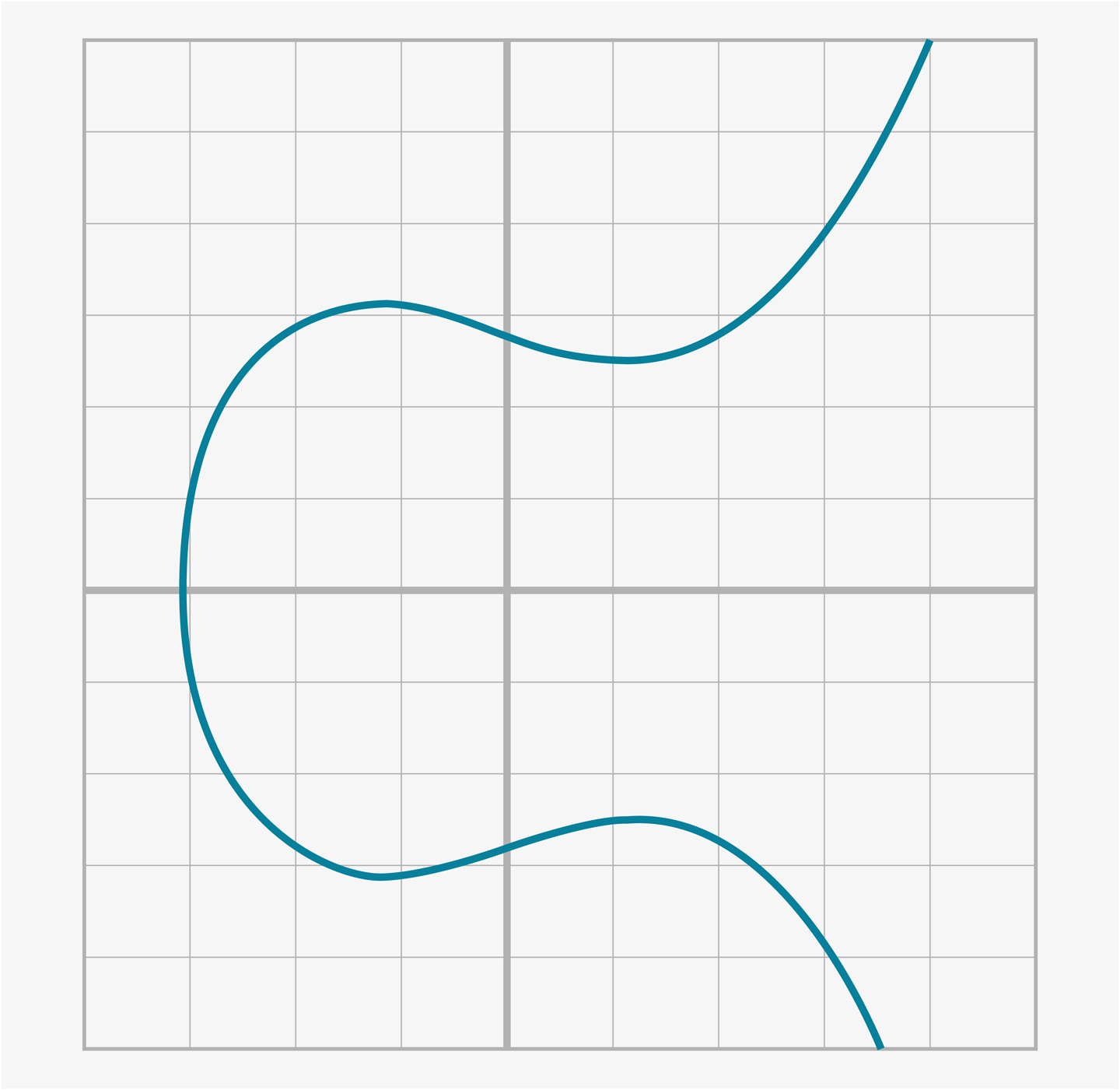
Figure 2-8. 第三步:對x軸以上部分反轉對稱
比如,比特幣使用的橢圓曲線被稱為 secp256k1, 使用下面的方程:
y2=x3+7
橢圓曲線的標準形式為y2=x3+ax+b,即這個比特幣的橢圓曲線的常數為 a=0,b=7,如圖([Figure2-9]):
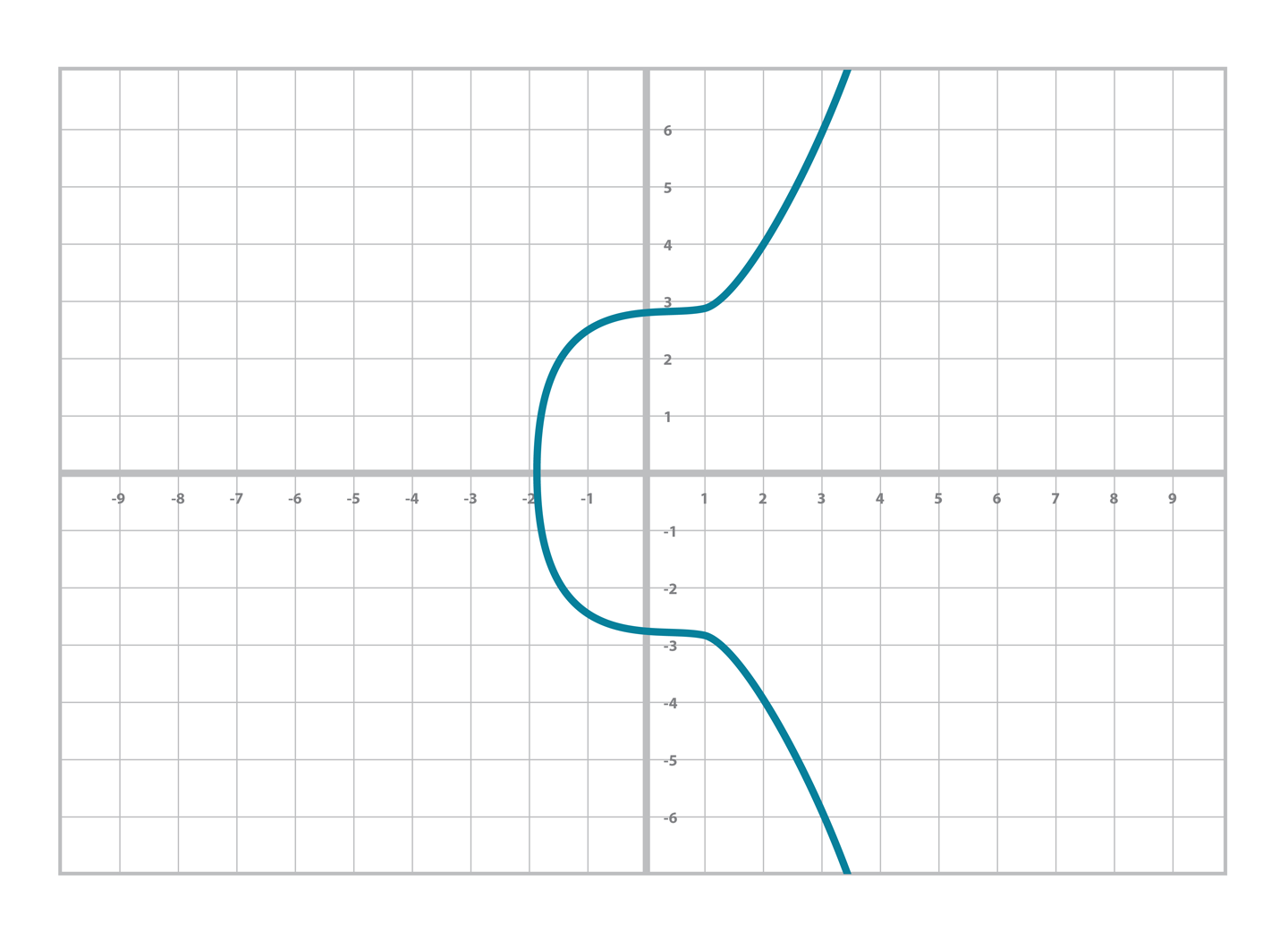
Figure 2-9. secp256k1 曲線
譯注:數學上作者對橢圓曲線的定義是不完備的,橢圓曲線要求曲線是非奇異的,即不存在尖點,自相交,和孤立點的情況(作者在上文給出了孤立點的例子)。a,b需要滿足判別式Delta=-16(4a3+27b2)≠ 0的才是橢圓曲線。
2.2. 使用Python 編寫橢圓曲線
出於一些我們之後才會討論的原因,我們其實並不關心橢圓曲線本身,而是更關心橢圓曲線上的特定的點。比如在橢圓曲線 y2=x3+5x+7, 我們關心的是坐標點 (-1,1)。因此我們要先構建 Point 類來代表橢圓曲線上的點。橢圓曲線的形式為 y2=x3+ax+b ,所以可以用a和b 來定義橢圓曲線:
class Point:
def __init__(self, x, y, a, b):
self.a = a
self.b = b
self.x = x
self.y = y
if self.y**2 != self.x**3 + a * x + b:#1
raise ValueError('({}, {}) is not on the curve'.format(x, y))
def __eq__(self, other):#2
return self.x == other.x and self.y == other.y \
and self.a == other.a and self.b == other.b#1 我們要檢查某個Point是否在橢圓曲線上。
#2 兩個Point的實例當且僅當它們在相同的曲線以及擁有相同的坐標時才相等
至此,我們可以創建 Point 對象了。如果Point不在橢圓曲線上,則會報錯。
>>> from ecc import Point
>>> p1 = Point(-1, -1, 5, 7)
>>> p2 = Point(-1, -2, 5, 7)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "ecc.py", line 143, in __init__
raise ValueError('({}, {}) is not on the curve'.format(self.x, self.y))
ValueError: (-1, -2) is not on the curve也就是如果點不在曲線上,__init__方法會拋出異常。
2.3. 點的加法
橢圓曲線因其點加法運算(point addition)而被廣泛使用。點加法指處理兩個某一橢圓曲線上的點的運算符,而運算後得到的第三個點也仍然在該橢圓曲線上。這個運算被稱為點加法是因為和數學上的加法有許多直覺上的相似性。比如點加法有交換律,這表明,點A加上點B和點B加上點A是一樣的。
我們採用如下的方式定義點加法。我們發現對於所有的橢圓曲線而言,除了一些特例以外,一條直線只能與之相交於一個點([Figure 2-10])或者相交於三個點([Figure 2-11])。
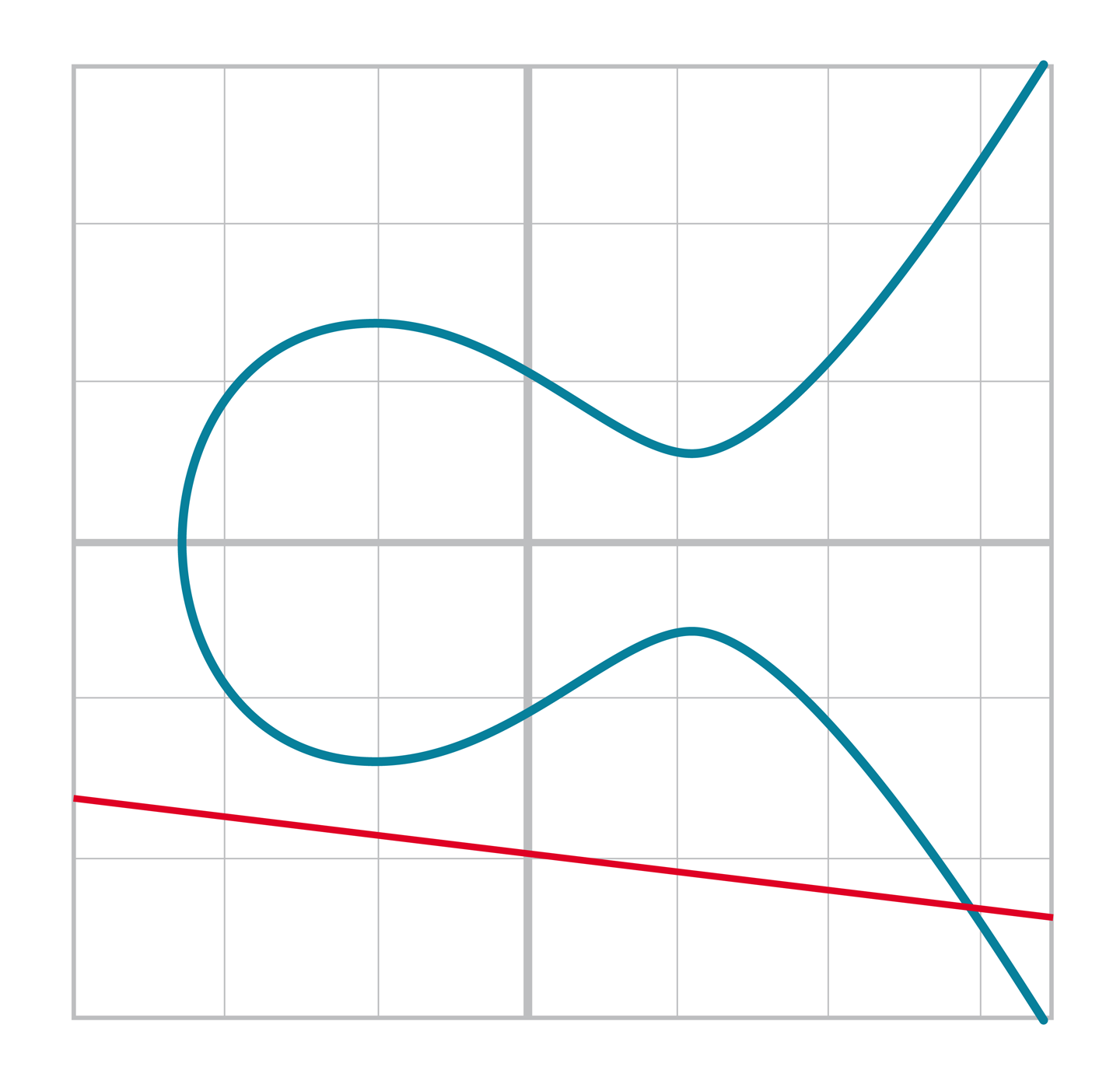
Figure 2-10. 直線與曲線相交於一點
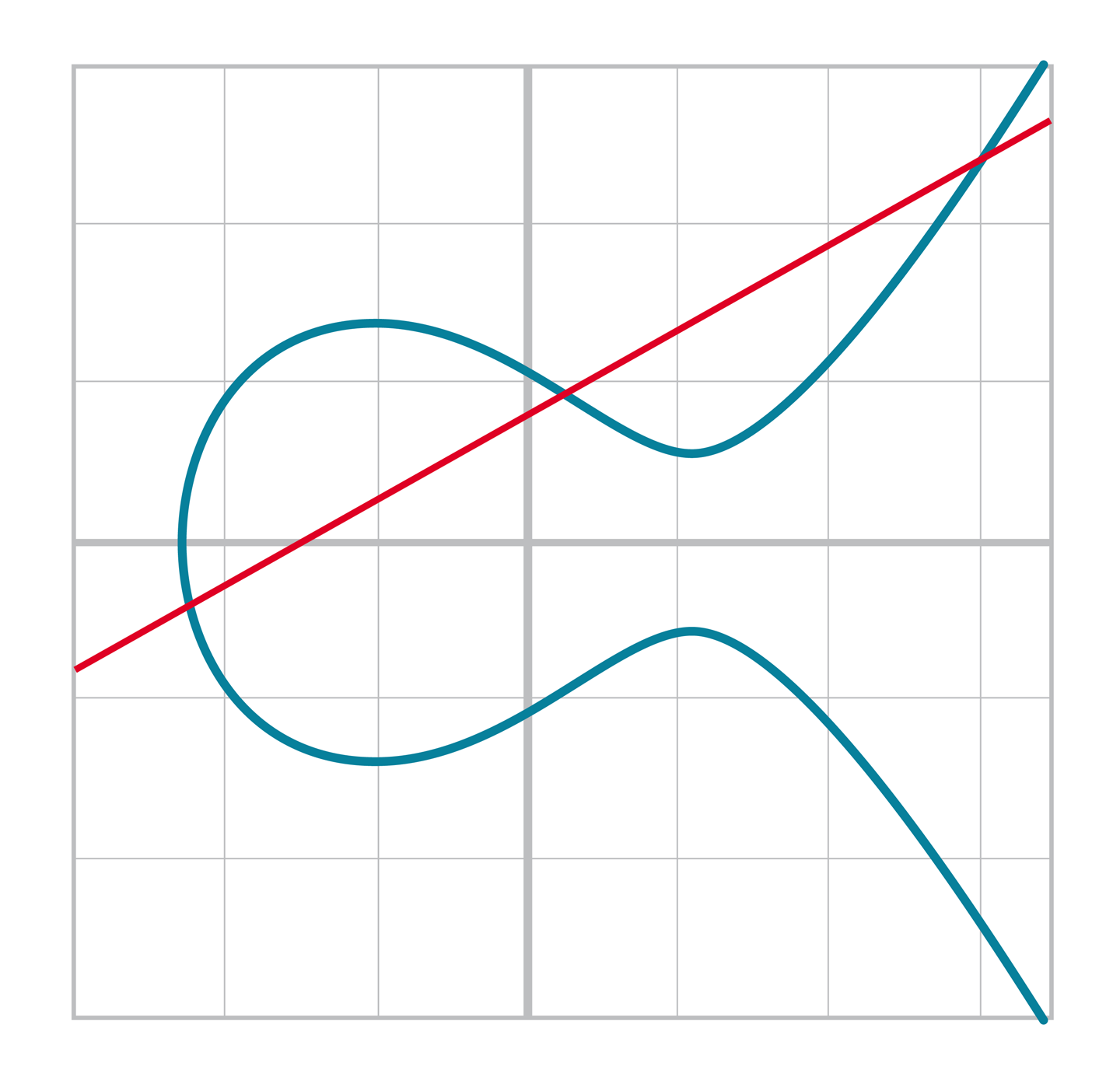
Figure 2-11. 直線與曲線有三個交點
下面兩種情況只有兩個交點,一種是垂直於x軸的直線([Figure 2-12])。另一種情況是直線與曲線相切([Figure 2-11])。
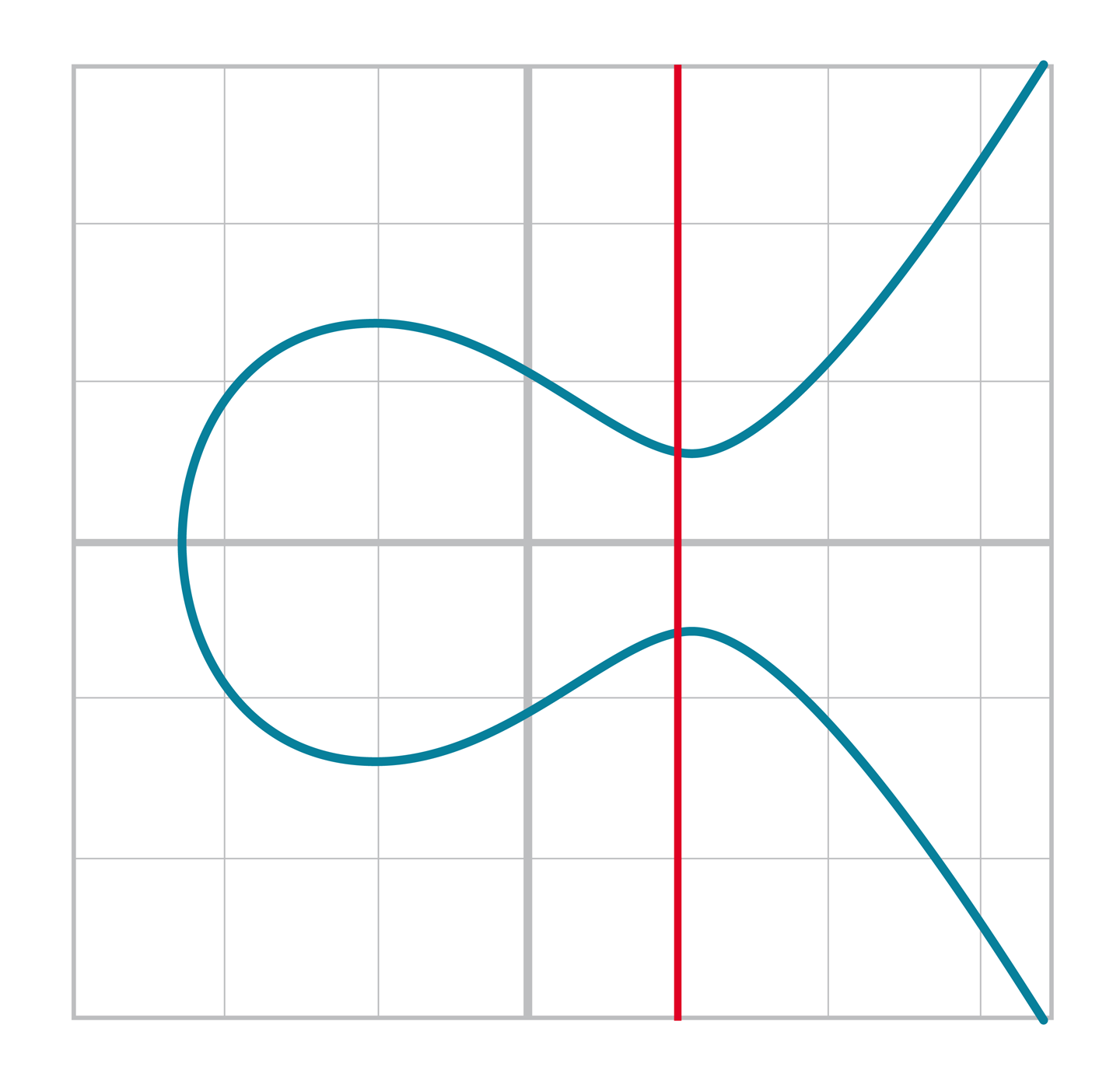
Figure 2-12.因為直線垂直,直線和橢圓曲線兩個交點
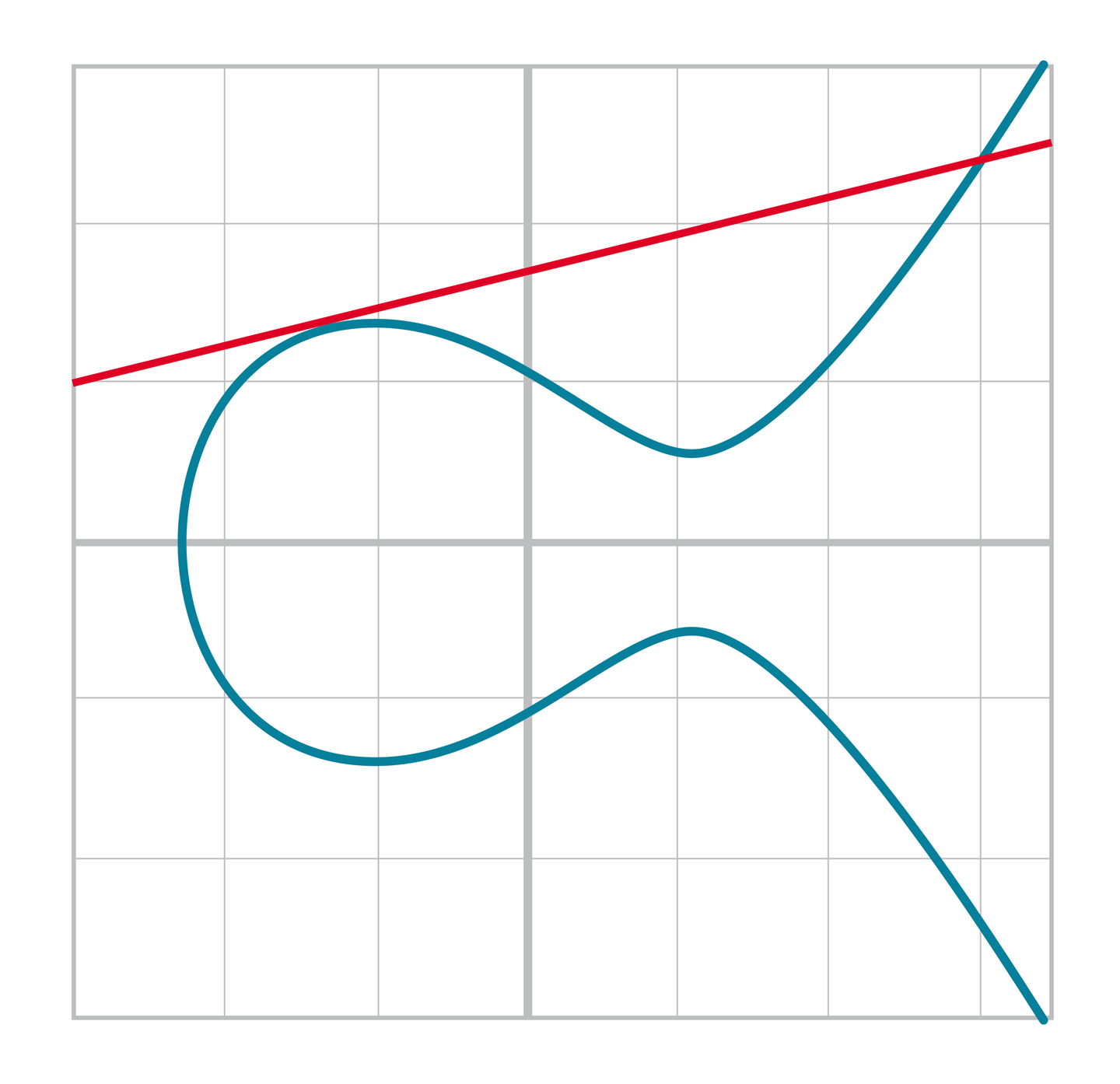
Figure 2-13.因為直線相切,直線和橢圓曲線有兩個交點
我們會在之後討論這兩種情況。
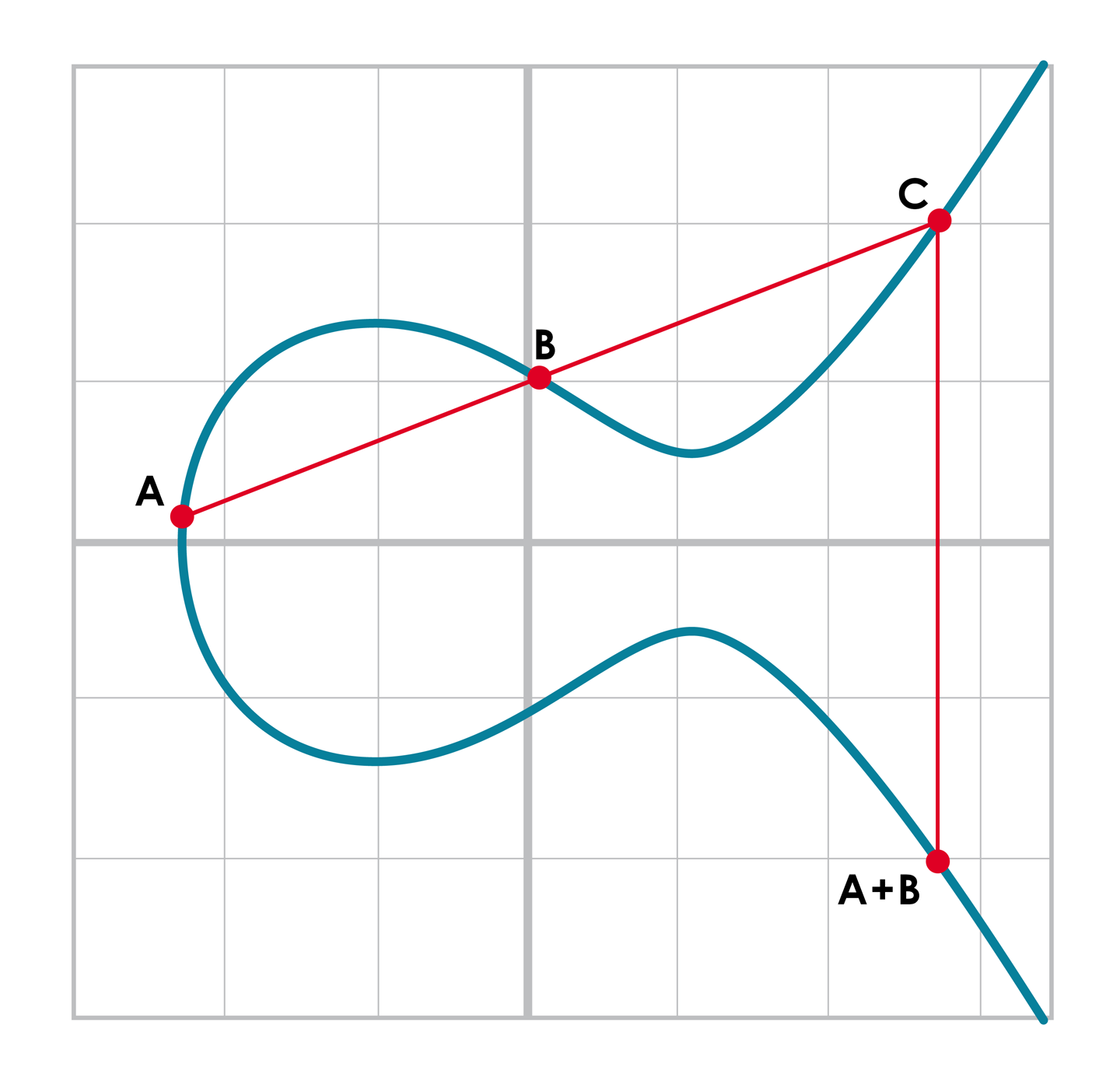
我們可以通過直線與橢圓曲線有一個或者三個交點的性質來定義點加法。任意取橢圓曲線上兩個點,因為兩個點可以確定一條直線,該直線則一定會與橢圓曲線相交於第三個點,我們對直線與橢圓曲線的第三個交點做x軸的對稱,就能得到我們定義的點加法的運算結果。
即對於橢圓曲線上的任意兩個點P1=(x1,x2) 和 P2=(x2,y2) 我們這樣計算P1+P2:
-
繪制經過P1,P2的直線,找到其與橢圓曲線的第三個交點。
-
對該點做關於x軸的對稱點。
可以參考下面的[Figure 2-14]:
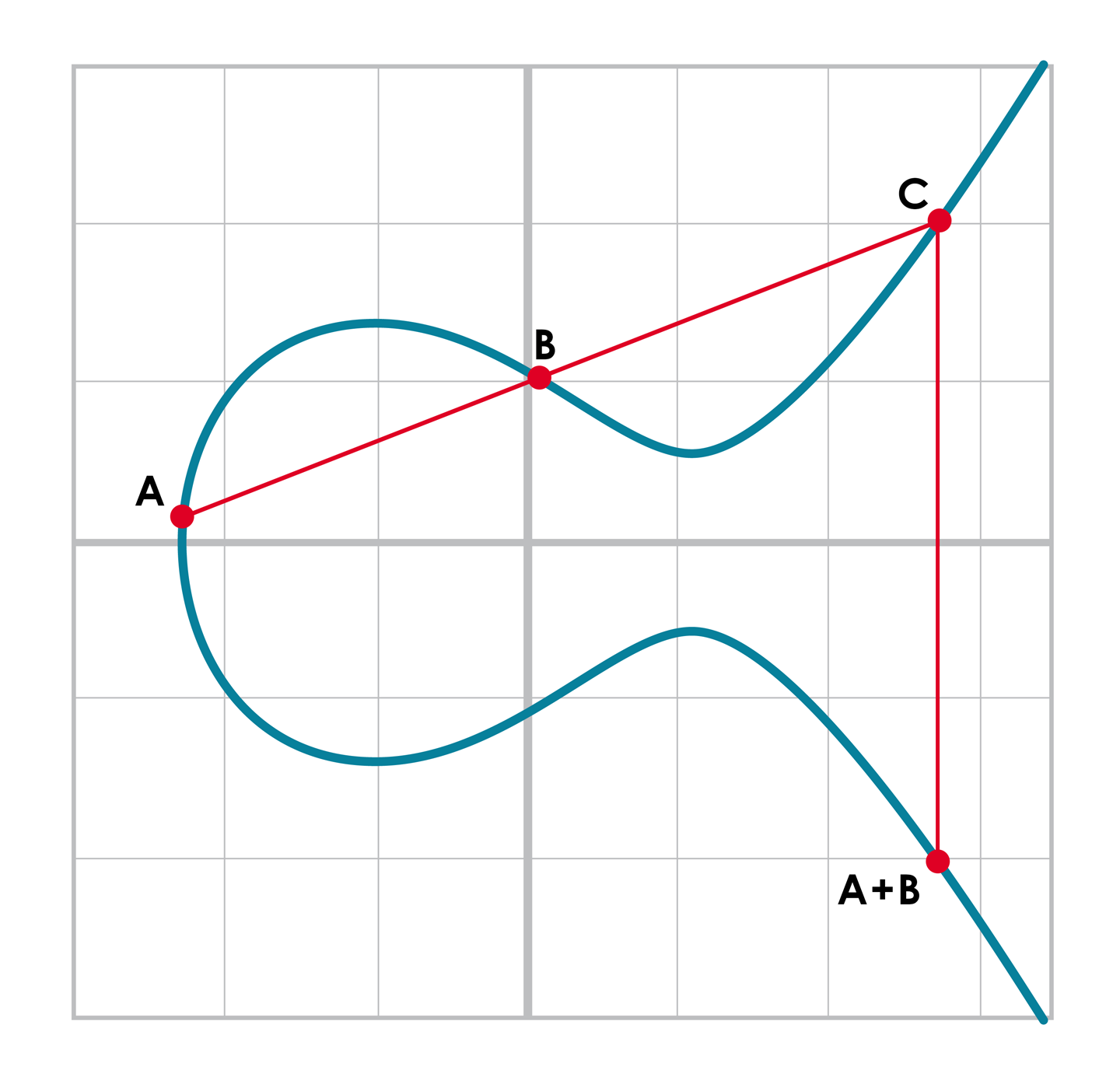
Figure 2-14.點加法
首先,繪制經過要相加的兩個點(A 和 B)的直線。與橢圓曲線的第三個交點為C。再對點C 做關於x 軸的對稱點,即為A+B的結果。
我們將要利用的一個特性是點加法的結果很難預測。儘管根據公式很容易的就獲得了點加法的結果,但是直覺上一個點加法的和,在給定任意的兩個點後,可能是橢圓曲線上任何一個點。我們回到[Figure2-14],A+B的結果在兩個點右邊,A+C 在A和C 之間的x軸上。 B+C 的和在兩個點的左邊。 在數學術語里,我們稱點加法為非線性的(nonlinear)。
2.4. 點加法的數學
點加法滿足一些和加法一致的性質,比如:
-
加法恆等元
-
交換律
-
結合律
-
可逆性
加法恆等元 指存在0,即存在點 I,和任意點A 相加後仍然為A:
I+A =A
我們把這個點稱之為無窮遠點。(之後會討論原因) 這也與可逆性相關。對於任意點 A,存在另一個點-A使得其和為加法恆等元。即:
A+(-A)=I
如圖[Figure 2-15],兩個交點關於x軸對稱
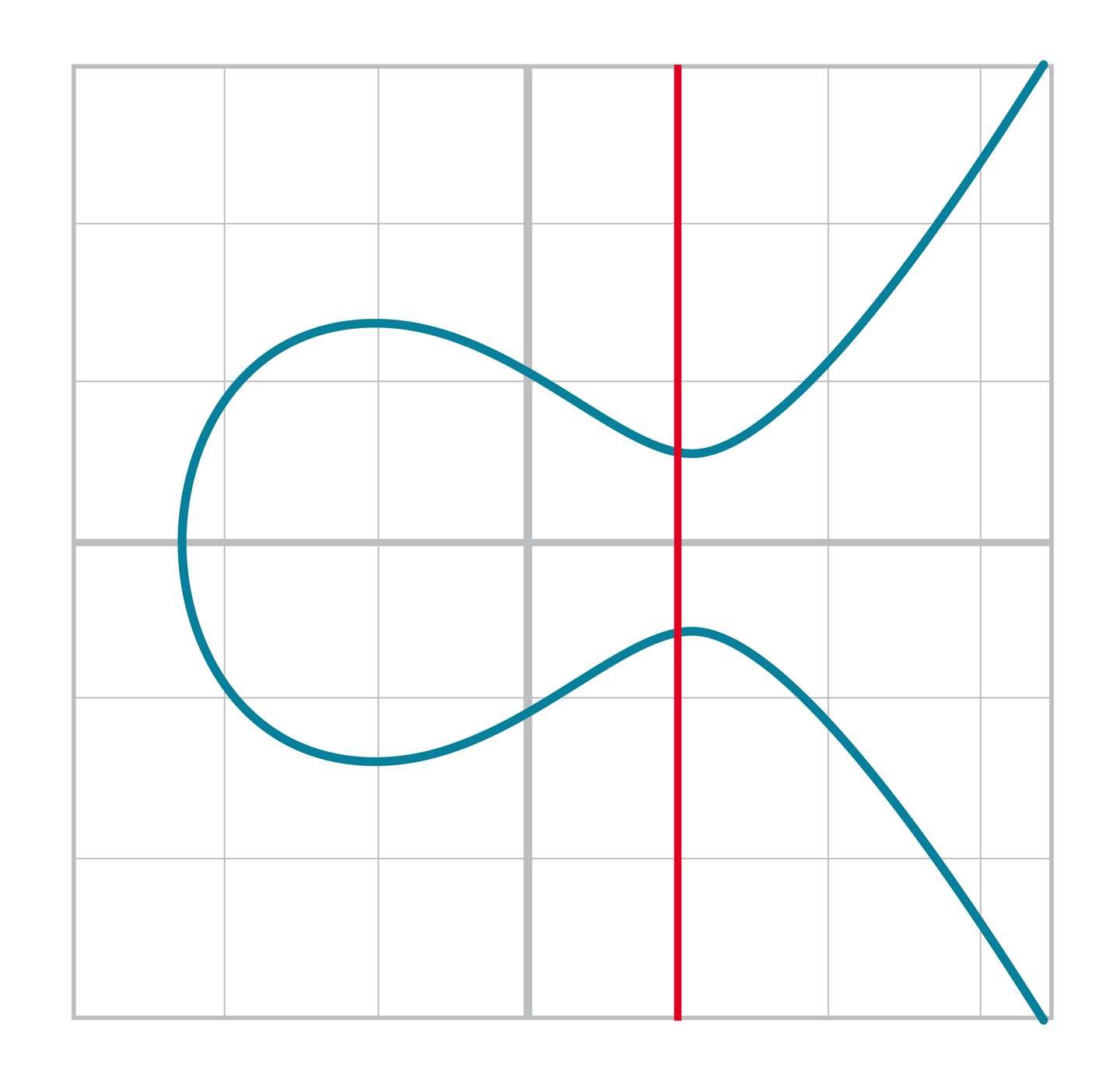
Figure 2-15. 垂直相交
這也是我們為什麼稱之為無窮遠點。我們在橢圓曲線上還有額外的一個點,這個點使垂直於x的直線與橢圓曲線第三次相交。
交換律 指 A+B=B+A,這個性質的驗證也非常直觀,因為直線經過兩個點與橢圓曲線相交於第三個點,和直線經過的兩個點的順序沒有關係。
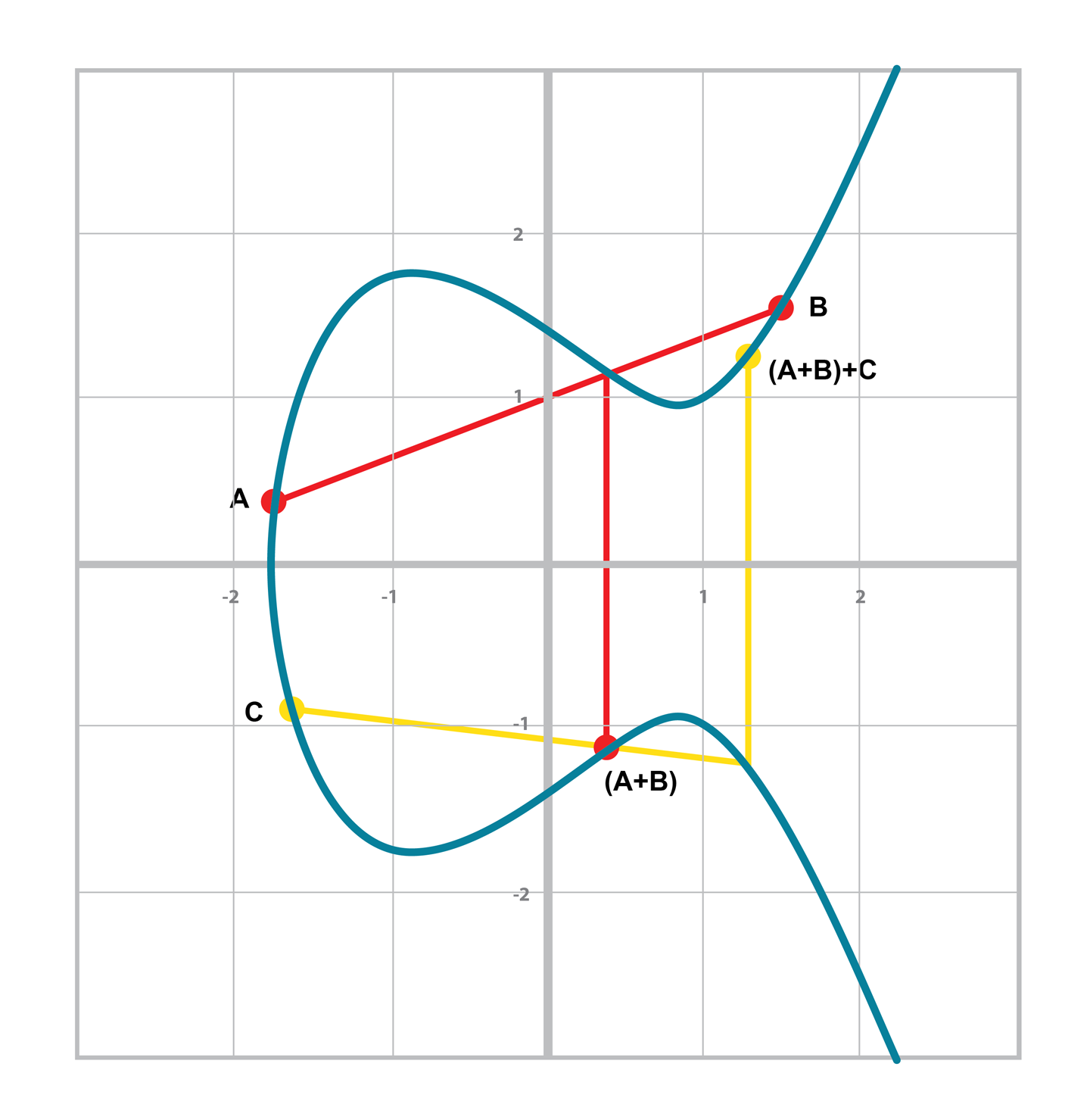
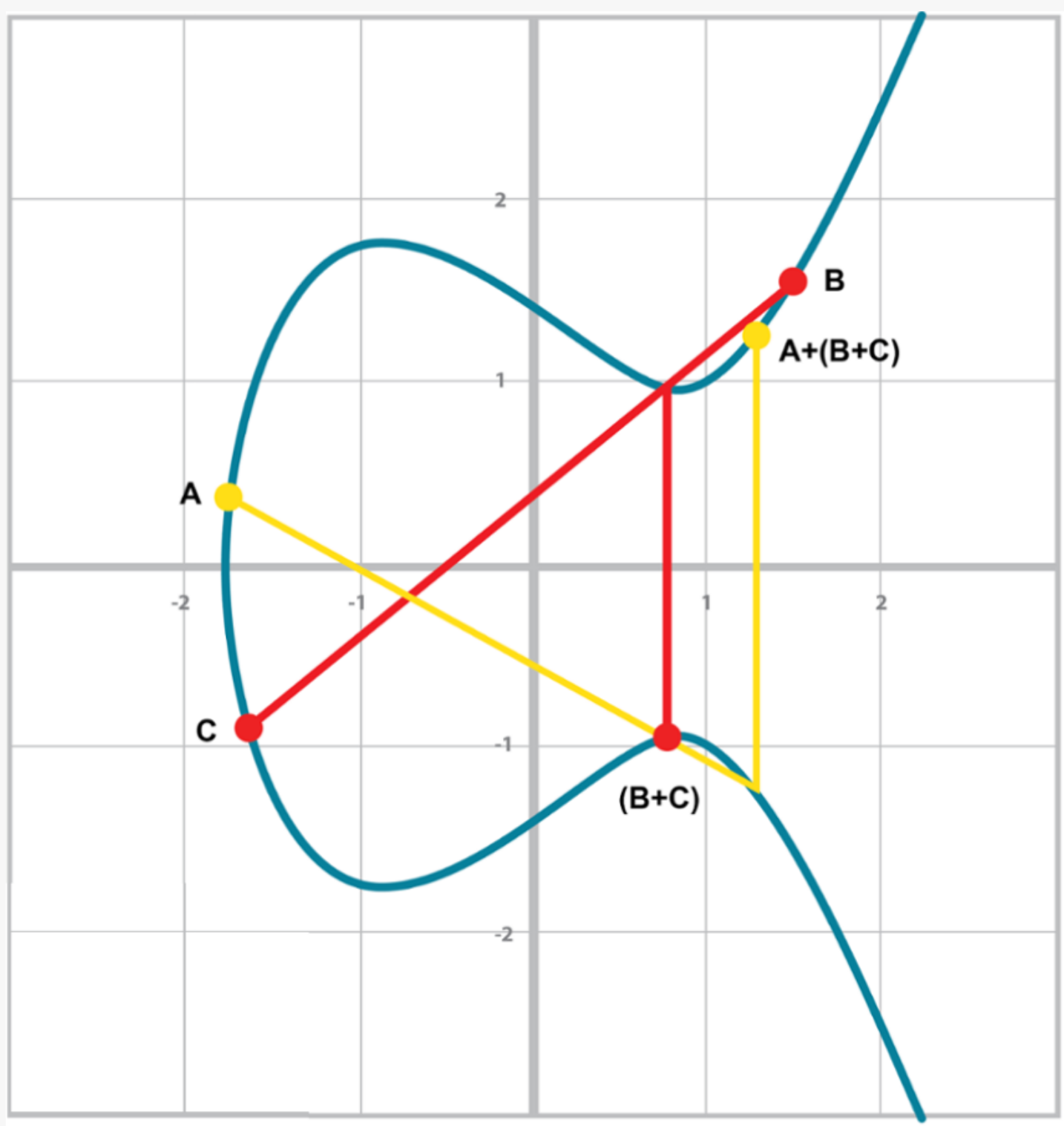
結合律 指 (A+B)C=A(B+C), 因為加法的最後一步要關於x軸做對稱,所以這個性質並不直觀。如圖 [Figure 2-16] 和 [Figure 2-17]。
可以看到在圖 [Figure 2-16]和 [Figure 2-17]中 ,兩者最終的計算結果是一致的。這表明,我們可以有理由相信 (A+B)C=A(B+C)的性質。儘管這不是對點加法結合律的嚴格數學證明,如圖可視化的過程直覺上告訴我們這是正確的。
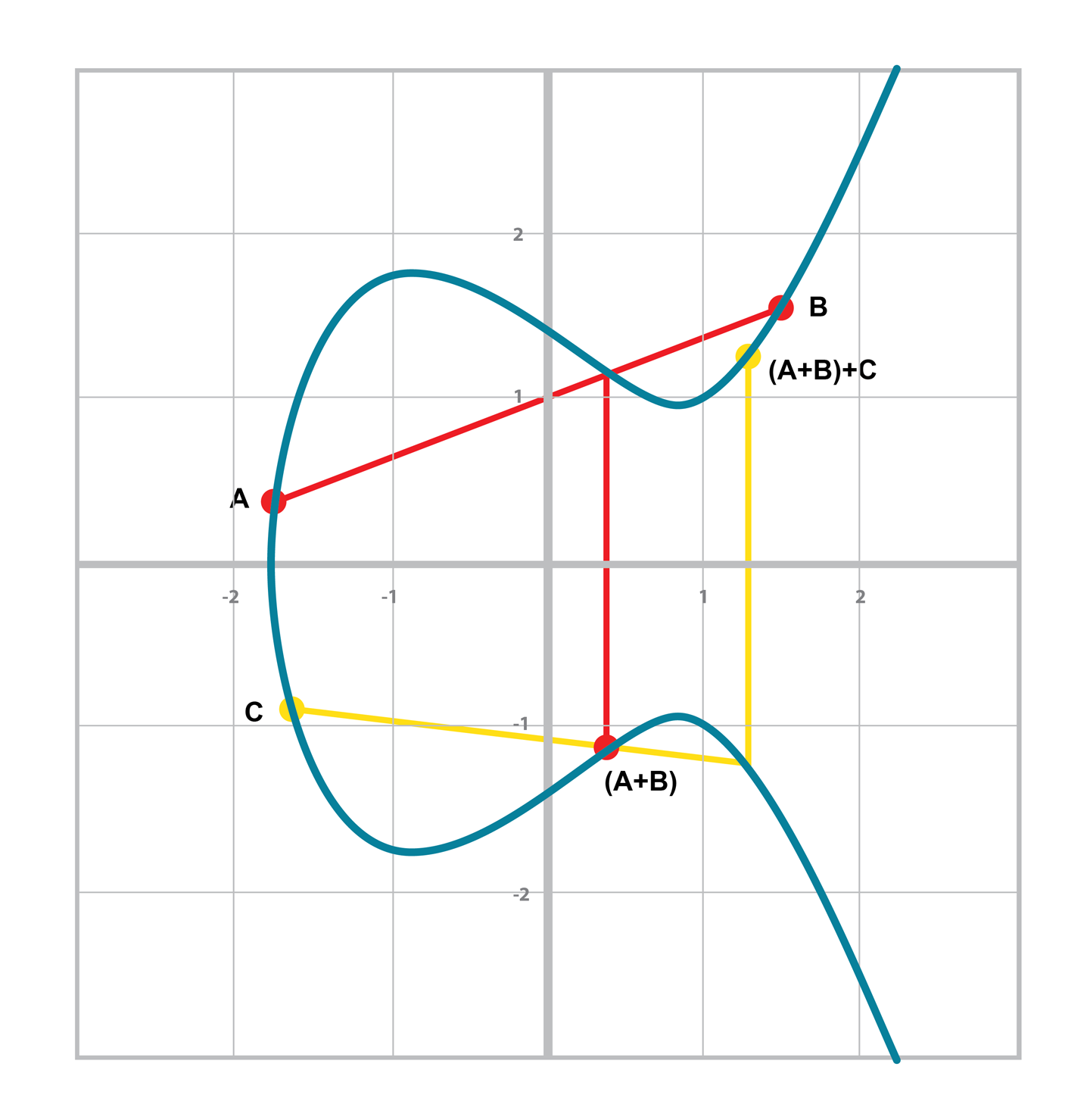
Figure 2-16. (A+B)+C
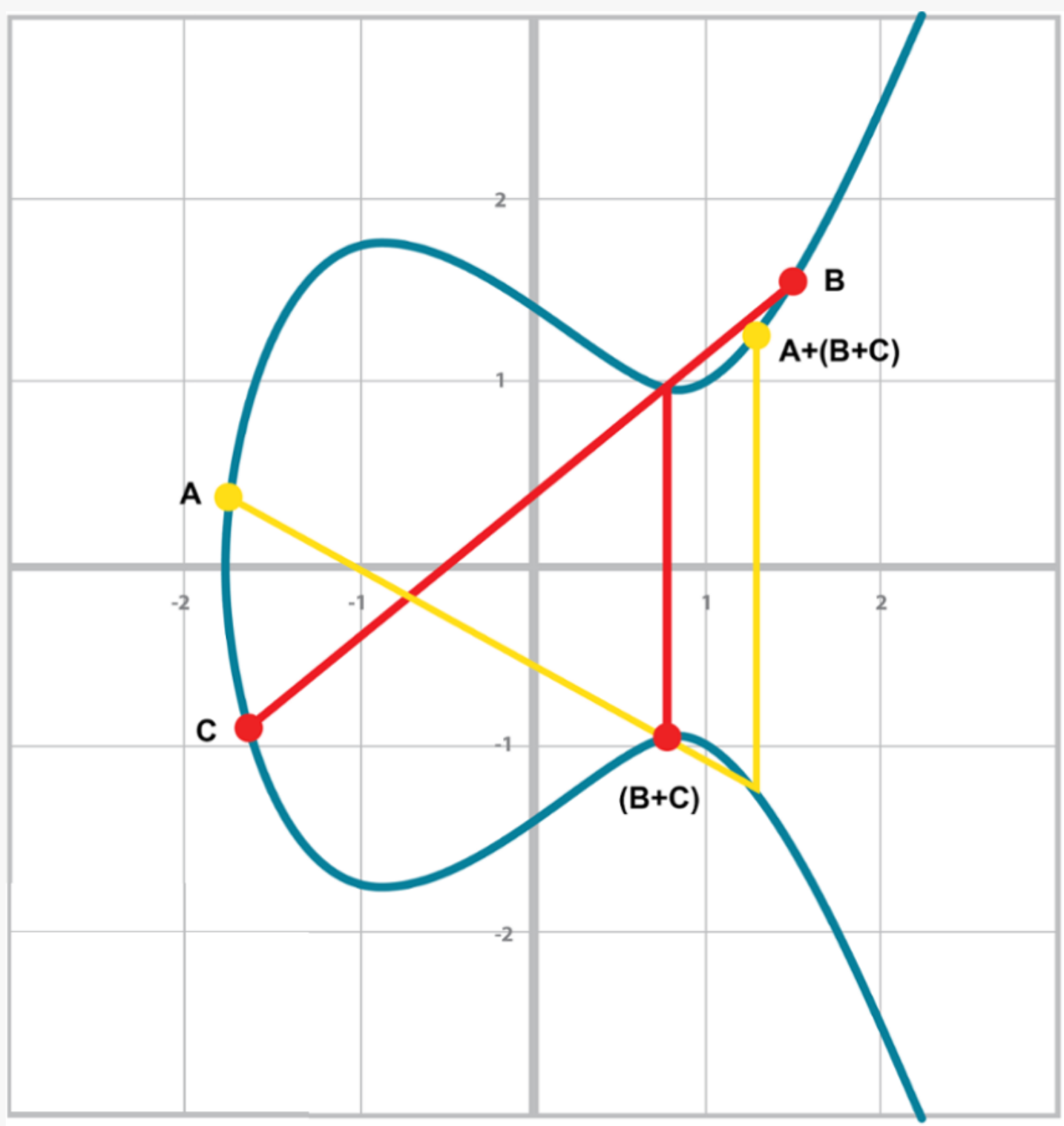
Figure 2-17. A+(B+C)
為了方便代碼實現點加法,我們將這個過程分解成三種情況:
-
兩個點所在直線與x軸垂直或者其中一個點為無窮遠點
-
兩個點所在直線不與x軸垂直,且為兩個不相同的點
-
兩個點是相同的
2.5. 實現點加法
首先我們實現恆等元點,即無窮遠點。因為我們不能在python中直接使用表示’無窮’的值。我們使用 None 來代替,我們期待的運行效果為:
>>> from ecc import Point
>>> p1 = Point(-1, -1, 5, 7)
>>> p2 = Point(-1, 1, 5, 7)
>>> inf = Point(None, None, 5, 7)
>>> print(p1 + inf)
Point(-1,-1)_5_7
>>> print(inf + p2)
Point(-1,1)_5_7
>>> print(p1 + p2)
Point(infinity)為了實現這一功能,我們需要做兩件事情。第一步是修改原有的__init__來使無窮遠點跳過一個點是否在橢圓曲線函數上的檢查。 第二步,如我們在FieldElement中做的那樣,重載加法運算符 __add__:
class Point:
def __init__(self, x, y, a, b): self.a = a
self.b = b
self.x = x
self.y = y
if self.x is None and self.y is None:#1
return
if self.y**2 != self.x**3 + a * x + b:
raise ValueError('({}, {}) is not on the curve'.format(x, y))
def __add__(self, other):#2
if self.a != other.a or self.b != other.b:
raise TypeError('Points {}, {} are not on the same curve'.format (self, other))
if self.x is None: #3
return other
if other.x is None: #4
return self-
如果x軸和y軸的坐標都是None,表明該點為無窮遠點。
-
此處重載加法運算符。
-
self.x 的值為None,則self點為無窮遠點,即加法恆等元。因此我們返回other點作為加法的結果。
-
other.x 的值為None,則other點為無窮遠點,即加法恆等元。因此我們返回self點作為加法的結果。
2.6. 當x1≠ x2時的點加法
之前我們已經處理的相同x坐標時的點加法。接下來我們處理不同x坐標的加法。當兩點的x 坐標不相同時,我們可以使用簡單的計算公式來獲得結果。為了方便理解,我們首先計算兩點確定的直線的斜率。我們可以使用基礎代數的公式來計算: P1=(x1,y1), P2=(x2,y2), P3=(x3,y3) P1+P2=P3 s=(y2-y1)/(x2-x1)
我們可以利用斜率 s 計算x3 ,只要我們知道x3,就能計算y3,P3 的推導公式如下: x3=s2-x1-x2 y3=s(x1-x3)-y1 注意y3 是直線第三個交點的關於x軸的對稱點。
2.7. 實現 x1 ≠ x2時的點加法
要在代碼庫加入這個計算,就要修改add,來處理x1≠ x2的情況。我們有下面的公式:
s=(y2-y1)/(x2-x1) x3=s2-x1-x2 y3=s(x1-x3)-y1
在最後,我們返回一個Point 類的實例。使用__self__.__class__ 方便之後子類的繼承。
2.8. 當P1=P2時的點加法
當x軸坐標相等,y軸坐標不相等,如我們之前討論過的那樣,兩個點關於x 軸對稱,這意味著:
P1=-P2 或者P1+P2=I
我們在Exercise 3 中已經解決了這個問題。 但如果P1=P2時該如何計算呢?幾何上,我們應該做P1的切線,並找到其與橢圓曲線的另一個交點。情況如圖[Figure 2-18]所示。
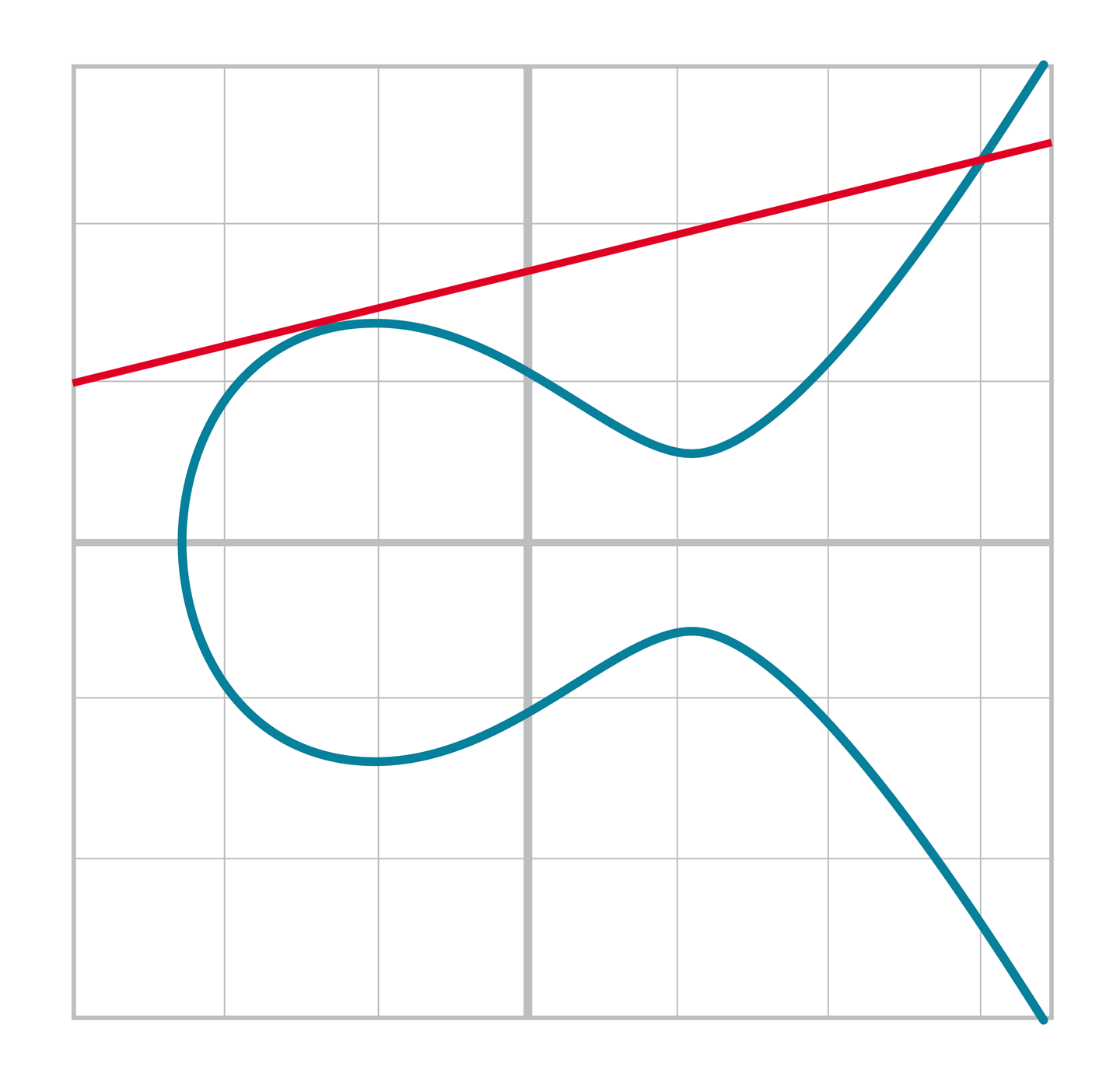
Figure 2-18. 直線與橢圓曲線相切
同樣的,我們要先計算出經過點的切線的斜率:
P1=(x1,y1), P3=(x3,y3) P1+P2=P3 s=(3x12+a)/(2y1)
注意,上面的a為橢圓曲線公式中平方項x2的系數。剩餘的推導部分則跟之前的一樣,除了現在x1 = x2,因此我們可以帶入到上面的公式得到:
x3 = s2 - 2x1
y3 = s(x1-x3)-y1
|
推導橢圓曲線的切線斜率
推導橢圓曲線的切線斜率需要一點更高級的數學知識:微積分。我們知道連續函數上的一個點的斜率為: dy/dx 計算它需要對橢圓曲線的等式兩邊求導數: y2=x3+ax+b 對等式兩邊求導後,得到: 2y dy=(3x2+a)dx 整理後得到: dy/dx=(3x2+a)/(2y) 至此,我們得到了切線的斜率公式。其餘計算部分和之前的點加法的公式一致。 |
3. 第三章 橢圓曲線密碼學
在前面兩章中,我們討論了一些基本數學知識。我們學習了有限域的運算方式以及橢圓曲線的定義。在這個章節里,我們將結合這兩個知識點來學習橢圓曲線密碼學(Elliptic Curve Cryptography)。最後,我們將構建簡單的消息簽名和驗證工具,而這也是比特幣的核心部分。
3.1. 實數域上的橢圓曲線
在[第二章]中,我們通過繪制實數域上的橢圓曲線,來瞭解橢圓曲線在幾何上是什麼樣的。但實際上橢圓曲線上不只有整數,有理數,還包括所有的實數。 比如π,√2,e+⁷√19。
原因是實數本身也是一個域。除了實數域包括無限多個實數外,其他性質和有限域是一樣的,包括:
-
如果a 和 b 屬於集合,則a+b 和a⋅ b也屬於集合。
-
0 存在,並且 a+0=a。
-
1 存在,並且 a⋅1=a。
-
如果a屬於集合,則-a屬於集合,滿足a+(-a)=0。
-
如果a屬於集合,則a-1屬於集合,滿足a⋅ a-1=1。
毫無疑問,實數域滿足以上性質:實數的加法和乘法滿足1 和 2。加法恆等元和乘法恆等元 0 和 1 也存在,-x 是 x的加法逆,1/x 是x 的乘法逆。
在圖形上我們可以輕而易舉地繪畫出實數。比如 y2=x3+7 的圖像為[Figure 3-1]。
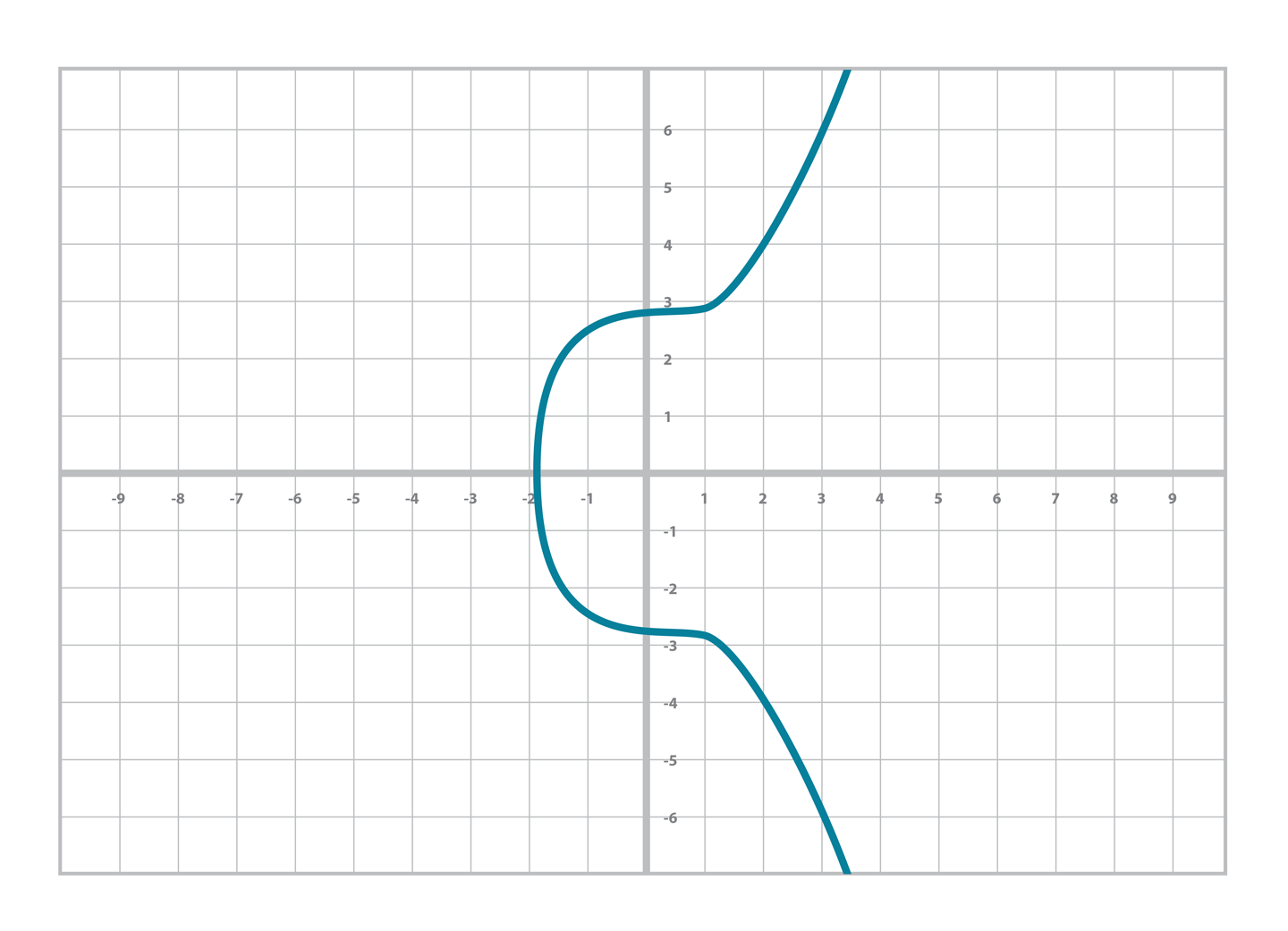
Figure 3-1. 實數域上的secp 256k1曲線
實際上我們可以在任何域上使用點加法,包括我們在[第一章]學習的有限域。唯一的區別是我們使用的加減乘除須是[第一章]定義的版本,而不是「常見」的實數使用的版本。
3.2. 有限域上的橢圓曲線
一個有限域上的橢圓曲線(Elliptic curve over a finite field)是如何定義的呢?讓我們考察一下這個的方程:y2=x3+7 over F103 。可以通過計算驗證點 (17,64)在橢圓曲線上:
y2=642%103=79
x3+7=(173+7)%103=79
通過有限域的數學知識我們驗證了該點的確在這條曲線上。
如果把所有符合方程的有限域的點繪制出來,結果會和實數域的圖像完全不一樣[Figure 3-2]。
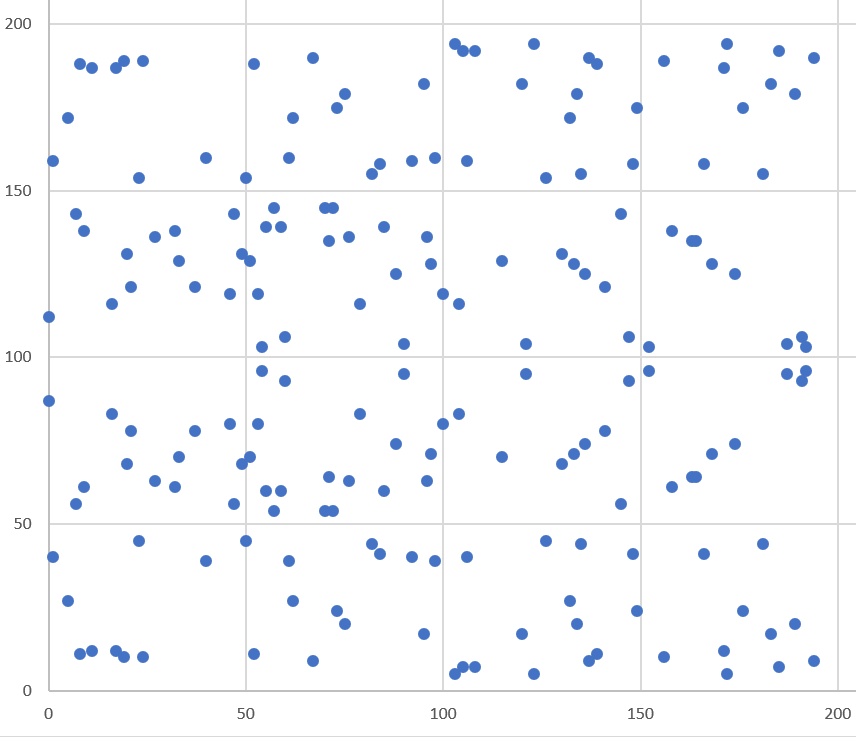
Figure 3-2. 有限域上的橢圓曲線
如圖像所示,這是一個散點圖而不是一個光滑的曲線。這並不意外,因為本身這些(有限域的)點就是離散的。唯一能觀測到的規律是散點圖在中間部分上下對稱,原因是等式左邊的項 y2。該圖像沒有關於x 軸對稱,而是從中間對稱,原因是在有限域中沒有負數元素。
有限域上的橢圓曲線擁有非常好的性質,之前定義的關於有限域的加減乘除和指數運算仍然適用。雖然看上去非常神奇,儘管和你熟悉常見的計算模式非常不一樣,但抽象代數確有這樣的規律性。
3.3. 實現有限域上的橢圓曲線
因為我們在有限域上已經定義過+-× 和 / 運算符。現在我們可以結合兩個類來實現有限域上的橢圓曲線:
>>> from ecc import FieldElement, Point
>>> a = FieldElement(num=0, prime=223)
>>> b = FieldElement(num=7, prime=223)
>>> x = FieldElement(num=192, prime=223)
>>> y = FieldElement(num=105, prime=223)
>>> p1 = Point(x, y, a, b)
>>> print(p1)
Point(192,105)_0_7 FieldElement(223)當我們初始化一個點的時候,我們可以運行下面這段代碼:
class Point:
def __init__(self, x, y, a, b): self.a = a
self.b = b
self.x = x
self.y = y
if self.x is None and self.y is None:
return
if self.y**2 != self.x**3 + a * x + b:
raise ValueError('({}, {}) is not on the curve'.format(x,y))其中的加法(+),乘法(),指數(*),和不等判斷(!=)的運算符使用FieldElement的方法__add__ ,__mul__, __pow__ 和__ne__ 的重載,而不是整數使用的版本。對同一個曲線的基礎運算給出不同定義是我們構造橢圓曲線加密庫的方法。
有限域上的橢圓曲線的點所需要的兩個基礎類我們在之前完成了。但是為了測試其正確性,我們有必要建立一個測試組件。比如利用[Exercise 1]作為測試數據的一部分。
class ECCTest(TestCase):
def test_on_curve(self):
prime = 223
a = FieldElement(0, prime)
b = FieldElement(7, prime)
valid_points = ((192, 105), (17, 56), (1, 193))
invalid_points = ((200, 119), (42, 99))
for x_raw, y_raw in valid_points:
x = FieldElement(x_raw, prime)
y = FieldElement(y_raw, prime)
Point(x, y, a, b) # (1)
for x_raw, y_raw in invalid_points:
x = FieldElement(x_raw, prime)
y = FieldElement(y_raw, prime)
with self.assertRaises(ValueError):
Point(x, y, a, b) # (1)#1 在數據初始化時,我們把FieldElement 對象傳遞給Point 類。好處之一是我們之後可以使用在FieldElement中重載後的運算符。
我們可以如下運行測試:
>>> import ecc
>>> from helper import run # (1)
>>> run(ecc.ECCTest('test_on_curve'))
.
----------------------------------------------------------------------
Ran 1 test in 0.001s
OK-
helper是包含一些非常有用的工具函數的模區塊,比如這次使用的單元測試。
3.4. 有限域上的點加法
我們可以繼續使用有橢圓曲線上的那些函數,包括一次函數:
y=mx+b
結果顯示,有限域上的直線可能和你的預期並不一致。([Figure 3-3])
Figure 3-3. 有限域上的直線
無論如何,該方程在有限域上仍然是有意義的。並且對給定x,我們可以計算出y的值。點加法也一樣在有限域上有效。因為實際上橢圓曲線點加法可以在所有的域使用。我們在有限域上使用的也是相同的計算方法,即 當x1≠ x2:
P1 = (x1,y1), P2 = (x2,y2), P3 = (x3,y3)
P1 + P2 = P3
s = (y3 – y1)/(x3 – x1)
x3 = s2 – x1 – x2
y3 = s(x1 – x3) – y1
當 P1=P2 時:
P1 = (x1,y1), P3 = (x3,y3)
P1 + P1 = P3
s = (3x12 + a)/(2y1)
x3 = s2 – 2x1
y3 = s(x1 – x3) – y1
所有在橢圓曲線上的操作在有限域上依然是有效的,這能幫助我們構建一些密碼學基礎工具。
3.5. 實現有限域上的點加法
因為我們使用了重載的方式實現了 FieldElement 類的__add__, __sub__, __mul__, __truediv__,__pow__, __eq__, 和 __ne__ 方法。我們可以使用有限域的實例來初始化有限域:
>>> from ecc import FieldElement, Point
>>> prime = 223
>>> a = FieldElement(num=0, prime=prime)
>>> b = FieldElement(num=7, prime=prime)
>>> x1 = FieldElement(num=192, prime=prime)
>>> y1 = FieldElement(num=105, prime=prime)
>>> x2 = FieldElement(num=17, prime=prime)
>>> y2 = FieldElement(num=56, prime=prime)
>>> p1 = Point(x1, y1, a, b)
>>> p2 = Point(x2, y2, a, b)
>>> print(p1+p2)
Point(170,142)_0_7 FieldElement(223)3.6. 橢圓曲線的標量乘法
因為一個點可以加上這個點本身,所以我們引入一個新的記號:
(170,142) + (170,142) = 2 ⋅ (170,142)
類似的,因為結合律,我們可以對點本身再加一次: 2 ⋅ (170,142) + (170,142) = 3 ⋅ (170, 142)
我們可以重復做很多次的類似運算。這就是我們所謂的標量乘法(scalar mulpiplication )。因此在一個點的前面我們可以增加一個標量。我們能這樣做的原因是我們定義的點加法是有結合律的。
一個標量乘法的優秀性質是:除非經過計算,否則很難預測其結果。(參考 [Figure 3-4])
Figure 3-4. 計算有限域上的橢圓曲線 y2=x3+7 over F223上點(170,142)的標量乘法
每個點上的標籤表明我們對該點做了幾次加法。你也可以看見結果完全是一個散點圖。這是因為點加法是非線性的且不易計算的。計算標量乘法很直接,與此相反,除法並不直觀。
這樣的問題被稱為 離散對數問題 (discrete log problem),這是橢圓曲線密碼學的核心。
標量乘法的另一個性質是在經過一定次數的乘法運算後,會得到無窮遠點(無窮遠點也就是加法單位元或者0)。我們假設有個點 G,不斷做標量乘法,直到計算出無窮遠點。那麼我們獲得了下面的集合:
G,2G,3G,4G,…nG where nG=0
這樣的集合可以稱為群,因為n是有限的,我們構造了一個有限群(更具體說,是一個有限循環群)。群在數學的概念上很有趣,因為它們能很優美地和加法對應起來:
G+4G=5G or aG+bG=(a+b)G
結合標量乘法的直接運算直觀而逆運算複雜的屬性以及群的數學性質,我們準備了構建橢圓曲線密碼學的基礎。
3.7. 再議標量乘法
標量乘法是一個點自己加上自己數次。標量乘法能成為公鑰密碼學的核心原因是橢圓曲線上的標量乘法很難做逆運算,可以參考上一個練習。更可能的做法是你計算了s ⋅ (47,71) in F223 對從1到21的每個s 都計算一次。結果如下:
>>> from ecc import FieldElement, Point
>>> prime = 223
>>> a = FieldElement(0, prime)
>>> b = FieldElement(7, prime)
>>> x = FieldElement(47, prime)
>>> y = FieldElement(71, prime)
>>> p = Point(x, y, a, b)
>>> for s in range(1,21):
... result = s*p
... print('{}*(47,71)=({},{})'.format(s,result.x.num,result.y.num))
1*(47,71)=(47,71)
2*(47,71)=(36,111)
3*(47,71)=(15,137)
4*(47,71)=(194,51)
5*(47,71)=(126,96)
6*(47,71)=(139,137)
7*(47,71)=(92,47)
8*(47,71)=(116,55)
9*(47,71)=(69,86)
10*(47,71)=(154,150)
11*(47,71)=(154,73)
12*(47,71)=(69,137)
13*(47,71)=(116,168)
14*(47,71)=(92,176)
15*(47,71)=(139,86)
16*(47,71)=(126,127)
17*(47,71)=(194,172)
18*(47,71)=(15,86)
19*(47,71)=(36,112)
20*(47,71)=(47,152)如果你仔細檢查這些結果,並不能找到標量乘法可辨別的模式和規律。x 和y坐標並不是單調遞增或者遞減的。唯一的模式是在s為10和11時,x軸坐標相等。(類似的9 和 12,8和 13等都成立)。這是因為21⋅(47,71)=0。
標量乘法看上去非常隨機,也就給了方程非對稱的性質。非對稱指的是單向容易計算,反向的逆運算困難。舉例,我們可以容易地計算12⋅(47,71)。但是我們換個問題:
s⋅(47,71)=(194,172)
我們怎麼計算s 呢?我們可以根據之前的計算表查找得到。但是這是因為我們有一個相對性小的群。我們將在第58頁的[「定義比特幣的橢圓曲線」]介紹,當有非常大的數字時,離散對數問題將是非常難計算的。
3.8. 數學上的群
我們之前學習的數學知識(結合了有限域和橢圓曲線)把我們引向這個問題。為了公鑰密碼學,我們真正想構造的實際上是有限循環群。結論是如果我們從有限域上的橢圓曲線上選擇一個點作為起點,我們可以生成一個有限循環群。
和域不同,群只有一個運算符。在我們討論的情況下,這個運算符指的是點加法。群還有一些其他特性。比如封閉性(closure),可逆性(invertibility),交換律(commutativity)和結合律(associativity)。最後我們還需要恆等元(identity)。 (譯注:因為群只有一個運算符,所以恆等元指加法恆等元)。
3.8.1. 恆等元
如果現在還沒有猜出來恆等元的定義,單位恆等元指的是無窮遠點且該點且一定在群中,因為我們是從無窮遠點開始生成的群:
0+A=A
我們把0 稱為無窮遠點,因為從幾何上看,無窮遠點的存在保證了群的數學性質。([Figure 3-5])
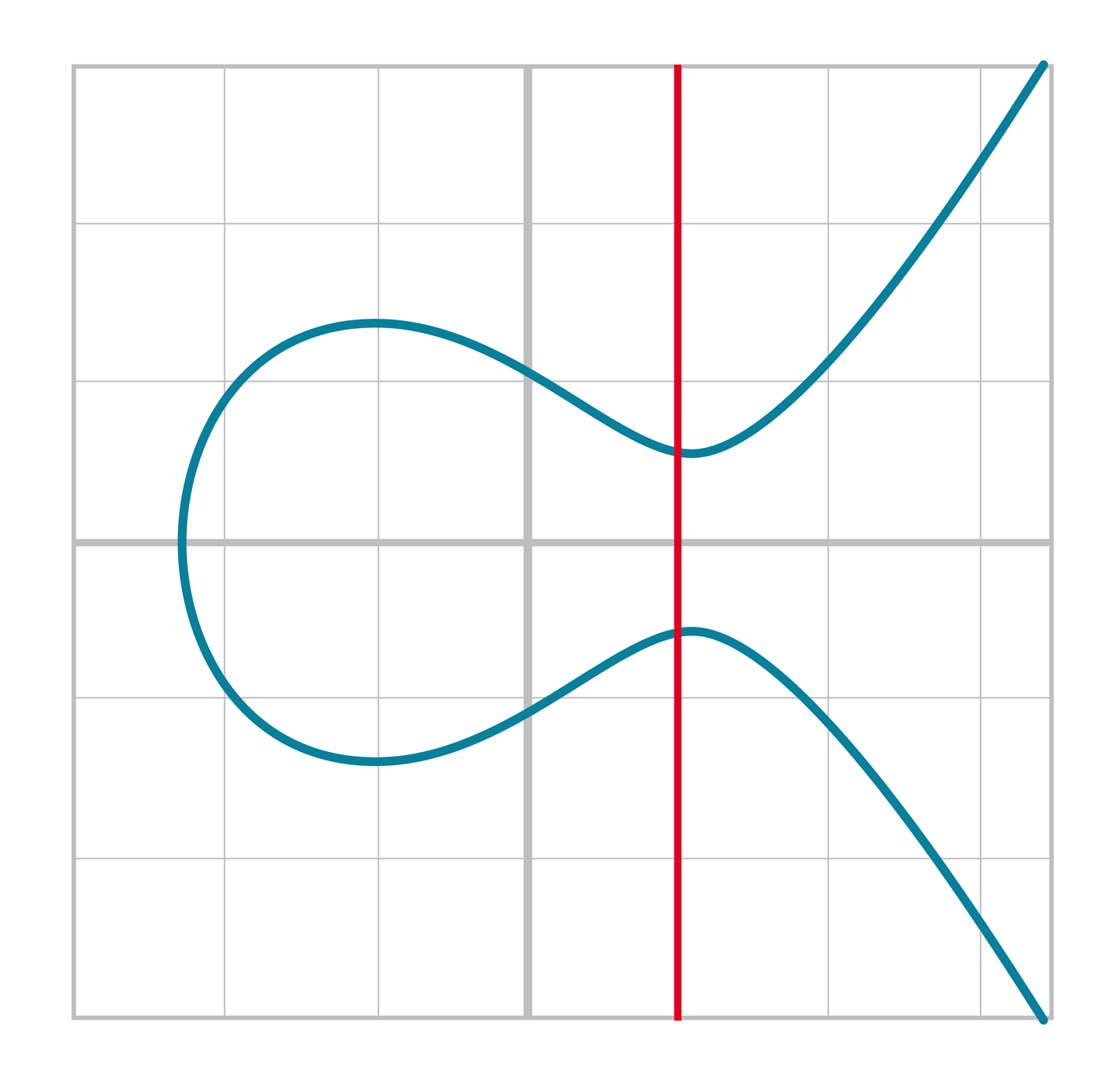
Figure 3-5. 垂直的直線與橢圓曲線相交,第三個交點為無窮遠點
(譯注:假設垂直x軸直線與橢圓曲線的一個交點為A,A與無窮遠點確定的直線與橢圓曲線相交第三個交點A'。A' 關於x軸對稱為A,即A+0=A)
3.8.2. 封閉性
封閉性應該是最好證明的性質。因為我們群的生成過程就是通過對點G不斷做加法。因此,如果有兩個不同的元素的加法:
aG+bG
我們可以得出其結果為:
(a+b)G
我們怎麼判斷這個結果仍然在群內呢?如果 a+b<n(n是這個群的階),根據定義,我們知道其在群內。 如果a+b>=n,因為我們知道a<n和b<n,所以
a+b⇐2n,所以 a+b-n<n: (a+b-n)G=aG+bG-nG=aG+bG-0=aG+bG
更普遍地,(a+b)G=((a+b)%n)G,n 是群的階數。
所以我們知道加法的結果是群的元素,因此我們證明瞭群封閉性。
3.8.3. 可逆性
可逆性很容易描繪([Figure 3-6])。
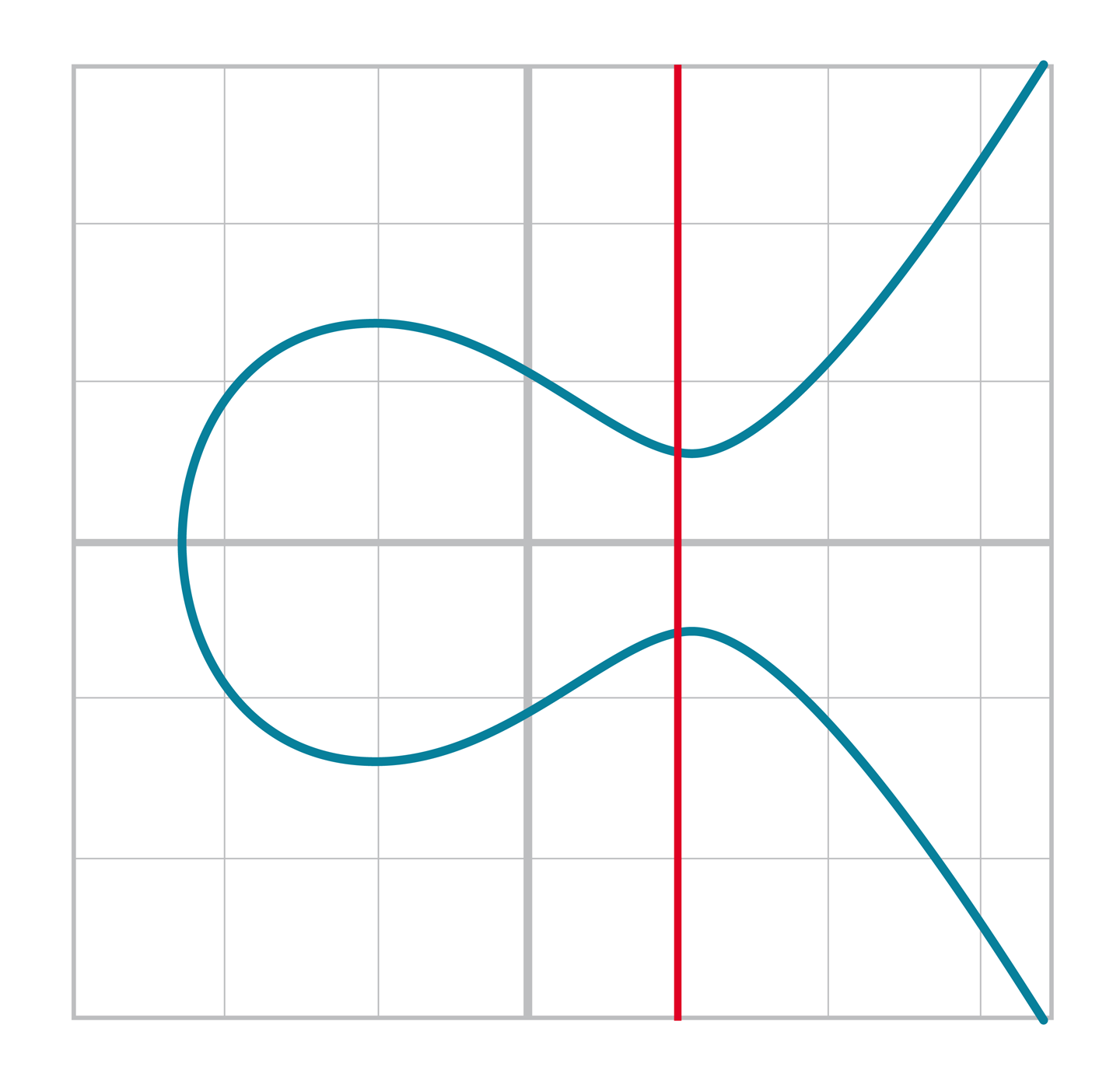
Figure 3-6. 每個點的逆可以通過對x軸做對稱得到
數學上,我們知道如果aG在群內,(n-a)G也在群內。因為把兩者相加,aG+(n-a)G=(a+n-a)G=nG=0
3.9. 實現標量乘法
我們嘗試按照如下的方式完成[Exercise 5]:
>>> from ecc import FieldElement, Point
>>> prime = 223
>>> a = FieldElement(0, prime)
>>> b = FieldElement(7, prime)
>>> x = FieldElement(15, prime)
>>> y = FieldElement(86, prime)
>>> p = Point(x, y, a, b)
>>> print(7*p)
Point(infinity)我們希望實現標量乘法,一個數乘以點對象的情況。幸運的是在python 中有一個__rmul__ 方法可以重載左乘法(front multiplication)。一個簡單實現如下:
class Point:
...
def __rmul__(self, coefficient):
product = self.__class__(None, None, self.a, self.b)#1
for _ in range(coefficient):#2
product += self
return product#1 我們初始化product 為0,來處理被標量乘法的點是無窮遠點。
#2 每次循環,我們對product 加一次被標量乘法的點。
譯注: 當Python試圖乘以兩個不同對象時,它首先嘗試調用左對象的__mul__()方法。如果左對象沒有__mul__()方法或者處理不了右對象的類型,則會去尋找右對象的方法__mul__()。如果我們希望這個乘法是不可交換順序的,比如我們這裡要求是[常數 * FieldElement對象],則需要重載的對應方法應該是__rmul__()。 rmul 中r 對應的單詞為reverse,反向。
這對小的系數來說是可接受的。但是如果有一個非常大的系數,那麼這個計算不會在合理的時間內得到結果。比如我們標量乘法的系數選擇1萬億(1 trillion),就會花非常長的時間。
有一個名為二進制展開(binary expansion)的技術可以幫助我們把複雜度降到log2(n),可以顯著降低計算所需要的時間。比如1萬億用二進制表示需要40個二進制位(bit)。我們只需要40次循環就可以處理萬億次這個被認為相對大規模的問題。
class Point:
...
def __rmul__(self, coefficient):
coef = coefficient
current = self #1
result = self.__class__(None, None, self.a, self.b)#2
while coef:
if coef & 1:#3
result += current
current += current#4
coef >>= 1#5
return result-
current 代表目前要處理的比特位。在循環時,第一次current 代表 1× self,第二次代表 2× self,第三次代表 4×self, 以此類推,之後時 8× self 等等。我們每次都翻倍。在二進制表示為,1,10,100,1000,10000。
-
我們從無窮遠點,0 開始。
-
我們判斷最右的比特位是否是1,如果是,result 要增加current。
-
對目前的點加倍。
-
coef 的比特位右移。
這是一個高級技巧。如果你不瞭解位運算,可以理解為對系數用二進制表示後,只加那些包含1 的位的值。
結合 __add__ 和 __rmul__,我們可以開始定義一些更複雜的橢圓曲線。
(譯注:有關這個技巧的原理、細節和效率的討論可以搜索 「埃及乘法」的相關內容)
3.10. 定義比特幣的曲線
出於舉例的目的,我們使用的是相對小的數字。但我們並不止步於如此小的數字。使用一個小的質數意味著可以使用計算機窮舉群的所有元素。比如群的大小只有301,電腦可以容易地做301次運算遍歷來做標量乘法的逆運算,破解離散對數問題。
但是如果選擇一個更大的質數呢?實際上我們可以選擇比我們常見的質數大非常多的質數。橢圓曲線密碼學方案的安全性取決於計算機不可能遍歷群的哪怕是其中的一小部分。
一個公鑰密碼學方案使用的橢圓曲線通過如下變量定義:
-
確定曲線 y2=x3+ax+b 中的 a 和 b。
-
確定有限域需要的質數 p。
-
確定起點G的坐標(x,y)。
-
確定通過G生成的群的階數n。
這些參數都是公開的,一起構成了密碼學曲線。出於安全性和易用性的考量,有非常多的密碼學曲線。但我們最關心的是比特幣使用的曲線:secp256k1。其選取的參數為:
-
a=0,b=7,曲線方程為 y2=x3+7
-
p=2256-232-977
-
Gx=0x79be667ef9dcbbac55a06295ce870b07029bfcdb2dce28d959f2815b16f81798
-
Gy=0x483ada7726a3c4655da4fbfc0e1108a8fd17b448a68554199c47d08ffb10d4b8
-
n=0xfffffffffffffffffffffffffffffffebaaedce6af48a03bbfd25e8cd0364141
Gx為 G點的x坐標,Gy為y坐標。數字以0x為前綴表明其為16進制。
比特幣的曲線有幾個值得注意的地方。第一個是方程的參數a,b 非常簡單,很多曲線選擇了非常大的a和b。
第二,p 的選取非常接近2256。這意味著大部分小於2256 的質數都屬於這個質數域。因此這個曲線上的點都可以用256位的二進制數表示。n也非常接近2256,這表示標量乘法的常數也可以用256位的二進制數表示。
第三,2256 是一個非常大的數字。同時任何小於2256的數字都可以用32字節的空間儲存,這使得私鑰的儲存相對容易。
3.10.1. 使用 secp256k1
既然我們已經知道secp256k1橢圓曲線的所有參數,我們就可以驗證初始點 G 是否在橢圓曲線y2=x3+7上了:
>>> gx = 0x79be667ef9dcbbac55a06295ce870b07029bfcdb2dce28d959f2815b16f81798
>>> gy = 0x483ada7726a3c4655da4fbfc0e1108a8fd17b448a68554199c47d08ffb10d4b8
>>> p = 2**256 - 2**32 - 977
>>> print(gy**2 % p == (gx**3 + 7) % p)
True進一步,我們可以驗證初始點G生成的群,其階數是否為n:
>>> from ecc import FieldElement, Point
>>> gx = 0x79be667ef9dcbbac55a06295ce870b07029bfcdb2dce28d959f2815b16f81798
>>> gy = 0x483ada7726a3c4655da4fbfc0e1108a8fd17b448a68554199c47d08ffb10d4b8
>>> p = 2**256 - 2**32 - 977
>>> n = 0xfffffffffffffffffffffffffffffffebaaedce6af48a03bbfd25e8cd0364141
>>> x = FieldElement(gx, p)
>>> y = FieldElement(gy, p)
>>> seven = FieldElement(7, p)
>>> zero = FieldElement(0, p)
>>> G = Point(x, y, zero, seven)
>>> print(n*G)
Point(infinity)我們之後也會在這個曲線上操作,這是一個非常好的時機在python上單獨創建一個secp256k1橢圓曲線的子類。同時通過對應的Fieldment 和 Point 對象,制定其為secp256k1 曲線。讓我們開始定義我們之後需要用到的曲線吧:
P = 2**256 - 2**32 - 977
...
class S256Field(FieldElement):
def __init__(self, num, prime=None):
super().__init__(num=num, prime=P)
def __repr__(self):
return '{:x}'.format(self.num).zfill(64)我們通過子類繼承,不需要每次使用都要傳遞P了。同時我們也想以完全充填的64個字符的格式來代表256位的數字,這樣我們會看到以0為前綴的數字。
類似地,我們可以定義一個secp256k1上的點,命名為S256Point 類:
A = 0
B = 7
...
class S256Point(Point):
def __init__(self, x, y, a=None, b=None):
a, b = S256Field(A), S256Field(B)
if type(x) == int:
super().__init__(x=S256Field(x), y=S256Field(y), a=a, b=b)
else:
super().__init__(x=x, y=y, a=a, b=b)#1#1 為了應對無窮遠點初始化,我們需要允許直接傳入 x和 y而不是用S256Field 類。
現在我們有一個更簡單的方法來初始化secp256k1曲線。不需要和之前使用Point 類時,每次都定義a,b。
我們也可以重新定義__rmul__使之更有效率。因為已知群的階數,n。因為我們在使用python,我們使用大寫N 來表明N 是一個常數:
N = 0xfffffffffffffffffffffffffffffffebaaedce6af48a03bbfd25e8cd0364141
...
class S256Point(Point):
...
def __rmul__(self, coefficient):
coef = coefficient % N #1
return super().__rmul__(coef)#1 我們可以對n取余,因為nG=0,即每n次就循環回0,或者無窮遠點。
現在我們就可以直接定義G,並之後已知使用它:
G = S256Point(
0x79be667ef9dcbbac55a06295ce870b07029bfcdb2dce28d959f2815b16f81798,
0x483ada7726a3c4655da4fbfc0e1108a8fd17b448a68554199c47d08ffb10d4b8)現在再檢查G構成的群的階數是n就非常容易了:
>>> from ecc import G, N
>>> print(N*G)
S256Point(infinity)3.11. 公鑰密碼學
終於,我們已經湊齊了完成公鑰密碼學的工具。核心運算是P= eG是一個非對稱方程。如果知道e和G,可以輕易的計算出P,但是已知P和G,很難推理出e。這就是我們之前提到的離散對數問題。
離散對數的難計算是我們理解籤名和驗證算法的核心知識。
一般地講,我們稱e為私鑰,P為公鑰。注意私鑰是一個長度為256-bit的數字,公鑰是一個坐標(x,y), x和y也是256-bit的數字。
3.12. 簽名和驗證
為了幫助理解籤名和驗證存在的動機,我們想象下面的場景。你想證明你是一個優秀的弓箭手,有能力在500碼內,射中任何選定物體。
當有一個人可以觀察到你,並與你交流,證明你的能力並不困難。他可以把你的兒子放置在400碼的距離,頭頂一個蘋果,讓你用箭射中蘋果。作為一個優秀的弓箭手,你可以完成這個挑戰來證明你的能力。驗證者選定的靶使得你的箭術很容易被驗證。
不幸的是,這種方法缺乏擴展性。比如你想證明給10個人看,你需要完成10個不同的挑戰,射出10支箭,射向10個不同的靶。你可以讓10個人圍觀你射一箭,但是因為不可能讓10個人都指定靶,所以他們總會懷疑是否你只擅長特定的靶,而是不任意的靶。我們需要的這樣的一個證明,你只完成一次,不需要和觀察者交流,但他們仍然確信你是一個優秀的弓箭手,可以射中任意的靶。
比如,你簡單的射中了你選定的目標,人們觀測後並沒有信服。畢竟有可能是你先射箭後畫靶。那麼你應該怎麼做呢?
有一個非常機智的方法供你選擇。在箭的箭頭上雕刻你要射中的靶的坐標(孩子頭上的蘋果),之後用箭射中你的靶。現在任何看到靶的人都可以使用X光機看看嵌入的箭頭的坐標是否是靶的位置。很明顯,箭頭必須在射入靶之前就雕刻好坐標。所以他們可以相信你是一個優秀的弓箭手(假設這個靶並不是你反復多次練習過)。
我們簽名和驗證使用的是相同的技巧,我們要證明的從優秀的箭術替換為我們掌握一個隱秘的數字。我們希望證明我們掌握這個數字但不透露這個數字本身。我們可以通過把「靶」放進我們的計算過程,然後擊中「靶」來實現。
最後我們將要把它用在比特幣的交易上,它會幫我們證明真正的隱秘數字所有者正在使用他的比特幣。
3.12.1. 雕刻靶坐標
雕刻靶坐標依賴簽名算法,我們使用的算法是橢圓曲線數字簽名算法(Elliptic Curve Digital Signature Algorithm)或者簡寫為 ECDSA。
算法需要保護的秘密e滿足下面的等式:
eG=P
P是公鑰,e是私鑰。
我們選定的靶是一個隨機的256位的隨機數k,我們有:
kG=R
於是R替換成為新的靶,實際上我們只關心R的x軸坐標,命名為r,你可能已經猜出來r代表隨機(random)。
我們宣稱下面的方程等價於離散對數問題(譯注:指eG=P):
uG+vP=kG
k是隨機選取的,u,v ≠ 0由簽名者提供,G和P是公開的。這個命題成立是因為:
uG+vP=kG ⇒ vP=(k-u)G
由於v≠ 0,我們可以通過除以標量乘法的系數v得到:
P=((k-u)/v)G
如果得知e,我們有:
eG=((k-u)/v)G 或者e=(k-u)/v
這意味著任何(u,v)的組合,只要滿足上面的方程,將足夠證明其為e持有者。 如果我們不知道e,我們將不得不窮舉(u,v) 直到e=(k-u)/v。如果我們能提供滿足方程的任意(u,v)組合,這意味著我們在只知道P和G的情況下,已經解決了P=eG 的離散對數問題。也就是我們破解了離散對數問題。
反過來推理,如果我們能提供正確的(u,v)組合,要麼我們已經解決了離散對數問題,要麼真的掌握私鑰e。因為我們假設離散對數問題是難以計算的,我們可以說對於得出u和v的人來說e是已知的。
一個微妙的未討論的問題是引入射擊的意圖。這是一個包含射擊結果的約定(contract)。比如William Tell, 射中目標是為了拯救他的兒子(你射中是則為了拯救自己的孩子)。可以想象,有各種各樣的原因使得有人射中目標,也會有射中目標不同的獎勵。我們必須把動機的內容也雕刻到箭頭上。
在簽名和驗證的語境下,這被命名為簽名雜湊(signature hash)。雜湊函數(hash)是確定性函數,接受任意數據並轉化為定長數據。簽名雜湊是包含射擊者意圖的消息指紋,任何驗證消息的人都會接收它。我們用字母z表示。我們通過如下的方式把它雕刻在uG + vP的計算中。
u=z/s, v=r/s
我們知道r參與了v的計算,所以箭頭已經雕刻了目標。通過u的計算,我們也雕刻了射擊的目的。所以射擊的靶和射擊的原因都已經在方程中了。
為了使方程成立,接下來計算s:
uG + vP = R = kG uG + veG = kG u + ve = k z/s + re/s = k (z + re)/s = k s = (z + re)/k
這就是基礎的簽名算法,簽名的產出是 r 和 s。
驗證過程也非常直接明瞭:
uG+vP=(z/s)G+(re/s)G=z+re)/s)G =((z+re)/((z+re)/kG=kG=(r,y)
(譯注:這裡作者的推導並不是實際驗證簽名的計算過程,只是來幫助讀者理解驗證的正確性。因為私鑰e和隨機數k不會交給驗證者,實際上驗證者可以公開拿到的數據包括簽名者提供的z,r,s,有限域上的橢圓曲線的參數 G,和公鑰 P。真正的驗證過程只有等式 uG+vP=(r,y)),如果等式成立,則意味著簽名者有能力計算出正確的u(雕刻了的意圖z) 和 v(雕刻了的目標r)。在離散對數問題不可解的前提下,唯一合理的結論是簽名者的確掌握密鑰e,並主動完成了簽名。)
|
為什麼不公開 k
在前面的討論中,你可能好奇為什麼我們不公開k,而是選擇R的x軸坐標r。如果我們公開 k則會出現:
這意味著我們的私鑰內容是可破解的,這完全違背了簽名的目的。相對而言,我們可以公開R。 值得反復強調的是:確保你選擇k時使用的是真隨機數。同時意外的洩露一個已知的簽名的k等同於洩露你的私鑰並丟失你的資產。 |
3.12.2. 驗證的細節
我們的簽名限定了只對固定長度,32 字節(byte)長度的值簽名。32字節等於256比特(bits)並不是巧合,因為簽名的內容應當是G的一個標量。
為了保證簽名的消息是32字節,我們需要對文檔進行雜湊運算(hash)。比特幣採用的雜湊函數(hash function) 是hash256,即兩輪sha256。這保證了簽名的消息可以轉換成定長32 字節。我們把計算結果命名為簽名雜湊,z。
待驗證的簽名包括兩個參數(r,s)。r是點R 的x軸坐標,之後會討論。s 的公式如下:
s=(z+re)/k
作為簽名者,我們是已知e,k,z的e,我們要證明的就是我們掌握e,P=eG。k是簽名者選定的隨機數,kG=R。z 根據上面的公式計算。 接下來我們根據公式R=uG+vP來計算 u和 v:
u=z/s v=r/s
因此
uG+vP=(z/s)G+(r/s)G=(z/s)G+(re/s)G=((z+re)/s)G
已知s=(z+re)/k:
uG+vP=z+re)/((z+re)/kG=kG=R
我們已經成功的計算出u和v,繼而計算出我們想要的R。進一步,我們在v的計算中使用r,證明來我們知道R的值。而提前知道R的前提是掌握密鑰e。
總結一下,我們需要以下的步驟:
-
接收簽名者提供的(r,s)作為簽名,z是被簽名的內容的hash值。P是簽名者的公鑰(或者公開的點)
-
計算u=z/s,v=r/s
-
計算 uG+vP=R
-
如果R 的x軸坐標等於r,則簽名是有效的
|
為什麼需要兩輪hash256
z的計算需要兩輪sha 256(或者 hash 256)計算。你可能好奇一輪雜湊運算就能獲得定長256位的數字,為什麼需要兩輪呢。這是出於安全的考慮。 生日攻擊是一種非常出名的針對SHA-1的雜湊碰撞攻擊(hash collision attack),使得尋找碰撞更加容易了。在2017年Google 發現了一個修改版本的針對SHA-1 的雜湊碰撞的生日攻擊方法並做了相關的研究。做兩次SHA-1(double SHA-1),是我們阻止和緩解類似攻擊的方法。 兩輪hash256 並不能完全阻止可能的攻擊,但這是一個修補潛在漏洞的防禦方法。 (譯注:有關雜湊碰撞和生日攻擊可以參考 相關文章) |
3.12.3. 驗證簽名
現在我們可以使用之前構建的基礎工具來驗證簽名:
>>> from ecc import S256Point, G, N
>>> z = 0xbc62d4b80d9e36da29c16c5d4d9f11731f36052c72401a76c23c0fb5a9b74423
>>> r = 0x37206a0610995c58074999cb9767b87af4c4978db68c06e8e6e81d282047a7c6
>>> s = 0x8ca63759c1157ebeaec0d03cecca119fc9a75bf8e6d0fa65c841c8e2738cdaec
>>> px = 0x04519fac3d910ca7e7138f7013706f619fa8f033e6ec6e09370ea38cee6a7574
>>> py = 0x82b51eab8c27c66e26c858a079bcdf4f1ada34cec420cafc7eac1a42216fb6c4
>>> point = S256Point(px, py)
>>> s_inv = pow(s, N-2, N)#1
>>> u = z * s_inv % N#2
>>> v = r * s_inv % N#3
>>> print((u*G + v*point).x.num == r)#4
True-
因為n是質數,我們可以使用費馬小定理來計算1/s
-
u=z/s
-
v=r/s
-
uG+vP=(r,y) 我們檢查其x軸坐標是否為r
3.12.4. Exercise 6
驗證下面的簽名是否是有效的:
P = (0x887387e452b8eacc4acfde10d9aaf7f6d9a0f975aabb10d006e4da568744d06c, 0x61de6d95231cd89026e286df3b6ae4a894a3378e393e93a0f45b666329a0ae34)
signature 1
z = 0xec208baa0fc1c19f708a9ca96fdeff3ac3f230bb4a7ba4aede4942ad003c0f60
r = 0xac8d1c87e51d0d441be8b3dd5b05c8795b48875dffe00b7ffcfac23010d3a395
s = 0x68342ceff8935ededd102dd876ffd6ba72d6a427a3edb13d26eb0781cb423c4
signature 2
z = 0x7c076ff316692a3d7eb3c3bb0f8b1488cf72e1afcd929e29307032997a838a3d
r = 0xeff69ef2b1bd93a66ed5219add4fb51e11a840f404876325a1e8ffe0529a2c
s = 0xc7207fee197d27c618aea621406f6bf5ef6fca38681d82b2f06fddbdce6feab6
3.12.5. 程序化地簽名驗證
我們已經實現了一個S256Point,提供了代表私鑰的公開點。我們創建一個簽名類來儲存r和s的值:
class Signature:
def __init__(self, r, s):
self.r = r
self.s = s
def __repr__(self):
return 'Signature({:x},{:x})'.format(self.r, self.s)我們會在[第四章]為這個類增加更多方法。
現在我們可以在S256Point類中實現 verify 方法:
class S256Point(Point):
...
def verify(self, z, sig):
s_inv = pow(sig.s, N - 2, N)#1
u = z * s_inv % N#2
v = sig.r * s_inv % N#3
total = u * G + v * self#4
return total.x.num == sig.r#5-
通過費馬小定理和群的質數的階數n計算出s_inv (1/s)
-
u=z/s,因為群的階數為n,我們可以對其做求余運算
-
v=r/s,因為群的階數為n,我們可以對其做求余運算
-
uG+vP 應為R
-
我們檢驗其x軸的坐標是否為r
當提供公鑰,即一個在secp256k1上的點 和一個簽名雜湊 z,我們就可以驗證這個簽名是否是有效的。
3.12.6. 簽名的細節
如果我們已經驗證簽名是如何完成的,簽名過程也就不難理解了。唯一缺失的部分是如何選取 k,以及後續計算R=kG。我們的方法是隨機的選取k。
簽名的過程如下: . 我們已知z 和 滿足eG=P的e
-
隨機選取 k
-
計算 R=kG,和 其x軸坐標r
-
計算 s=(z+re)/k
-
(r,s) 即為簽名結果
公鑰P 會傳遞給所有希望驗證簽名的人,驗證者還必須知道 z的值。我們之後會討論z的計算以及P是如何隨著簽名一並傳播出去的。
3.12.7. 創造簽名
現在我們可以嘗試完成一次簽名。
現在我們可以使用之前構建的基礎工具來構造簽名:
>>> from ecc import S256Point, G, N
>>> from helper import hash256
>>> e = int.from_bytes(hash256(b'my secret'), 'big')#1
>>> z = int.from_bytes(hash256(b'my message'), 'big')#2
>>> k = 1234567890#3
>>> r = (k*G).x.num#4
>>> k_inv = pow(k, N-2, N)
>>> s = (z+r*e) * k_inv % N#5
>>> point = e*G#6
>>> print(point)
S256Point(028d003eab2e428d11983f3e97c3fa0addf3b42740df0d211795ffb3be2f6c52,
0ae987b9ec6ea159c78cb2a937ed89096fb218d9e7594f02b547526d8cd309e2)
>>> print(hex(z))
0x231c6f3d980a6b0fb7152f85cee7eb52bf92433d9919b9c5218cb08e79cce78
>>> print(hex(r))
0x2b698a0f0a4041b77e63488ad48c23e8e8838dd1fb7520408b121697b782ef22
>>> print(hex(s))
0xbb14e602ef9e3f872e25fad328466b34e6734b7a0fcd58b1eb635447ffae8cb9-
這是一個「腦錢包」(brain wallet)的例子,通過記憶一些不太複雜的內容來保存私鑰的方法。請不要使用這個例子來做你的私鑰。
-
這是一個簽名雜湊,即我們要簽名的消息的雜湊。
-
kG=(r,y),所以我們只選取其x軸坐標。
-
s=(z+re)/k ,我們可以以n對其求余,因為這是一個階數為n的有限循環群。
-
(r,s) 即為簽名結果。
-
公鑰也要提供給驗證者。
|
小心應對隨機數的生成
如果使用python 的類似 random 庫來生成隨機數總的來說並不安全。本書使用的庫只是處於教學目的,請不要把在本章使用的任何代碼用在生產環境。 |
3.12.8. Exercise 7
使用下面的私鑰,完成消息的簽名:
e = 12345
z = int.from_bytes(hash256('Programming Bitcoin!'), 'big')3.12.9. 程序化地消息簽名
為了程序化的簽名消息。我們編寫一個PrivateKey 的類來儲存我們的私鑰:
class PrivateKey:
def __init__(self, secret):
self.secret = secret
self.point = secret * G#1
def hex(self):
return '{:x}'.format(self.secret).zfill(64)#1 為了之後方便使用,一並保存了公鑰。
我們再為這個類提供sign 方法:
from random import randint
...
class PrivateKey:
...
def sign(self, z):
k = randint(0, N) #1
r = (k*G).x.num #2
k_inv = pow(k, N-2, N)#3
s = (z + r*self.secret) * k_inv % N#4
if s > N/2:#5
s = N - s
return Signature(r, s)#6
#1 randint 隨機生成區間[0,n)內的整數。請不要在生產環境中使用此函數,這個庫生成的隨機數不夠隨機。
#2 r 是kG的x軸坐標。
#3 再次使用費馬小定理,n是質數。
#4 s=(z+re)/k
#5 目前只有使用小的s (小於n/2) 才能讓節點廣播交易。這是為瞭解決延展性的問題。
#6 我們需要返回一個我們之前實現的Signature 類。
[譯注:這裡我們簡單的討論一下#5, 這其中涉及了一些值得進一步解釋的概念和動機說明。首先作為ECSDA來說,這一步的if是多餘的,刪除後也是完整的ECSDA實現,這裡增加的限制是為瞭解決交易的延展性問題,也就是說,這個處理只針對比特幣。
交易延展性的詳細討論會在章節隔離驗證segwit討論其動機,問題和解決。但在本章,我們可以簡單理解為,我們希望簽名算法同樣的輸入參數,簽名算法只有唯一確定的簽名結果(r,s)。難道存在第二個合法的簽名嗎?有。根據域的性質,如果(r, s)是合法的簽名,則(r, -s)也符合,即(r,n-s)。有興趣的讀者可以把(r,n-s)帶入我們之前驗證的步驟中,不難得出同樣的結論。
同時存在兩個合法的簽名後續會導致的直接結果是合法的一個交易內容可以存在兩個不同的交易雜湊,在後續章節中,我們解釋為什麼這是比特幣的功能擴展最大的阻礙。
在比特幣的世界中,選擇小的s作為合法簽名只是為了統一標準。在BIP 146 (比特幣改進提案 Bitcoin Improvement Proposal )中提出,並隨後以軟分叉的方式實施。可以參考 相關討論 ]
4. 第四章 序列化
目前為止,我們已經實現了很多類,包括 PrivateKey,S256Point 和Signature。我們應該開始思考如何通過網路傳輸這些對象並儲存在硬碟內。我們依賴的技術是序列化(serialization)。我們希望能夠傳遞和儲存PrivateKey,S256Point 和Signature類的實例。如果還能使其更有效率就更理想了,在[第10章]會討論其原因。
4.1. 未壓縮的SEC格式
我們從公鑰的類S256Point類開始實現。回想一下,橢圓曲線加密中的公鑰實際上是(x,y)形式的坐標。我們如何序列化這些數據?
事實上,已經有用於序列化ECDSA公鑰的標準,稱為Standard for Efficeient Crypotgraphy(SEC高效加密標準)- 正如名字中「高效」暗示的那樣,它的開銷最小。我們需要關注兩種SEC格式:未壓縮格式和壓縮格式。我們將從前者開始,並在下一節中討論壓縮格式。
下面的步驟是生成一個給定點P=(x,y)的未壓縮SEC 格式(uncompressed SEC format)的步驟:
-
以0x04 作為前綴
-
以大端序整數的形式放入32字節的x軸坐標。
-
以大端序的形式放入32字節的y軸坐標。
未壓縮的SEC 格式如[Figure 4-1]。

Figure 4-1. 未壓縮的SEC格式
|
大端序和小端序
大端序和小端序編碼是為了解決數字儲存到硬碟的問題。一個小於256的數字很容易編碼,單個字節( 28)足以容納。但是如果數字大於256我們如何序列化這個數字為字節? 阿拉伯數字是從左讀到右,數字123代表 100+20+3而不是1+20+300。我們稱此為大端序,因為從高位端開始。 然而在計算機領域有些場合,更有效率的是與之相反的,從低位端開始的小端序。 因為計算機是以字節來儲存,即8個比特,我們將使用256進制(256 base)來計算。這意味著十進制數字500 的大端序表示為 01f4,即 500=1 × 256 + 244(f4是16進制),小端序表示f401。 (譯注:所以小端序為 f4 × 1+01× 256) 不幸的是一些比特幣的序列化採用了大端序(比如SEC 格式的 x和y的坐標)。另一些採用了小端序(比如[第五章]中的交易版本)。本書會逐個注明哪個部分採用了大端序還是小端序。 |
完成未壓縮SEC格式的序列化非常明瞭。最複雜的部分是如何把一個256位的數字轉換為大端序的32字節。代碼實現如下:
class S256Point(Point):
...
def sec(self):
'''returns the binary version of the SEC format'''
return b'\x04' + self.x.num.to_bytes(32, 'big') \
+ self.y.num.to_bytes(32, 'big')在Python3 中可以使用to_bytes方法將數字轉換為字節。第一個參數是它應該佔用多少字節,第二個參數是字節序(參見前面的注釋)。
4.2. 壓縮的SEC 格式
回想一下,對於任何x坐標,由於橢圓曲線中的y2項,最多有兩個y坐標。([Figure 4-2])
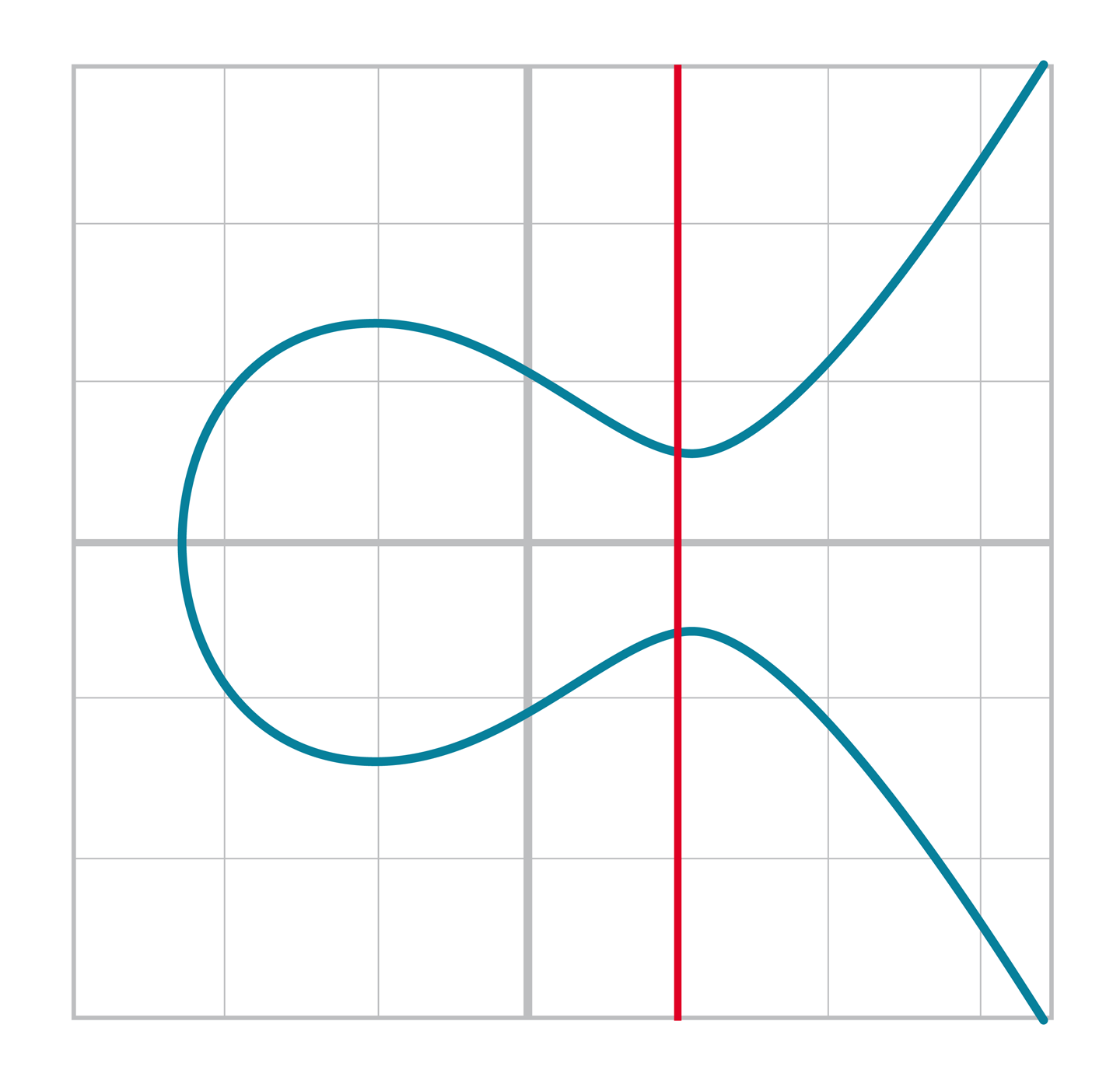
Figure 4-2. 當垂直於x軸與曲線相交
在有限域上也存在同樣的對稱性。
這是因為對於任意(x,y),如果滿足y2=x3+ax+b,那麼(x,-y)會在曲線上。進而在有限域上,有-y % p=(p-y)% p。更準確地說,如果(x,y)在有限域的橢圓曲線上,(x,p-y) 也在曲線上。因為對於一個x只有兩個解,如前面討論的,如果我們知道 x, 那麼y坐標不是y就是p-y。
因為p是一個大於2的質數,所以p也是奇數。如果y是偶數則p-y是奇數(奇數減偶數)。如果y是奇數則p-y是偶數(奇數減奇數)。也就是說,在y 和p-y中必然有一個奇數,另一個則是偶數。我們可以利用這一點來壓縮未壓縮的SEC格式:提供x坐標和y坐標的奇偶性。我們稱這個壓縮方法為壓縮的SEC格式(compressed SEC format)。y坐標被壓縮成單個字節(即偶數還是奇數)。
下面是對於點P=(x,y)採用壓縮的SEC格式序列化的步驟:
-
以y的奇偶性作為前綴,如果y是偶數,則為0x02,否則為0x03。
-
以大端序整數的形式放入32字節的x軸坐標。
壓縮的SEC格式如下圖[Figure 4-3]。

Figure 4-3. 壓縮的SEC格式
同樣的,其實現也很簡單。我們可以修改sec方法來處理壓縮的SEC公鑰:
class S256Point(Point):
...
def sec(self, compressed=True):
'''returns the binary version of the SEC format'''
if compressed:
if self.y.num % 2 == 0:
return b'\x02' + self.x.num.to_bytes(32, 'big')
else:
return b'\x03' + self.x.num.to_bytes(32, 'big')
else:
return b'\x04' + self.x.num.to_bytes(32, 'big') + \
self.y.num.to_bytes(32, 'big')壓縮的SEC 格式的巨大優勢是其只佔用了33個字節而不是65個。在數百萬次交易中使用,就可以積累很大的空間節省。
你可能會問我們是如何根據x計算的y呢?這需要我們在有限域中計算平方根。
即數學上的: 當給定v,計算滿足w2=v的w
事實上,如果有限域的質數 p%4=3時,我們可以非常容易地計算,以下是計算步驟: 首先我們知道:
p%4=3
可以推理出:
(p+1)%4=0
這說明(p+1)/4是一個整數。 根據定義:
w2=v
我們要找到一個計算w的公式。根據費馬小定理:
wp-1%p=1
可以得出:
w2=w2⋅ 1 =w2⋅ wp-1=wp+1
因為p是奇數(p是質數),所以(p+1)可以整除除以2,得出:
w=w(p+1)/2
利用(p+1)/4為整數的性質:
w=w(p+1)/2=w2(p+1)/4=(w2)(p+1)/4=v(p+1)/4
至此我們獲得了平方根公式:
當w2=v, p%4=3時w=v(p+1)/4
事實上secp256k1的橢圓曲線的質數 p%4==3,所以我們可以使用下面的公式:
w2=v
w=v(p+1)/4
w兩個可能值之一,另一個為p-w。這是因為求平方根的兩個結果為一正一反,互為相反數。 我們可以把這個方法加入到S256Field 類中:
class S256Field(FieldElement):
...
def sqrt(self):
return self**((P + 1) // 4)當我們得到一個序列化的SEC公鑰時,我們可以通過下面實現的parse方法來計算y:
class S256Point:
...
@classmethod
def parse(self, sec_bin):
'''returns a Point object from a SEC binary (not hex)'''
if sec_bin[0] == 4:#1
x = int.from_bytes(sec_bin[1:33], 'big')
y = int.from_bytes(sec_bin[33:65], 'big')
return S256Point(x=x, y=y)
is_even = sec_bin[0] == 2#2
x = S256Field(int.from_bytes(sec_bin[1:], 'big'))
# right side of the equation y^2 = x^3 + 7
alpha = x**3 + S256Field(B)
# solve for left side
beta = alpha.sqrt()#3
if beta.num % 2 == 0:#4
even_beta = beta
odd_beta = S256Field(P - beta.num)
else:
even_beta = S256Field(P - beta.num)
odd_beta = beta
if is_even:
return S256Point(x, even_beta)
else:
return S256Point(x, odd_beta)#1 未壓縮SEC 格式的解析簡單明確,沒有計算。
#2 y的奇偶性在第一個字節中給出。
#3 對橢圓曲線方程等號右邊部分求平方根可以得到y。
#4 根據y的奇偶性來決定返回正確的點。
4.3. DER 簽名
另一個我們需要序列化的類是Signature。和SEC格式一樣我們要對兩個不同的數字r和s編碼。和S256Point 不同,因為不能只根據r 計算出 s,所以簽名不能被壓縮。
簽名序列化的標準是 Distinguished Encoding Rules (DER 可分別編碼規則)格式。DER 格式被中本聰採用作為序列化簽名的方法。最可能的原因是這個標準在2008年確立,並且得到OpenSSL庫(比特幣當時使用的庫)的支持。與其創造一個新的標準,不如簡單地採納適應已有標準。
DER簽名格式如下定義:
-
以0x30字節作為前綴
-
追加剩餘簽名的長度(通常為0x44 或者0x45)
-
追加標記字節 0x02
-
以大端序編碼r,如果 r的第一個字節≥ 0x80則在r前置0x00,計算r序列化的長度並置於r的編碼結果前,追加以上內容。
-
追加標記字節 0x02
-
以大端序編碼s,如果 s的第一個字節≥ 0x80則在s前置0x00,計算s序列化的長度並置於s的編碼結果前,追加以上內容。
#4 和 #6 的規定了待序列化的數據第一個字節大於 0x80 的情況,因為DER是一個通用的編碼規則,允許負數編碼,第一位為1意味著數字為負數(譯注:指二進制轉換後的第一位)。ECDSA的簽名數據中的數字都為正數,所以如果簽名數字二進制轉化後第一位為1(等價於第一個字節大於0x80),我們需要前置0x00。
(譯注:這裡簡單補充一下0x80和負數的關係。對於一個字節能表達數字的為28=256,因為DER還負責負數的編碼,其代表的範圍應當是 -128 到127。我們對0x80 展開,即為1000 00002=12810。計算機為負數分配了大於 0x80 的編碼。比如0x80 為 -128, 0x82 為 -126。對大於0x80數字增加前綴的設計目的是為了防止簽名數據被認作負數)
DER 格式的如圖[Figure 4-4]:
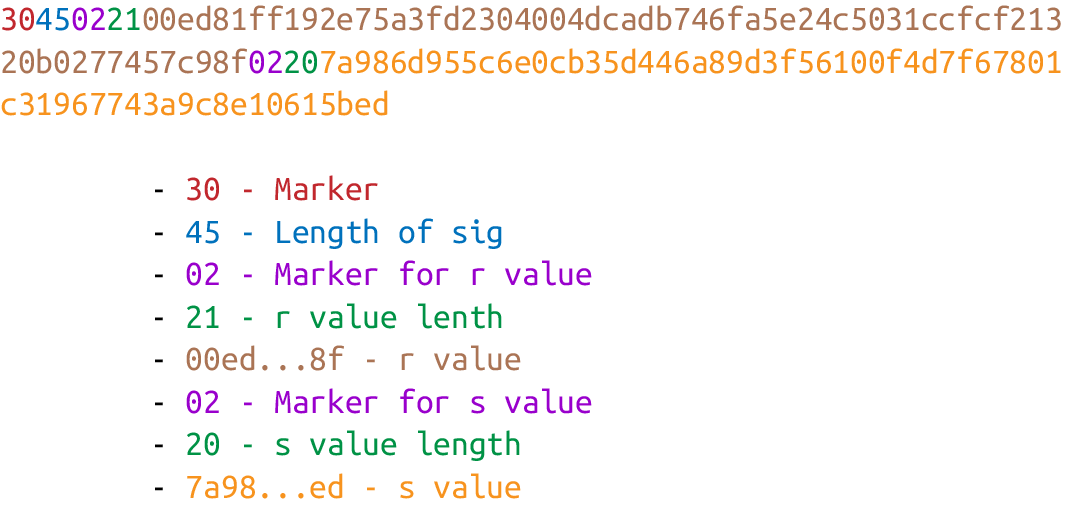
Figure 4-4. DER 格式
我們知道 r 是一個256比特的整數,大端序最多需要32字節來表示。因為第一個字節可能 ≥ 0x80,所以步驟#4 最多有33個字節。但如果 r 是一個相對小的數字,可能小於32個字節就能表示。同樣的情況對步驟# 6 也適用。 我們對其實現如下:
class Signature:
...
def der(self):
rbin = self.r.to_bytes(32, byteorder='big')
# remove all null bytes at the beginning
rbin = rbin.lstrip(b'\x00')
# if rbin has a high bit, add a \x00
if rbin[0] & 0x80:
rbin = b'\x00' + rbin
result = bytes([2, len(rbin)]) + rbin#1
sbin = self.s.to_bytes(32, byteorder='big')
# remove all null bytes at the beginning
sbin = sbin.lstrip(b'\x00')
# if sbin has a high bit, add a \x00
if sbin[0] & 0x80:
sbin = b'\x00' + sbin
result += bytes([2, len(sbin)]) + sbin
return bytes([0x30, len(result)]) + result#1 在python3 中,我們可以使用bytes([some_integer1, some_integer2])把一個數字的列表轉換成對應的字節。
總之這是一個非常不效率的編碼r和s的方案,至少有六個字節是不必要的。
4.4. Base 58
在比特幣早期,比特幣被放置在SEC未壓縮格式的公鑰上,並通過DER 簽名來解鎖進行交易。這種情況下使用非常簡單的腳本(srcipt)時,不僅在儲存未花費交易輸出(unspent transaction outputs UTXOs)上顯得浪費,也比現在比特幣廣泛使用的腳本更不安全,我們在將要討論的[第六章]中會解釋其原因。接下來我們會詳細介紹地址(address)是什麼,以及其如何編碼。
4.4.1. 轉錄你的公鑰
為了達成Alice 支付給Bob 的交易,Alice 必須知道她要把錢發送到哪裡去。這不僅僅是比特幣需要,所有的支付系統都需要。因為比特幣是一個不記名的數字票據工具,地址可以是類似於公鑰密碼學方案中的公鑰的東西。不幸的是SEC 格式尤其是未壓縮的版本,有些長(65 或者33 字節)。另外65或者33字節的SEC 公鑰格式是二進制格式,至少原文是不易閱讀的。
對此我們有三點考慮。第一,公鑰應該應該可讀性好(容易手寫,不容易出錯比如電話號碼)。第二是要短(不要太長導致難處理)。第三是安全(要求不容易出問題)。
所以我們如何才能實現可讀性,壓縮性和安全性呢?如果我們用16進制(每字符16個二進制比特)來表示SEC格式。這回導致長度加倍(130 或者 66個字符),我們能做的更好嗎?
我們可以使用類似Base64 的方法,Base64 每個字符代表6個比特。對於未壓縮SEC格式需要87個字符,壓縮SEC格式需要44 個字符。但是Base64 容易出錯,因為很多數字和字母長的非常相似(o和0,l和I,-和_)。如果我們去除掉這些字符,我們可以做到好的可讀性和優秀的壓縮率(大約每字符5.85 比特)。最後我們在結尾增加一個總和校驗(checksum)來保證能容易地檢測到錯誤。
這個構建過程被稱為Base58。我們使用Base58 對數字編碼,而不是hexadecimal(16進制)和Base64。 具體的base58編碼機制如下:
排除之前提到的 0/o 和l/I使用所有的大寫字母和小寫字母。可用字符總數為:10+26+26-4=58。每個Base58的字符都代表一個數字。我們可以通過如下方程來實現:
BASE58_ALPHABET = '123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz'
...
BASE58_ALPHABET = '123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz'
...
def encode_base58(s):
count = 0
for c in s:#1
if c == 0:
count += 1
else:
break
num = int.from_bytes(s, 'big')
prefix = '1' * count
result = ''
while num > 0:#2
num, mod = divmod(num, 58)
result = BASE58_ALPHABET[mod] + result
return prefix + result#3#1 這個循環體的目的是為了計算前綴有多少個0,並在最後加回去。 #2 這個循環體的目的是判斷使用Base58中的哪個字母 #3 最後,統計的原公鑰前綴的0,否則他們不會作為前綴的1出現。這種令人討厭的事情發生在[第六章]會討論的支付到公鑰雜湊(pay-to-pubkey-hash, p2pkh)
這個函數將把任意python3 中的字節轉換成base58編碼。
|
為什麼base58 過時了
Base 58使用了很長時間。的確和Base64比更容易溝通,但實際上並不方便。大部分人在使用傾向於複製粘貼。如果你嘗試通過念出來的方式傳遞Base58時,就能感受這是一個災難。 更好的方法是新的在BIP0173中確立Bech32 標準。Bech32 使用一個32個字符的字符表。包括數字和小寫,排除了1,b,i 和 o。目前該方案只在隔離見證交易(Segwit)中採用([Chapter13])。 |
4.4.2. Exercise 4
將一下十六進制數字轉換成二進制再轉換成Base58。
-
7c076ff316692a3d7eb3c3bb0f8b1488cf72e1afcd929e29307032997a838a3d
-
eff69ef2b1bd93a66ed5219add4fb51e11a840f404876325a1e8ffe0529a2c
-
c7207fee197d27c618aea621406f6bf5ef6fca38681d82b2f06fddbdce6feab6
4.4.3. 地址格式
壓縮後的SEC 格式仍然有264比特,仍然很長,而且在[第六章]我們還會討論其不安全的地方。為了縮短地址並且提高安全性。我們可以使用ripemd160hash。
和直接使用SEC 格式相比,我們可以把長度從33字節顯著地降低為20字節。以下是比特幣地址的生成規則: . 對於比特幣主鏈地址,採用 0x00前綴,測試連採用0x6f . 對SEC 格式(包括壓縮的和未壓縮的)做一次sha256運算,之後再做一次ripemd160運算。這兩次雜湊運算被稱為 一次hash160 運算。 . 將#1的前綴和#2 的結果拼接 . 對#3的結果做 一次hash256,並取其前四個字節 . 拼接#3 和#4的結果,使用Base58對其編碼
其中第四步的計算過程被稱為checksum,我們可以一行實現 第四步和第五步:
def encode_base58_checksum(b):
return encode_base58(b + hash256(b)[:4])|
什麼是測試鏈
測試鏈是程序員使用的與比特幣平行的網路。測試鏈上的幣沒有價值,新區塊需要的工作量證明的難度相對容易。主鏈在本書寫作時大概有550000區塊,測試鏈的高度顯著高於主鏈(大約1450000區塊)。 |
我們可以在helper.py 中實現 hash160:
def hash160(s):
'''sha256 followed by ripemd160'''
return hashlib.new('ripemd160', hashlib.sha256(s).digest()).digest()注意hashlib.sha256(s).deigest 實現了對應的的sha256,其周圍的封裝實現了ripemd160。
我們可以更新為S256Point增加hash160 和 address 方法:
class S256Point:
...
def hash160(self, compressed=True):
return hash160(self.sec(compressed))
def address(self, compressed=True, testnet=False):
'''Returns the address string'''
h160 = self.hash160(compressed)
if testnet:
prefix = b'\x6f'
else:
prefix = b'\x00'
return encode_base58_checksum(prefix + h160)4.4.4. Exercise 5
計算下面私鑰對應的公鑰和其對應的地址:
-
5002(使用未壓縮 SEC,測試鏈)
-
20205(使用壓縮 SEC,測試鏈)
-
0x12345deadbeef(使用壓縮 SEC,主鏈)
4.4.5. WIF 格式
在我們的情況中,私鑰是256位的數字。一般來說,我們通常不需要經常序列化我們的私鑰。私鑰也不需要廣播(廣播私鑰是非常糟糕的想法)。但在某些情況下,你可能需要傳輸私鑰-從一個錢包到另一個錢包,例如,從紙質錢包到軟體錢包。
為此,你可以使用錢包導入格式 (Wallet Import Format WIF)。WIF是是一個序列化私鑰的方法,這意味著WIF是人類可讀的的格式。與地址編碼一樣,WIF 使用Base58格式編碼。
下面是WIF格式的生成步驟:
-
對於主鏈的私鑰,以0x80為前綴。測試鏈使用0xef
-
大端序編碼私鑰為32字節
-
如果使用壓縮的SEC公鑰地址則增加後綴0x01
-
結合 #1的前綴 #2的序列化私鑰和#3的後綴
-
對#4的結果進行hash256,取其前四個字節
-
結合#4 和 #5 的結果,並對其base58編碼
我們可以在PrivateKey 類中添加wif 方法:
class PrivateKey
...
def wif(self, compressed=True, testnet=False):
secret_bytes = self.secret.to_bytes(32, 'big')
if testnet:
prefix = b'\xef'
else:
prefix = b'\x80'
if compressed:
suffix = b'\x01'
else:
suffix = b''
return encode_base58_checksum(prefix + secret_bytes + suffix)4.5. 再議大端序和小端序
我們瞭解大端序和小端序在python中如何實現是非常有用的。接下來的幾章將經常需要從大端序或者小端序來解析和序列化數字。特別是中本聰在比特幣的設計中使用了很多小端序。
不幸的是,並沒有沒有易於掌握的規則來判斷在哪裡使用小端序,在哪裡使用大端序。SEC 格式公鑰,地址和WIF使用大端序。但從[第 5 章]開始,將更多使用小端序。出於這個目的和之後方便使用,設計了下面的兩個練習。本節的最後一項練習是為自己創建一個測試鏈地址。
4.5.3. Exercise 9
你使用一個只有你自己知道的長私鑰創建一個測試鏈的地址。因為測試鏈也有很多偷取測試幣的機器人,所以這很重要。確保你的私鑰在某個地方寫了下來,因為你之後還需要使用它來簽名交易。
去測試幣領取網站為你的地址索要一些測試幣地址(應該以m 或者n 為前綴,其他情況則說明有錯誤)。如果成功實現,恭喜你!你應當為你成為測試幣擁有者感到驕傲!
5. 第五章 交易
交易是比特幣的核心。簡單的說,交易是從一個實體到另一實體的價值轉移。我們將在第六章中學習到這裡說的的實體事實上是智能合約,但這對我們來說還太早了。讓我們先瞭解一下比特幣中交易是什麼,長什麼樣子以及如何解析交易。
5.1. 交易的組成
從高層次看,一個交易只包含下面四個組成部分:
-
版本號(Version)
-
輸入(Inputs)
-
輸出(Outputs)
-
時間鎖(Locktime)
(譯注:因為Inputs 和outputs 有些抽象且作為交易的核心內容會經常使用,本書後續將不翻譯而直接使用原文inputs和outputs,這也符合區塊鏈中文技術社區的常規用法。)
我們對這幾個組成部分簡單的概括對後續討論會有幫助。版本號代表了交易要使用哪些額外的功能,input定義了哪些比特幣被花費,output定義了比特幣流向哪裡,鎖定時間定義了交易在什麼事件後才會生效。我們將詳細討論每個部分。
Figure 5-1 展示了一個典型交易的16進制數據和其數據對應所屬部分。

Figure 5-1. 交易組成部分:版本號,input,output和時間鎖
不同顏色高亮部分代表了對應的版本號,inputs,outputs和時間鎖。
瞭解上面的內容,我們就可以開始構建名為Tx的交易類:
class Tx:
def __init__(self, version, tx_ins, tx_outs, locktime, testnet=False):
self.version = version
self.tx_ins = tx_ins#1
self.tx_outs = tx_outs
self.locktime = locktime
self.testnet = testnet#2
def __repr__(self): tx_ins = ''
for tx_in in self.tx_ins:
tx_ins += tx_in.__repr__() + '\n'
tx_outs = ''
for tx_out in self.tx_outs:
tx_outs += tx_out.__repr__() + '\n'
return 'tx: {}\nversion: {}\ntx_ins:\n{}tx_outs:\n{}locktime: {}'.format(
self.id(),
self.version,
tx_ins,
tx_outs,
self.locktime
)
def id(self):#3
'''Human-readable hexadecimal of the transaction hash'''
return self.hash().hex()
def hash(self):#4
'''Binary hash of the legacy serialization'''
return hash256(self.serialize())[::-1]\#1 input 和output 是非常基礎的原生的組件,所以我們會指出input具體是什麼,並在之後定義這個對象的類型。
\#2 我們需要知道交易是在哪個網路上的,這樣才能完整地驗證交易。
\#3 id 欄位是區塊鏈瀏覽器查找交易時使用的索引,是交易的十六進制格式的hash256運算的結果。
\#4 這個hash函數返回對小端序的序列化數據的hash256運算結果。但我們目前還沒有實現序列化的函數,直到我們實現了這個函數,hash 函數才能被使用。
本章的其餘部分將討論如何解析交易。我們現在可以寫如下代碼:
class Tx:
...
@classmethod
def parse(cls, serialization):
version = serialization[0:4] ...\#1 這個方法必須是類方法。輸入序列化數據返回一個交易對象的實例。
\#2 我們默認serialization 的類型是一個byte array。
這當然能正常工作,但交易體積可能非常大。理想的情況,我們需要從流(stream)中解析。這使得我們沒有獲得全部序列化數據之前就能開始解析交易數據,也能讓我們提早發現錯誤來提高效率。因此一個解析交易的函數應該更像下面的代碼:
class Tx
...
@classmethod
def parse(cls, stream):
serialized_version = stream.read(4)
...\#1 read 方法允許我們實時地解析,因為我們不需要等待I/O寫入。
從工程角度來看,這是有利的,因為流可以是網路上的socket連接或文件句柄。我們可以在等待傳輸而不是讀取全部完成的情況下開始解析流數據。這個方法將能夠處理任何類型的流並返回我們需要的Tx對象。
5.2. 版本號
當你收到一個版本號(比如Figure 5-2 為例),這意味著告知接受者有關版本號代表的事物的信息。比如你啓動了window3.1 系統,這個版本顯著區別於windows 8和 windows 10。你也可以只說明你啓動的是windows,但是在操作系統後附加版本號信息將幫助你瞭解其特性和你的代碼可以使用的API。

Figure 5-2. 版本號
類似地,比特幣也有自己的版本號。在比特幣中,版本號一般為1,但也有一些會用到2做版本號的情況(交易使用了BIP0112 中定義的操作碼(opcode) OP_CHECKSEQUENCEVERIFY,需要使用大於1的版本號。)
你可能已經注意到實際上十六進制的版本號為01000000,看上去並不是1。但是版本號使用的是小端序,即版本號的值為1。(可以回顧第四章的相關討論)
5.3. 輸入
每個交易的input 都指向父交易(pervious tansaction)的 output(如圖 Figure 5-3)。直覺上這一開始看上去並不直觀,需要我們進一步解釋。
(譯注:譯者對pervious transaction 採用了’父交易’的翻譯,以強調其前後關聯和價值轉移的關係。但從交易角度講,比特幣的交易可以由多個input 和output 組成,所以會出現父交易的父交易也可以是你的父交易這種非常中世紀的情況。)

Figure 5-3.Inputs
比特幣的inputs 是在花費父交易的outputs。也就是說,在你花費掉比特幣之前你必須先收到一些比特幣。這也符合直覺。你不能花掉你還沒有收到的錢。input 指你擁有的比特幣,每個input 包含以下兩項:
-
一個你之前收到的比特幣的引用
-
證明這些比特幣屬於你
第二部分使用了ECDSA(第三章)。你肯定不希望別人能偷走你的比特幣,所以大部分的input 包含了只有對應的私鑰擁有者才能製作的簽名。
input欄位也可以包含不止一個input。做個類比,你可以使用一張100美元紙幣支付70美元的一頓飯,也可以使用一張50美元紙幣和一張20美元紙幣來支付。前者的支付方式只需要一個 input ,後者的支付方式需要兩個。還有一些情況,交易可能包含更多的input,比如使用14張5美元的紙幣來支付,甚至7000個一美分硬幣。在比特幣中相當於14個inputs 和 7000個inputs。
Figure 5-4中高亮了input的數量,位於版本號之後。

Figure 5-4. inputs的數量
我們可以看到其字節為01,這意味著交易只有一個input。這裡可能很容易假設它總是一個字節,但事實並非如此。單個字節有8個比特,因此任何超過255個inputs的情況都不能在單個字節中得以表達。
我們在這裡引入變長整數(varints)的機制。Varints 是varible integer 的縮寫,它提供從 0 到 264-1 的整數編碼成字節的方法。當然我們可以使用8個字節來編碼整數,但是當我們要編碼的數字相對比較小時(比如小於200),這會非常浪費空間。所以我們使用變長整數來節省空間。你可以在下面的欄目里學到變長整數是如何運作的。
5.3.1. 變長整數
變長整數採用如下規則
-
如果數字小於 253,使用一個字節編碼(比如 100→ 0x64)。
-
如果數字在 253 到 216-1 之間,以253對應的字節(fd)作為前綴,之後的兩個字節以小端序編碼數字(比如 255→ 0xfdff00, 555→ 0xfd2b02)。
-
如果數字在 216 到 232-1 之間,以254 對應的字節(fe)作為前綴,之後四個字節以小端序編碼數字(比如 70015→ 0xfe110100)。
-
如果數字在 232 到 264-1 之間,以255 對應的字節(ff)作為前綴,之後八個字節以小端序編碼數字(比如 18005558675309→ 0xff6dc7ed3e60100000)。
在helper.py 中的兩個函數將幫助你使用變長整數解析和序列化數字:
def read_varint(s):
'''read_varint reads a variable integer from a stream'''
i = s.read(1)[0]
if i == 0xfd:
# 0xfd means the next two bytes are the number
return little_endian_to_int(s.read(2))
elif i == 0xfe:
# 0xfe means the next four bytes are the number
return little_endian_to_int(s.read(4))
elif i == 0xff:
# 0xff means the next eight bytes are the number
return little_endian_to_int(s.read(8))
else:
# anything else is just the integer
return i
def encode_varint(i):
'''encodes an integer as a varint'''
if i < 0xfd:
return bytes([i])
elif i < 0x10000:
return b'\xfd' + int_to_little_endian(i, 2)
elif i < 0x100000000:
return b'\xfe' + int_to_little_endian(i, 4)
elif i < 0x10000000000000000:
return b'\xff' + int_to_little_endian(i, 8)
else:
raise ValueError('integer too large: {}'.format(i))read_varint 將從數據流中讀取並返回被編碼的整數。encode_varint 與此相反,入參整數返回變長整數編碼的字節。
每個input 包含四個欄位。前兩個欄位指向了父交易的output。後兩個欄位確保交易發起者可以使用父交易的output。四個欄位分別是: * 父交易的交易ID(Pervious transaction ID)
-
父交易output 的序號(Previous Transaction Index)
-
簽名腳本(ScriptSig)
-
序列號(Sequence)
如之前解釋過的,每個input會指向父交易的一個output。其中父交易的交易ID是對父交易內容的hash256運算結果。由於雜湊碰撞在概率上幾乎不可能,所以交易ID可以代表唯一的一筆交易。(譯注:所以中文社區中,交易ID更常見的叫法是交易雜湊。後文中也將採用’交易雜湊’代指’交易ID')。
我們之後會發現,每筆交易至少有一個Output,大部分情況是有不止一個Output。所以我們還需要指明我們使用的交易中的哪一個Output。這由父交易output 的交易序號來完成。
父交易雜湊有32個字節,父交易的交易序號有4個字節。兩者都是小端序。
簽名腳本和比特幣的智能合約語言相關,腳本(script)將會在第六章中詳細討論。目前可以把簽名腳本當作是要打開一個帶鎖的箱子,這個行為只能由父交易output 交易擁有者執行。和之前我們見到大部分的定長變量不同,簽名腳本是一個變長的欄位。一個變長欄位需要準確地聲明其需要的字節長度,這也就是為什麼變長整數需要在前綴表達其長度。
序列號起初是中本聰用來處理「高頻交易」的設計,和時間鎖配合使用(序列號和時間鎖)。目前的主要用途是處理手續費替代(Replace-By-Fee,RBF)和操作碼OP_CHECKSEQUENCEVERIFY。序列號是佔據4個字節的小端序。
(譯注:Replace-By-Fee,手續費替代的一個使用場景是一筆交易支付的手續費費用過低,遲遲沒有礦工幫助記賬。在不改變交易內容的情況下,使用更高的手續費來激勵礦工確認這筆交易。這個需求和功能很早就被考慮並在比特幣中實現,但也引入了一些問題,詳細討論可以參考 https://en.bitcoin.it/wiki/Replace_by_fee)
Input的各個欄位可以參考Figure 5-5。

Input的四個欄位:父交易雜湊,父交易output序號,簽名腳本,序列號
5.3.2. 序列號和時間鎖
在比特幣一開始設計時,中本聰希望序列號和時間鎖用來處理高頻交易。中本聰設想了一種支付場景,雙方小額多次支付,但不需要全部上鏈交易。比如如果Alice 支付給Bob x 個比特幣,處於某種原因,bob 也要向Alice 支付 y 個比特幣,假設 x>y,與其在鏈上生成兩筆交易,不如只讓Alice 支付給Bob一共 x-y 個比特幣。如果他們兩個之間有100筆交易,使用這種方法將能顯著壓縮交易次數為1次。
中本聰計劃這樣實現:參與交易的雙方持續維護一個小的賬本,直到最後在鏈上清算。 Satoshi的意圖是每當雙方之間發生新的付款時,使用序列和鎖定時間欄位來更新高頻交易。交易將有兩個input(一個屬於Alice,一個屬於Bob)和兩個output(一個屬於Alice,屬於來自Bob)。交易交易將從序列0開始,並具有非常長的鎖定時間(比如,從現在起500區塊,因在500區塊之後才會生效)。output的金額是Alice和Bob投入的金額相同。這被成為基礎交易(base transaction)。
在第一筆交易中,Alice 支付給Bob一共 x 個比特幣,每個input的序列號都為1。在第二筆交易中Bob 支付給Alice一共 y 個比特幣,每個input的序號為2。使用該方案,只要在鎖定期到達前,包括之後可以非常多的類似交易都可以壓縮成鏈上的一筆交易。
不幸的是,雖然這個設計非常優秀,但對礦工來說非常容易騙取比特幣。在我們的例子中,Bob 可以是一個礦工,他可以故意無視新的序號為2的交易,只記賬序列號為1的交易,從而從Alice 手中騙取了 y 個比特幣。
之後出現一個更優秀的設計:「支付通道」(payment channels),也是閃電網路(Lightning Network)的基礎。
我們已經瞭解input 的每個欄位,我們可以著手在python中設計 Txin 類了:
class TxIn:
def __init__(self, prev_tx, prev_index, script_sig=None, sequence=0xffffffff):
self.prev_tx = prev_tx
self.prev_index = prev_index
if script_sig is None:#1
self.script_sig = Script()
else:
self.script_sig = script_sig
self.sequence = sequence
def __repr__(self):
return '{}:{}'.format(
self.prev_tx.hex(),
self.prev_index,
)\#1 簽名腳本的缺省值為空。
這裡我們需要注意幾件事情。首先是我們並沒有指明每個input代表了多少比特幣,除非在區塊鏈上查找我們要使用的父交易的output,否則不知道input 代表多少比特幣。而且在不知道父交易的情況下,我們甚至也不知道交易是否解鎖了正確的箱子。每個節點必須驗證這些交易解鎖了正確的箱子,沒有花費不存在的比特幣。如何實現驗證我們在第七章進一步討論。
5.3.3. 解析腳本
我們將在第六章詳細討論如何解析腳本。目前來說,可以使用下面的代碼解析交易,從16進制數據中獲取一個Script 對象。
>>> from io import BytesIO
>>> from script import Script#1
>>> script_hex = ('6b483045022100ed81ff192e75a3fd2304004dcadb746fa5e24c5031ccf
cf21320b0277457c98f02207a986d955c6e0cb35d446a89d3f56100f4d7f67801c31967743a9c8
e10615bed01210349fc4e631e3624a545de3f89f5d8684c7b8138bd94bdd531d2e213bf016b278
a')
>>> stream = BytesIO(bytes.fromhex(script_hex))
>>> script_sig = Script.parse(stream)
>>> print(script_sig)
3045022100ed81ff192e75a3fd2304004dcadb746fa5e24c5031ccfcf21320b0277457c98f0220
7a986d955c6e0cb35d446a89d3f56100f4d7f67801c31967743a9c8e10615bed01 0349fc4e631
e3624a545de3f89f5d8684c7b8138bd94bdd531d2e213bf016b278a\#1 Script 類將在第六章進行更詳細的討論。目前請想起Script.parse方法可以正常使用,返回我們需要的對象。
5.4. 輸出
如上一個節提示的那樣,output定義了比特幣流向了哪裡。每個交易至少有一個或者多個output。為什麼交易會有多個output 呢?交易所會使用合併提款,比如一次支付給多個人而不是每個人都通過一次交易來其發送要求提出的比特幣。
和input一樣,output 的序列化也需要在首先使用變長整數聲明有多少個output。如圖Figure 5-6。

Figure 5-6 Output 的數量
每個output 包含兩個欄位:amount和公鑰腳本(ScriptPubKey)。amount 欄位指以聰為單位轉賬的比特幣數量,1聰等於 1/100000000 個比特幣。這使得比特幣可以分割成非常小的單位,在本書寫作時,1聰價值大約為 1/300 美分。比特幣的絕對數量上限約為21000000個比特幣,換算成聰為2,100,000,000,000,000聰。這個數字略微小於 232,因此使用64比特或者8個字節就足夠儲存了。amount以小端序序列化。
(譯注:比特幣每區塊產出50個比特幣,每210,000個區塊減半(約四年)。那麼比特幣上限是一個簡單的數學問題,一個無窮的等比數列求和並不難計算出2100萬的上限。但要注意比特幣並不能無窮細分,最小單位為1聰。當減半後小於1聰時,會不再產出新的比特幣。總計為20999999.97690000個比特幣)
公鑰腳本和簽名腳本類似,和比特幣的智能合約語言相關。可以把公鑰腳本理解成給箱子加鎖,只能被掌握鑰匙的人打開。這是一個單向的安全設計,可以接受任何人的轉賬,但只能由保險箱的所有者打開。我們將在第六章進一步討論。和簽名腳本一樣,公鑰腳本有一個變長的欄位,並有一個變長整數作為前綴來表明其長度。
圖Figure 5-7是一個完整的output的例子:

一個完整的output欄位:數量和公鑰腳本---這個ouput 的序號為0
5.4.1. UTXO 集合
UTXO 是unspent transaction output(未使用的output)。對於某個時刻的全部的未使用的Output,我們稱為UTXO集。 UTXO集非常重要,對於任意給定的時刻,對應的UTXO集代表這時可以使用的比特幣。另一個角度理解,UTXO集代表了流通中的比特幣。網路全節點會維護UTXO集合的變動和UTXO的索引,這樣會使驗證交易的效率顯著提高。
比如,很容易通過搜索UTXO集來避免雙花交易。如果一個交易使用了UTXO集合中不存在的output,這意味者出現了雙花交易的攻擊或者使用了不存在的Output,所以交易是非法的。自己維護UTXO集合對於交易驗證是非常有幫助的。在第六章中,我們需要查找父交易output的數量和公鑰腳本來驗證交易,所以掌握UTXO集合能提高交易的驗證效率。
(譯注:雙花交易:使用同一個UTXO的兩個交易,被稱為雙花交易,比特幣作為支付系統,需要通過共識來消除雙花交易,決定其中哪一筆是合法的)
現在我們可以開始編寫TxOut 類了:
class TxOut:
def __init__(self, amount, script_pubkey):
self.amount = amount
self.script_pubkey = script_pubkey
def __repr__(self):
return '{}:{}'.format(self.amount, self.script_pubkey)5.5. 時間鎖
時間鎖(locktime)是實現延時交易的一個工具。一個有600000區塊的時間鎖的交易,直到區塊高度為600001時才能進入區塊鏈。設計的目的本是為了便於高頻交易(參考 序列號和時間鎖),但因為不安全而放棄了。如果時間鎖的數字大於等於500,000,000是,locktime 解析為Unix時間戳。如果小於則解析為區塊高度。也就是被簽名交易處於不能使用的狀態,知道到達對應的區塊高度或者Unix 時間戳。
|
時間鎖不生效的情況
如果每個input 的序列號都是ffffffff,時間鎖將不生效。 |
時間鎖以小端序佔4個字節(Figure 5-8):

Figure 5.8 時間鎖
實踐中,時間鎖的主要問題是在時間鎖過期後不能確保交易會執行。這與遠期支票類似,存在餘額不足、支票無法兌付的可能性。交易的發起者可以在鎖定期結束前使用對應的Input並使交易進入區塊鏈。因此帶時間鎖的交易會在時間鎖過期後變成失效交易。
在BIP065實施之前,locktime 的使用非常有限。BIP0065 引入了OP_CHECKLOCKTIMEVERIFY操作符,附帶locktime 的output 將不會被提前花費掉,這提高locktime 的可用性。
5.5.2. Exercise 5
在以下交易中,找到:第二個input的簽名腳本;第一個output的公鑰腳本;第二個output 的數量。
010000000456919960ac691763688d3d3bcea9ad6ecaf875df5339e148a1fc61c6ed7a069e0100
00006a47304402204585bcdef85e6b1c6af5c2669d4830ff86e42dd205c0e089bc2a821657e951
c002201024a10366077f87d6bce1f7100ad8cfa8a064b39d4e8fe4ea13a7b71aa8180f012102f0
da57e85eec2934a82a585ea337ce2f4998b50ae699dd79f5880e253dafafb7feffffffeb8f51f4
038dc17e6313cf831d4f02281c2a468bde0fafd37f1bf882729e7fd3000000006a473044022078
99531a52d59a6de200179928ca900254a36b8dff8bb75f5f5d71b1cdc26125022008b422690b84
61cb52c3cc30330b23d574351872b7c361e9aae3649071c1a7160121035d5c93d9ac96881f19ba
1f686f15f009ded7c62efe85a872e6a19b43c15a2937feffffff567bf40595119d1bb8a3037c35
6efd56170b64cbcc160fb028fa10704b45d775000000006a47304402204c7c7818424c7f7911da
6cddc59655a70af1cb5eaf17c69dadbfc74ffa0b662f02207599e08bc8023693ad4e9527dc42c3
4210f7a7d1d1ddfc8492b654a11e7620a0012102158b46fbdff65d0172b7989aec8850aa0dae49
abfb84c81ae6e5b251a58ace5cfeffffffd63a5e6c16e620f86f375925b21cabaf736c779f88fd
04dcad51d26690f7f345010000006a47304402200633ea0d3314bea0d95b3cd8dadb2ef79ea833
1ffe1e61f762c0f6daea0fabde022029f23b3e9c30f080446150b23852028751635dcee2be669c
2a1686a4b5edf304012103ffd6f4a67e94aba353a00882e563ff2722eb4cff0ad6006e86ee20df
e7520d55feffffff0251430f00000000001976a914ab0c0b2e98b1ab6dbf67d4750b0a56244948
a87988ac005a6202000000001976a9143c82d7df364eb6c75be8c80df2b3eda8db57397088ac46
4306005.6. 實現交易的序列化
我們已經實現瞭解析交易的功能。現在我們反過來進行交易的序列化,首先從TxOut 開始:
class TxOut:
def serialize(self):#1
'''Returns the byte serialization of the transaction output'''
result = int_to_little_endian(self.amount, 8)
result += self.script_pubkey.serialize()
return result\#1 我們將要把交易序列化成字節。
接下來我們處理TxIn:
class TxIn:
...
def serialize(self):
'''Returns the byte serialization of the transaction input'''
result = self.prev_tx[::-1]
result += int_to_little_endian(self.prev_index, 4)
result += self.script_sig.serialize()
result += int_to_
int_to_little_endian(self.sequence, 4)
return result最後我們序列化Tx:
class Tx:
...
def serialize(self):
'''Returns the byte serialization of the transaction'''
result = int_to_little_endian(self.version, 4)
result += encode_varint(len(self.tx_ins))
for tx_in in self.tx_ins:
result += tx_in.serialize()
result += encode_varint(len(self.tx_outs))
for tx_out in self.tx_outs:
result += tx_out.serialize()
result += int_to_little_endian(self.locktime, 4)
return result序列化的過程中我們使用了TxIn 和 TxOut 類的serialize 方法。
注意,交易手續沒有出現,這是因為交易手續費是隱含的金額,我們將在下一節中講到。
5.7. 交易手續費
比特幣的共識規則之一:任何非coinbase 交易(在第九章 討論)Input的總額要大於output 的總額。為什麼兩者不相等呢?這是因為如果每個交易都是0成本的,礦工將沒有動力在區塊內打包交易(參考第九章)。交易手續費用來激勵礦工打包交易。不在區塊內的交易(被稱為mempool 交易)並不是區塊鏈的一部分,交易也就沒有完成。
(譯注:有關礦工激勵:mempool 可以理解為礦工節點的交易備選儲存池,由於區塊的交易上限是按照儲存體積約束,礦工會以BTC/kb 排序,優先打包支付更多手續費的交易。此外,比特幣礦池出現過支付美元來加速交易的業務,以比特幣系統外的資產激勵礦工優先打包交易進區塊)
交易手續費的計算方式非常簡單,交易的所有Input金額之和減去所有的Output金額之和。礦工獲取差值作為手續費。由於Input沒有金額欄位,需要我們自己查找金額。這需要我們能夠獲取區塊鏈數據,尤其是UTXO集。如果沒有運行全節點就會變得非常棘手,因為你不得不信任其他的實體為你提供相關信息。
我們創建一個新的類TxFetcher來處理這個問題:
class TxFetcher:
cache = {}
@classmethod
def get_url(cls, testnet=False):
if testnet:
return 'http://testnet.programmingbitcoin.com'
else:
return 'http://mainnet.programmingbitcoin.com'
@classmethod
def fetch(cls, tx_id, testnet=False, fresh=False):
if fresh or (tx_id not in cls.cache):
url = '{}/tx/{}.hex'.format(cls.get_url(testnet), tx_id)
response = requests.get(url)
try:
raw = bytes.fromhex(response.text.strip())
except ValueError:
raise ValueError('unexpected response: {}'.format(response.text))
if raw[4] == 0:
raw = raw[:4] + raw[6:]
tx = Tx.parse(BytesIO(raw), testnet=testnet)
tx.locktime = little_endian_to_int(raw[-4:])
else:
tx = Tx.parse(BytesIO(raw), testnet=testnet)
if tx.id() != tx_id:
raise ValueError('not the same id: {} vs {}'.format(tx.id(),
tx_id))
cls.cache[tx_id] = tx#1
cls.cache[tx_id].testnet = testnet
return cls.cache[tx_id]\#1在這裡通過檢查雜湊來確保是我們想要獲取的交易信息。
你可能會奇怪,為什麼我們不直接向節點直接索要父交易的output而是獲取了整個交易。原因是我們能不信任第三方數據。通過獲取交易的完整信息,我們可以通過交易雜湊(交易數據的hash256)來確保這是我們要獲取的交易。除非我們獲取交易的全部信息,否則不能實現這一點。
|
為什麼對第三方要最小信任
正如尼克·薩博(Nick Szabo)在他的極具影響力的論文「信任第三方是安全漏洞」中所說,信任第三方提供正確的數據不是一個好的安全措施。 第三方可能是現在表現得很好,但你永遠不知道什麼時候可能被黑客入侵、有一個流氓惡意員工,或者開始實施違背你的利益的政策。 比特幣安全的部分原因並非信任,而是驗證提供的的數據。 (譯注:Nick Szabo被認為是智能合約的最早發明者。目前仍然活躍在社區中。) |
現在我們可以在TxIn 類中編寫獲取父交易和其output的金額和公鑰腳本的方法了(在之後第六章會使用這些方法)。
class TxIn:
...
def fetch_tx(self, testnet=False):
return TxFetcher.fetch(self.prev_tx.hex(), testnet=testnet)
def value(self, testnet=False):
'''Get the output value by looking up the tx hash.
Returns the amount in satoshi.
'''
tx = self.fetch_tx(testnet=testnet)
return tx.tx_outs[self.prev_index].amount
def script_pubkey(self, testnet=False):
'''Get the ScriptPubKey by looking up the tx hash.
Returns a Script object.
'''
tx = self.fetch_tx(testnet=testnet)
return tx.tx_outs[self.prev_index].script_pubkey6. 第六章 Script
鎖定和解鎖比特幣的權限即是我們轉移比特幣的機制。鎖定是指給某些實體一些比特幣。解鎖是指花費掉你收到的比特幣。
在本章中,我們將研究通常稱為智能合約的鎖定/解鎖機制。Script使用橢圓曲線密碼學(第3章)來驗證交易是否有權使用對應的比特幣(第5章)。Script本質上是上允許人們證明他們有權使用某些UTXO。對我們來說討論這些還太早,讓我們從腳本的工作方式開始並以此作為基礎,理解腳本的功能。
6.1. 腳本機制
如果你對智能合約(smart contract)的定義產生困惑,請不要擔心。 「智能合約」是「可編程」(programmable)的花哨說法,而「智能合約語言」只是一種編程語言。在比特幣中,Script是智能合約語言,或者說用於表達比特幣可使用條件的編程語言。
在Script中,比特幣和合約是對應關係。Script是一種類似於Forth的基於棧的語言。它故意限制語言的功能,在某種意義上它拋棄了某些特性。具體來說,Script限制了循環體,因此不是圖靈完備的。
|
為什麼比特幣不是圖靈完備的
一個編程語言的圖靈完備指的是有能力處理循環。循環體在編程語言中非常有用,所以你可能會好奇為什麼Script不支持循環體。 這有很多原因。讓我們先從程序的執行開始。任何人都可以創建一個Script程序並在使得網路上的全節點可以運行。如果Script 是圖靈完備的,那麼有可能程序在循環體中永遠不會終止。這會導致驗證節點運行程序時一直處於循環體中。這也是一種容易進行的拒絕服務攻擊(DoS)。一個無限循環的Script會導致整個比特幣網路停止服務!這將是一個很大的系統漏洞,防範此漏洞是沒有實現圖靈完備的主要原因之一。以太坊(Ethereum)在其智能合約語言Solidity 中實現了圖靈完備。以太坊合約執行要求對計算資源的gas進行收費。一個無限循環的代碼將會窮盡合約執行的gas,因為根據合約的定義,會運行無限次。 另一個要限製圖靈完備的原因是圖靈完備的智能合約非常難分析。一個圖靈完備的智能合約的執行環境非常難以窮舉,因此容易出現一些意外的行為和漏洞。在智能合約中的漏洞意味著無意中花費了資產,合約的參與者會受到經濟損失。這樣的漏洞並不是空想的:這也是DAO的主要問題(分散化自治組織),圖靈完備的智能合約最後導致以太坊經典硬分叉。 (譯注: DAO是一個基於以太坊眾籌的項目,眾籌使用了以太坊的智能合約功能,DAO自己編寫的合約中的漏洞被黑客攻擊。以太坊社區決定回滾區塊鏈來解決問題,這一方案最終導致社區和部分礦工分裂出ETC(ethereum classic以太經典),ETC認可此次攻擊結果。這次分叉也引發了很多合約安全之外的討論,比如公鏈項目是否要為平台中的一個項目買單、代碼即法律的設計理念是否合理等) |
交易這一行為將比特幣轉移到一個鎖定的腳本上。鎖定的腳本在公鑰腳本欄位(參考第五章)裡面。可以把它當作一個有比特幣的帶鎖箱子,只有特定的鑰匙才能的打開它。在盒子里的錢自然也只能被掌握鑰匙的使用。
箱子的解鎖過程由簽名腳本(參考第五章)實現。它能證明這個帶鎖的箱子的所屬權,有權使用盒子內資金。
6.2. Script如何運作
Script 是一個程序語言,和大部分程序語言一樣,每次只執行一個指令。這些指令用來對棧內的元素進行計算。有兩種類型的指令:元素(elements)和運算(operations)。
元素指數據。從技術上講,處理一個元素指將元素推送到堆頂。元素是長度為1到520字節的字符串。一個典型的元素是DER 簽名或者一個SEC格式的公鑰Figure 6-1。

Figure 6-1. 元素
運算指對數據的計算(Figure 6-2)。運算消耗堆頂0個或者多個元素並壓入0個或者多個元素回棧頂。

Figure 6-2. 運算
一個典型的運算是 OP_DUP(Figure 6-3),複製堆頂的一個元素(消耗0個堆頂元素),然後將其壓入棧頂(入棧一個元素)。

Figure 6-3. OP_DUP 複製堆頂的元素
當所有的指令都執行完成時,棧頂的元素必須是非零的,使腳本解析為有效。棧中沒有元素或頂部元素為0將解析為無效。解析為無效意味著包含著該解鎖腳本的交易不被比特幣網路接受。
6.3. 幾個運算的例子
除了OP_DUP之外還有很多其他運算。OP_HASH160(Figure 6-4)指對棧頂的元素做sha256(消耗1個堆頂元素)運算後再進行一次ripemd160(也就是一個hash160)運算並將結果壓入棧(入棧一個元素)。注意在下圖中, y=hash160(x)。

Figure 6-4. OP_HASH160 :對堆頂元素依次做sha256 和ripemd160 計算
另一個非常重要的運算是OP_CHECKSIG(Figure 6-5)。OP_CHECKSIG 消耗兩個堆頂的元素,第一個是公鑰,第二個是簽名,OP_CHECKSIG運算檢測簽名是否符合公鑰。如果符合,則在堆頂壓入1,否在在堆頂壓入0。

Figure 6-5 OP_CHECKSIG 檢測簽名是否符合公鑰
6.3.1. 實現運算符(Opcodes)
對於給定棧,實現OP_DUP並不困難。OP_DUP只是簡單的複製堆頂的一個元素:
def op_dup(stack):
if len(stack) < 1:#1
return False
stack.append(stack[-1])#2
return True
...
OP_CODE_FUNCTIONS = {
...
118: op_dup,#3
...
}\#1 至少堆頂存在一個元素,否則不能執行這個運算符。 \#2 複製堆頂的一個元素並壓入棧。 \#3 118=0x76 是OP_DUP的運算符。
值得注意的是,我們返回一個布爾值來辨別運算符是否正常運算。一個失敗的運算符會終止腳本的計算。
下面是OP_HASH256的運算符實現。這個運算符會消耗堆頂的一個元素,對其進行hash256運算,返回結果並壓入堆頂:
def op_hash256(stack):
if len(stack) < 1:
return False
element = stack.pop()
stack.append(hash256(element))
return True
...
OP_CODE_FUNCTIONS = {
...
170: op_hash256,
...
}6.4. 解析腳本和其欄位
不論公鑰腳本還是簽名腳本,都使用相同的方法解析。如果其字節在0x01 在 0x4b之間(我們稱其值為 n),接下來的n個字節將被視為元素。相對應的其他情況,字節代表一個運算符,需要查找映射表。以下是一些運算和其對應的字節碼:
-
0x00 - OP_0
-
0x51 - OP_1
-
0x60 - OP_16
-
0x76 - OP_DUP
-
0x93 - OP_ADD
-
0xa9 - OP_HASH160
-
0xac - OP_CHECKSIG
還有很多其他的運算符,在op.py文件中可以查看對應實現。此外完整的對應表可以參考at https://en.bitcoin.it/wiki/Script。
|
長度超過75字節的元素
如果出現長度超過0x4b字節(十進制為75)的元素該如何處理呢?比特幣設計了三個操作符處理這種情況:OP_PUSHDATA1,OP_PUSHDATA2,OP_PUSHDATA4。OP_PUSHDATA1指接下來的一個字節的數字作為長度,代表之後該長度的字節視為元素。OP_PUSHDATA2 接下指來兩個字節作為長度,代表之後該長度的字節視為元素。OP_PUSHDATA4指接下來的四個字節的數字作為長度,代表之後該長度的字節視為元素。 具體實踐上,如果入棧一個長度在76到255閉區間範圍內字節,使用如下指令:OP_PUSHDATA1 <1-byte length of the element> <element>。如果在256到520閉區間範圍內則使用OP_PUSHDATA2 <2-byte length of the element in little-endian> <element>。任何大於520字節的元素是不被比特幣網路允許的,所以使用OP_PUSHDATA4是沒有必要的。但是如下使用也是合法的:OP_PUSHDATA4 <4-byte length of the element in little-endian, but value less than or equal to 520> <element>。 然而,這些都是非標準交易的內容,這意味著比特幣的節點(尤其是使用Bitcoin Core開發的節點)不會接受這筆交易。 |
6.4.1. 實現一個Script解析工具和序列化工具
我們已經討論了Script是如何運作的。我們可以實現一個腳本的解析器:
class Script:
def __init__(self, cmds=None):
if cmds is None:
self.cmds = []
else:
self.cmds = cmds#1
...
@classmethod
def parse(cls, s):
length = read_varint(s) #2
cmds = []
count = 0
while count < length:#3
current = s.read(1)#4
count += 1
current_byte = current[0]#5
if current_byte >= 1 and current_byte <= 75:#6
n = current_byte
cmds.append(s.read(n))
count += n
elif current_byte == 76:#7
data_length = little_endian_to_int(s.read(1))
cmds.append(s.read(data_length))
count += data_length + 1
elif current_byte == 77:#8
data_length = little_endian_to_int(s.read(2))
cmds.append(s.read(data_length))
count += data_length + 2
else:#9
op_code = current_byte
cmds.append(op_code)
if count != length:#10
raise SyntaxError('parsing script failed')
return cls(cmds)\#1 每個指令不是一個需要執行的運算就是一個要壓入棧的一個元素。
\#2 腳本序列化需要先考慮腳本的長度。
\#3 一直解析腳本,直到消耗完所有的字節。
\#4 這個字節決定我們要解析的是運算還是元素。
\#5 從字節轉換成python中的整數。
\#6 對於一個在數字為1到75閉區間的字節,我們知道接下來 n 個字節是元素。
\#7 76指 OP_PUSHDATA1,接下來一個字節會指出其之後的元素的長度。
\#8 77指 OP_PUSHDATA2,接下來兩個字節會指出其之後的元素的長度。
\#9 保存操作符
\#10 至此應該完全消耗了我們計劃的腳本的字節數量。否則,我們會拋出一個異常。
類似地,我們也可以實現腳本的序列化工具:
class Script:
...
def raw_serialize(self): result = b''
for cmd in self.cmds:
if type(cmd) == int:#1
result += int_to_little_endian(cmd, 1)
else:
length = len(cmd)
if length < 75:#2
result += int_to_little_endian(length, 1)
elif length > 75 and length < 0x100:#3
result += int_to_little_endian(76, 1)
result += int_to_little_endian(length, 1)
elif length >= 0x100 and length <= 520:#4
result += int_to_little_endian(77, 1)
result += int_to_little_endian(length, 2)
else:#5
raise ValueError('too long an cmd')
result += cmd
return result
def serialize(self):
result = self.raw_serialize()
total = len(result)
return encode_varint(total) + result#6\#1 如果指令是一個整數,說明這是一個操作符。
\#2 如果長度在1到75 的閉區間內元素,將其長度編碼成一個字節。
\#3 對於長度在76到255 閉區間的元素,先將操作符OP_PUSHDATA1 操作符壓入棧,之後將其長度編碼成一個字節,再附加元素的數據。
\#4 對於長度在256到520 閉區間的元素,先將操作符OP_PUSHDATA2 操作符壓入棧,之後將其長度編碼成兩個字節,再附加元素的數據。
\#5 長度超過520的元素不能被序列化。
\#6 腳本序列化要前綴腳本的長度。
我們在此實現的解析和序列化工具也是我們在第五章中使用的,用來解析簽名腳本和公鑰腳本欄位。
6.5. 合併腳本
Script 對象指那些需要求值的指令集。計算一個腳本我們需要合併簽名腳本和公鑰腳本。密碼箱(公鑰腳本)和解鎖機制(簽名腳本)在不同的兩個交易內。即密碼箱在收到比特幣的交易內,解鎖腳本在使用這筆比特幣的交易內。使用比特幣的交易會指向之前接收比特幣的交易。即如下圖Figure 6-6的情形。
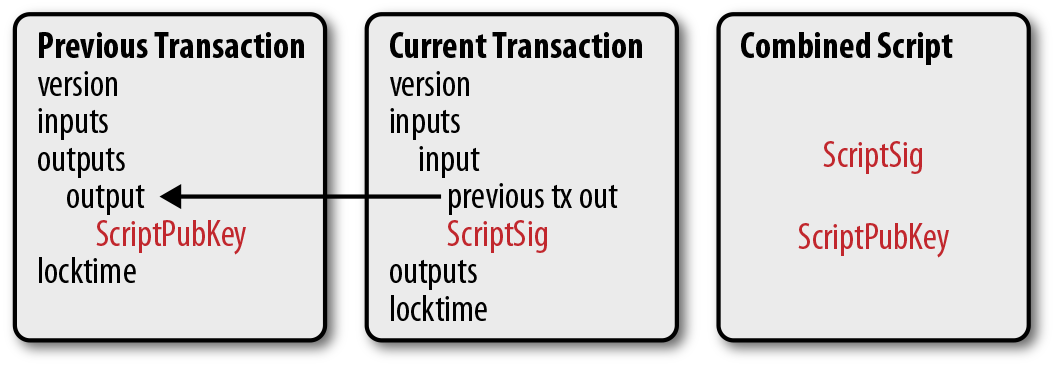
Figure 6-6. 合併簽名腳本和公鑰腳本
因為簽名腳本能解鎖公鑰腳本,我們需要一個機制能使二者合併。為了使之一起計算,我們把兩者的指令如圖Figure 6-6合併。簽名腳本中的指令位於公鑰的指令之前。依次處理指令,直到所有的指令都被處理(或腳本執行失敗)。
6.6. 標準腳本
比特幣中非常多標準的腳本,包括:
-
p2pk pay-to-pubkey (支付到公鑰)
-
p2pkh pay-to-pubkey-hash (支付到公鑰雜湊)
-
p2sh Pay-to-script-hash (支付到腳本雜湊)
-
p2wpkh Pay-to-withness-pubkey-hash(支付到隔離驗證公鑰雜湊)
-
p2wsh Pay-to-witness-script-hash(支付到隔離驗證腳本雜湊)
所謂的地址與上面的這些腳本模版相對應。錢包知道如何解析我們的地址類型(p2pkh,p2sh,p2wpkh)以及創建相應的公鑰腳本。所有上面的例子都有特定的地址格式(Base58,Bech32),因此錢包會知道如何支付給這些地址。
為了瞭解所有這些腳本如何運作,我們將從最原始的一類腳本出發,pay-to-pubkey。
6.7. p2pk
Pay-to-pubkey (p2pk) 類型的交易在比特幣的早期被廣泛使用。屬於中本聰的大部分比特幣都是p2pk 類型的UTXO,即交易的output中的公鑰腳本是p2pk類型的。我們會在p2pk的缺陷小節中討論p2pk 的一些限制。但是首先我們先瞭解p2pk是如何運作的。
在第三章中我們討論過ECDSA 的簽名和驗證。驗證一個ECDSA簽名需要簽名消息 z,公鑰 P,和簽名 r,s。在p2pk類型的交易中,比特幣被發送到一個公鑰。擁有其私鑰的人可以通過構造簽名解鎖並使用比特幣。交易的公鑰腳本通過這樣的方式將比特幣轉移給私鑰擁有者。
指出比特幣的去向是公鑰腳本負責的——也就是接受比特的密碼箱。p2pk的公鑰腳本如圖Figure 6-7所示

Figure 6-7. Pay-to-pubkey 公鑰腳本
注意,操作符 OP_CHECKSIG 非常重要。簽名腳本負責解鎖收到的比特幣。公鑰可以是壓縮格式或者非壓縮的格式的。但是由於在比特幣的早期歷史中使用的主流交易格式是p2pk,未壓縮格式是當時唯一選擇。
對於p2pk交易,用來解鎖公鑰腳本所需要的簽名簽名腳本由一個簽名長度字節和簽名信息表示,如圖Figrue 6-8所示。

Figure 6-8. Pay-to-pubkey 簽名腳本
我們合併公鑰腳本和簽名腳本成一個指令集如圖Figure 6-9:
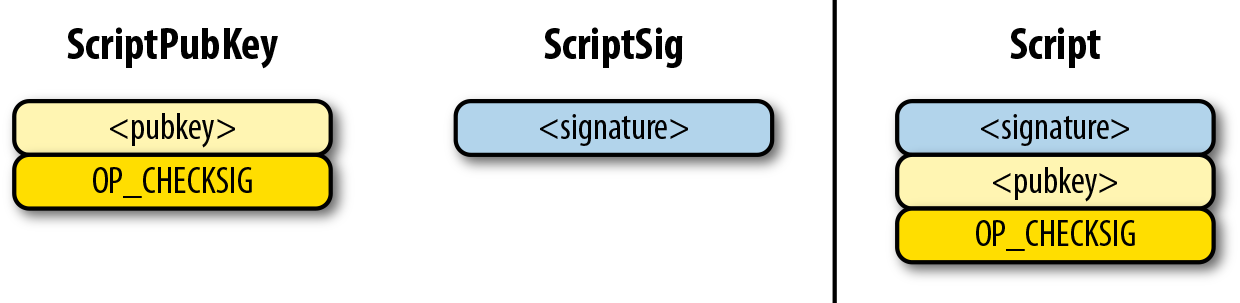
Figure 6-9. p2pk 合併
圖Figure 6-10中的兩列分別是腳本指令和棧。在計算結束後,棧頂必須是一個非0 的元素是才認為是一個有效的簽名腳本。 Script 每次執行一個指令,在圖Figure 6-10中,我們從圖Figure 6-9的合併後的腳本開始計算。
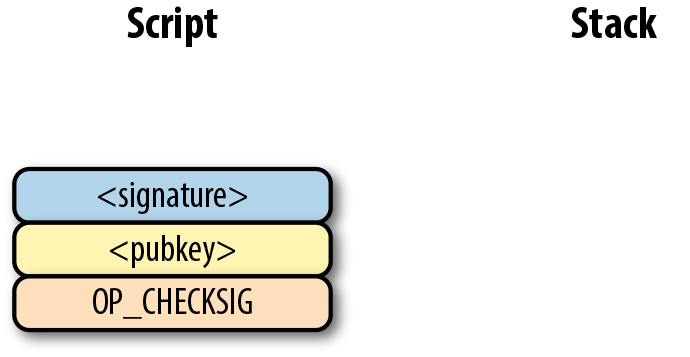
Figure 6-10. p2pk 開始計算
第一個指令是簽名,類型是元素。這個數據因此被壓入棧(Figure 6-11)。
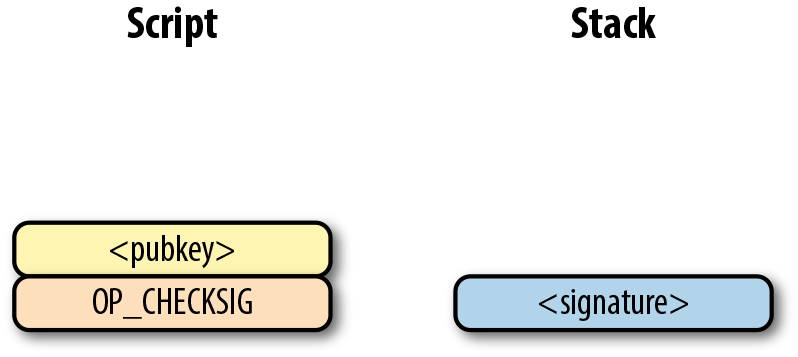
Figure 6-11. p2pk 計算的第一步
第二個指令是公鑰,也是一個元素,也會被壓入棧中。(Figure 6-12)。
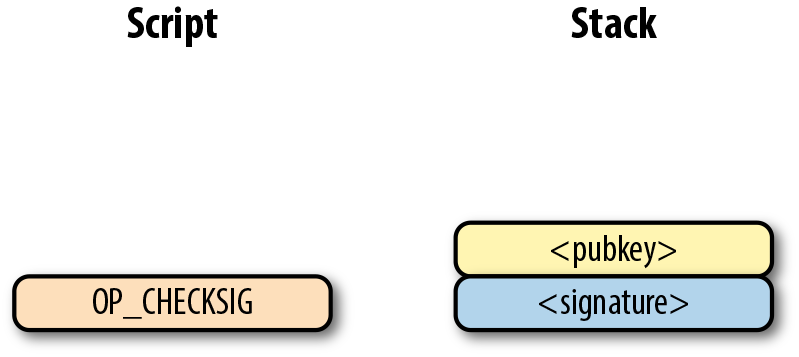
Figure 6-12. p2pk計算的第二步
OP_CHECKSIG 是消耗兩個棧元素的指令並決定這筆交易是否有效。如果對應的簽名是有效的,則加入1入棧,否則壓入0。如果簽名匹配公鑰,結果會如圖Figure 6-13所示。

Figure 6-13. p2pk 第四步
至此我們已經完成了腳本的計算,最終棧上只有一個元素。因為棧頂的元素不為0,所以這個腳本是有效的。
如果交易的簽名是不合法的,則OP_CHECKSIG會返回0,並結束腳本的計算。(如圖Figure 6-14)。

Figure 6-14. p2pk 結束計算
如果棧頂為0,則合併的腳本是不合法的,交易的input 中的簽名腳本也是無效的。
合併的腳本將驗證簽名是否有效,如果簽名無效則失敗。如果簽名對該公鑰有效,簽名腳本將解鎖公鑰腳本。換句話說,只有知道私鑰的人才能生成有效的簽名腳本。
順便說一下,我們可以看到公鑰腳本(ScriptPubkey)的名字。非壓縮SEC格式的公鑰是ScriptPubKey中p2pk的主要指令(另一個指令是OP_CHECKSIG)。類似地,簽名腳本(ScriptSig)也是這樣命名的,因為p2pk的簽名腳本的簽名是DER格式的。
6.7.1. 實現腳本計算
我們現在實現一種計算腳本的方法。要求完成每個指令並得出腳本是否有效。我們希望能夠完成類似下面的計算:
>>> from script import Script
>>> z = 0x7c076ff316692a3d7eb3c3bb0f8b1488cf72e1afcd929e29307032997a838a3d
>>> sec = bytes.fromhex('04887387e452b8eacc4acfde10d9aaf7f6d9a0f975aabb10d006e4da568744d06c61de6d95231cd89026e286df3b6ae4a894a3378e393e93a0f45b666329a0ae34')
>>> sig = bytes.fromhex('3045022000eff69ef2b1bd93a66ed5219add4fb51e11a840f404876325a1e8ffe0529a2c022100c7207fee197d27c618aea621406f6bf5ef6fca38681d82b2f06fddbdce6feab601')
>>> script_pubkey = Script([sec, 0xac])#1
>>> script_sig = Script([sig])
>>> combined_script = script_sig + script_pubkey#2
>>> print(combined_script.evaluate(z))#3
True\#1 p2pk 的簽名腳本由SEC格式的公鑰和OP_CHECKSIG操作符構成。OP_CHECKSIG 的編碼為 0xac 或者172。
\#2 因為我們之前實現了add重載,所以可以這樣合併腳本。
\#3 運行指令來判斷腳本是否有效。
下面的代碼是我們們用來實現合併腳本的計算(父交易的公鑰腳本和當前交易的簽名腳本):
from op import OP_CODE_FUNCTIONS, OP_CODE_NAMES
...
class Script:
...
def evaluate(self, z):
cmds = self.cmds[:] #1
stack = []
altstack = []
while len(cmds) > 0:#2
cmd = cmds.pop(0)
if type(cmd) == int:
operation = OP_CODE_FUNCTIONS[cmd]#3
if cmd in (99, 100):#4
if not operation(stack, cmds):
LOGGER.info('bad op: {}'.format(OP_CODE_NAMES[cmd]))
return False
elif cmd in (107, 108):#5
if not operation(stack, altstack):
LOGGER.info('bad op: {}'.format(OP_CODE_NAMES[cmd]))
return False
elif cmd in (172, 173, 174, 175):#6
if not operation(stack, z):
LOGGER.info('bad op: {}'.format(OP_CODE_NAMES[cmd]))
return False
else:
if not operation(stack):
LOGGER.info('bad op: {}'.format(OP_CODE_NAMES[cmd]))
return False
else:
stack.append(cmd)#7
if len(stack) == 0:
return False#8
if stack.pop() == b'':
return False#9
return True #10\# 1 因為指令集會在下面的計算過程中發生改變,所以單獨拷貝出一份。
\# 2 持續執行指令,直到指令集為空。
\# 3 需要執行的opcode的python函數定義的OP_CODE_FUNCTIONS 列表內。(比如 OP_DUP,OP_CHECKSIG 等)。
\# 4 99和100 分別對應OP_IF 和 OP_NOTIF。這兩個指令會對指令集和棧頂操作。
\# 5 107 和108 對應 OP_TOALSTACK 和 OP_FROMALTSTACK。這兩個指令會在棧和備用棧(altstack)間移動元素。
\#6 172,173,174和175 對應 OP_CHECKSIG,OP_CHECKSIGVERIFY,OP_CHECKMULTISIG 和 OP_CHECKMULTSIGVERIFY,這些指令需要第三章中籤名驗證的簽名文本的雜湊 z。
\#7 如果這個指令不是一個操作符,那麼它是一個元素。所以向棧中壓入元素。
\#8 如果在指令全部計算完成且棧為空。
\#9 如果棧頂為空字符串,則腳本運行失敗,返回False
\#10 任何其他情況說明腳本驗證有效。
|
使腳本計算安全
我們在這裡使用的代碼實際上有些偷懶,實際上的合併腳的過程並不是完全按照我們定義的方式運行的。簽名腳本和公鑰腳本會分開計算,這使得簽名腳本的運算不會影響公鑰腳本的指令。 具體來說,在簽名腳本計算完成後會儲存計算結果,之後公鑰腳本使用簽名腳本的棧作為起始運行的棧。 |
6.7.2. 棧元素的本質
可能令人困惑的一點是棧元素有時是0或1的數字有時是字節串,比如DER格式簽名和SEC 格式的公鑰。本質上來說,他們都是字節,只是有一些被解析為某些運算需要的數字。比如1在棧中儲存為0x01 字節,2儲存為0x02 字節,999為0xe703。對於運算需要的操作符,字節串將會以小端序解析。整數0不會以0x00儲存,而是空字節串。
在op.py中的代碼說明其運算規則:
def encode_num(num):
if num == 0:
return b''
abs_num = abs(num)
negative = num < 0
result = bytearray()
while abs_num:
result.append(abs_num & 0xff)
abs_num >>= 8
if result[-1] & 0x80:
if negative:
result.append(0x80)
else:
result.append(0)
elif negative:
result[-1] |= 0x80
return bytes(result)
def decode_num(element):
if element == b'':
return 0
big_endian = element[::-1]
if big_endian[0] & 0x80:
negative = True
result = big_endian[0] & 0x7f
else:
negative = False
result = big_endian[0]
for c in big_endian[1:]:
result <<= 8
result += c
if negative:
return -result
else:
return result
def op_0(stack):
stack.append(encode_num(0))
return True使用上述代碼,被壓入棧的數字被編碼成字節,當需要數值時從字節解碼。
6.8. p2pk 的缺陷
直觀上看,支付到公鑰(p2pk)有兩部分,有一個任何人可以轉入比特幣的公鑰和是一個只能有私鑰持有者生成的簽名。這在比特幣網路上運作的很好,但有一些問題。
首先公鑰是非常長的。我們在第四章中討論過,secp256k1曲線上的公鑰點壓縮SEC格式有33個字節,未壓縮SEC格式有65個字節。不幸的是人類並不能直接理解長度為33 或者65的字節。大部分字符編碼方案不會限制特定區間的字符,因為要留給了控制字符,比如新行(newline)等。編碼後的字符。SEC 格式通常以十六進制形式編碼,使長度加倍(十六進制編碼每個字符 4 位,而不是 8位)。這使得壓縮版和未壓縮版的SEC格式長度分別為66 或者130個字符。這比大多數標識符都長(比如,網站上的用戶名通常小於 20 個字符)。雪上加霜的是,早期的比特幣交易中沒有使用壓縮版本,所以十六進制地址是130個字符! 抄寫地址對人們來說並不十分容易,更別說通過語音傳遞交流。
儘管如此,在比特幣早期的p2pk使用場景是IP-to-IP 和挖礦收益歸集。在IP-to-IP支付場景,通過向IP地址詢問其公鑰。公鑰的交流是通過機器對機器完成的,所以人類之間溝通公鑰並不是一個問題。類似的,挖礦收益歸集也不需要人來傳遞公鑰。此外,IP-to-IP 支付系統由於容易被中間人攻擊逐步被淘汰了,這種支付方式並不安全。
其次,公鑰的長度還導致了一個更隱蔽的問題,由於UTXO集合需要維護並和索引UTXO來檢查output 是否可用,UTXO集的體積也因此變大了。這意味著全節點的運行需要更多資源。
第三點是由於我們在公鑰腳本中儲存了公鑰,公鑰也就暴露了。如果有一天ECDSA 方案被破解,我們的output 中的比特幣也會被竊取。比如量子計算有可能顯著降低RSA 和ECDSA 的計算時間,所以再做一些防護措施會更安全。但這並不是一個特別大的威脅,因為ECDSA 除了比特幣還應用在很多其他領域,ECDSA被破解會影響所有使用了ECDSA的事物。
6.8.1. 為什麼中本聰使用未壓縮的SEC格式?
由於區塊空間是非常重要的,比特幣使用未壓縮的SEC格式看上去毫無道理。那麼為什麼中本聰要這麼設計呢?中本聰當時使用OpenSSL庫來做SEC格式的轉換。當時的OpenSSL庫(大約在2008年)未壓縮格式的文檔質量並不好。據推測,這就是中本聰使用未壓縮的SEC格式的原因。
當Pieter Wuille 發現在OpenSSL中支持壓縮格式,越來越多的人在比特幣中使用壓縮的SEC格式。
(譯注:Pieter Wuille Blockstream公司聯合創始人,比特幣core 的開發人員,比特幣Core客戶端代碼提交量第二,兩個比較大貢獻是 BIP 32帶來的分層確定性錢包和隔離驗證。目前已經退出Core客戶端的開發。)
6.9. 使用p2pkh修復以上的問題
支付到公鑰雜湊(p2pkh)是另一個腳本格式,和p2pk相比主要有兩個優勢: . 地址更短 . 使用了hash256和ripemd160,提供了額外的安全性
由於經過了sha256和ripemd160的雜湊運算,地址要比公鑰短。依次進行兩次的雜湊被稱為hash160。hash160運算後的結果編碼成地址的長度為160位或20字節。
你可能在比特幣網路上和第四章中見過地址:
1PMycacnJaSqwwJqjawXBErnLsZ7RkXUAs
把地址編碼成16進制的20個字節如下:
f54a5851e9372b87810a8e60cdd2e7cfd80b6e31
上面20個字節是對下面(壓縮的)SEC格式公鑰做hash160計算的來的:
0250863ad64a87ae8a2fe83c1af1a8403cb53f53e486d8511dad8a04887e5b2352
儘管目前p2pk仍然可以在比特幣網路中使用,但由於p2pkh 更安全並且更短,p2pk格式的地址的使用率在2010年顯著下降。 (譯注:目前比特幣網路上約有200 萬比特幣仍然以P2PK的交易格式存在。2010年前後大概有下面的幾件事情發生。通過IP地址收發交易被廢棄,比特幣從CPU挖礦轉向GPU,更專業的礦工群體多采用P2PKH)
6.9.1. p2pkh
在比特幣早期,支付到公鑰雜湊(p2pkh)的交易格式就已經被使用,雖然不如p2pk使用率高。 p2pkh的公鑰腳本,即鎖定腳本如下圖Figure 6-15:

Figure 6-15. 支付到公鑰雜湊(p2pkh)的公鑰腳本。
和p2pk類似,我們需要OP_CHECKSIG 操作符。OP_HASH160也會出現在腳本中。但和p2pk不同的是,腳本中沒有SEC格式的公鑰,取而代之的是一個20字節長度的雜湊(譯注,即0x14)。還有一個新的操作符:OP_EQUALVERIFY。
p2pkh 的簽名腳本,即解鎖腳本如下圖Figure 6-16。

Figure 6-16. 支付到公鑰雜湊(p2pkh)的簽名腳本
和p2pk類似,簽名腳本中有DER格式的簽名。不同之處是p2pkh的簽名腳本中還包含SEC格式的公鑰。p2pk和p2pkh的主要區別是p2pkh把原來在公鑰腳本中的SEC格式公鑰放置在簽名腳本中。
將公鑰腳本和簽名腳本合併,構成了一個指令集如圖Figure 6-17。
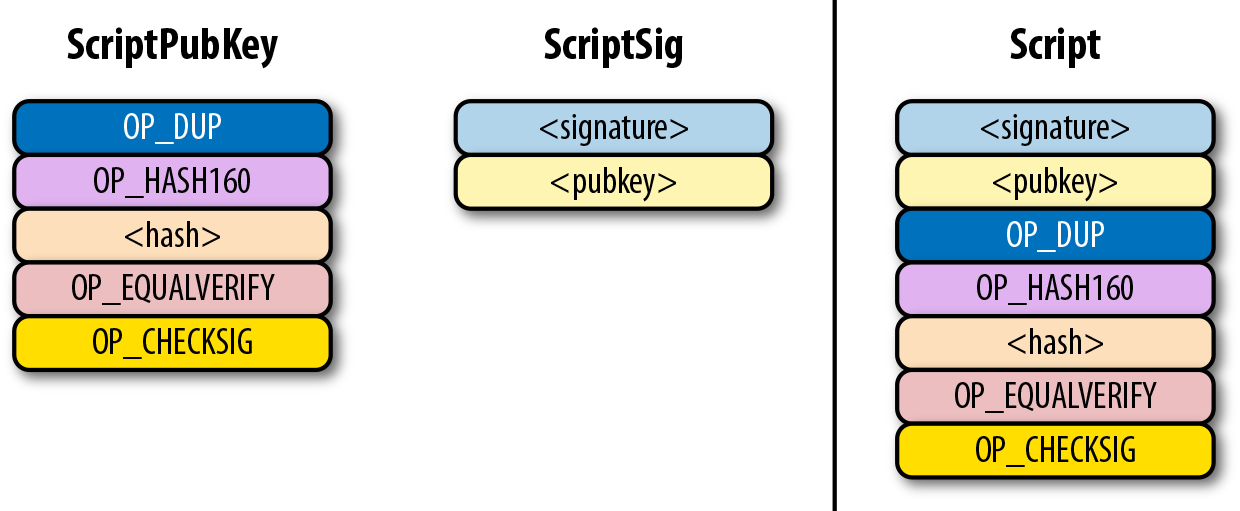
Figure 6-17. 合併後的p2pkh
此時我們需要依次執行指令。我們如圖Figure 6-18作為起點。
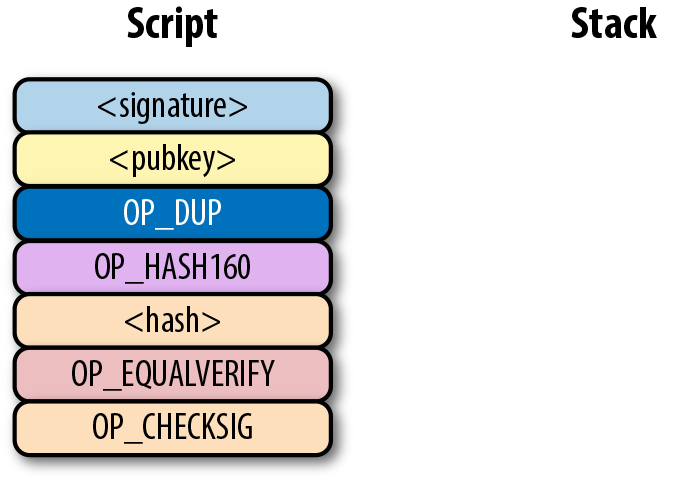
Figure 6-18. p2pkh 開始計算
腳本的前兩項是元素,所以壓入棧。(figure 6-19)
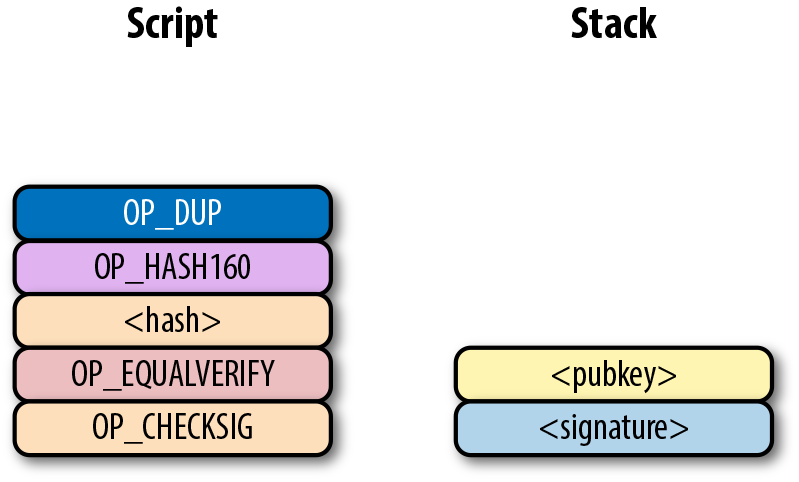
Figure 6-19. p2pkh第一步
OP_DUP會複製堆頂的元素,所以在堆頂複製了公鑰。(Figure 6-20)
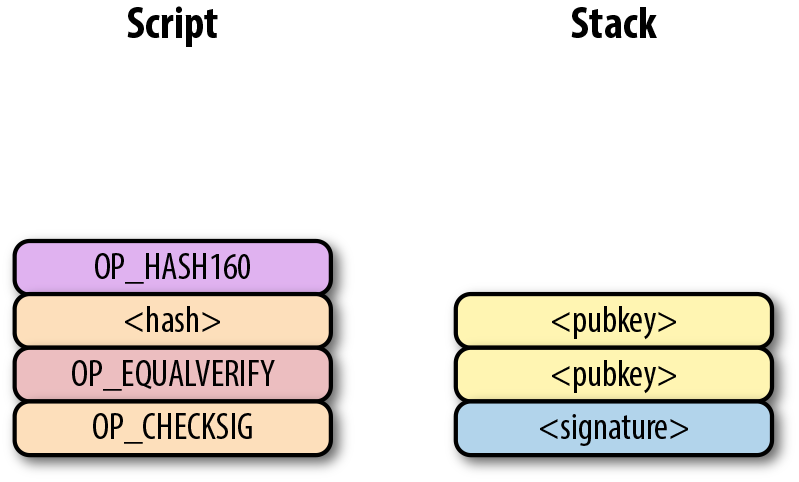
Figure 6-20. p2pkh 第二步
OP_HASH160 取出堆頂元素,並對其進行hash160計算(sha256後再做ripemd160),返回20字節的雜湊,壓入棧。(Figure 6-21)
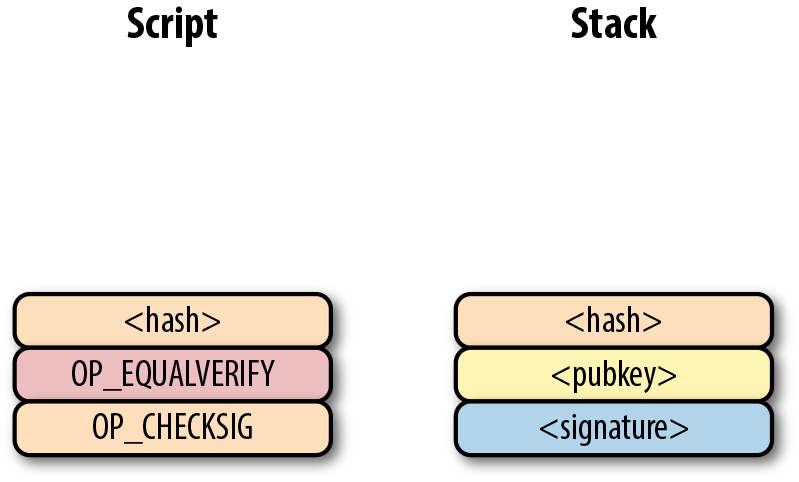
Figure 6-21.p2pkh 第三步
合併腳本的20個字節長度的hash是一個元素,所以也會壓入棧。(Figure 6-22)
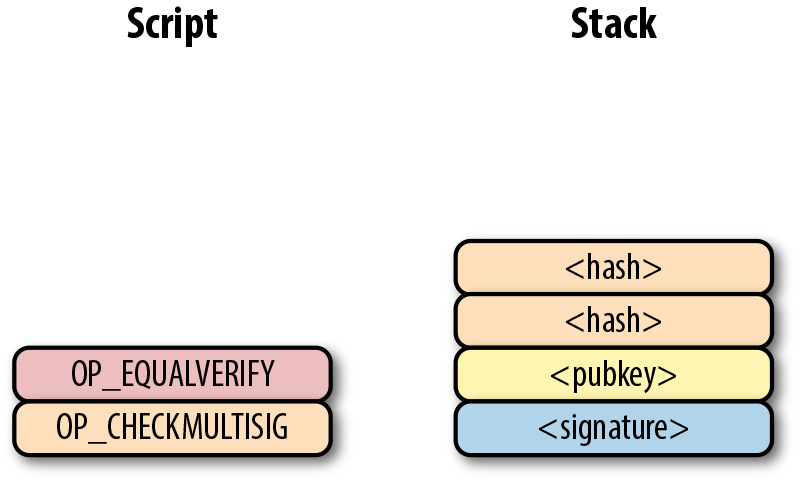
Figure 6-22. p2pkh 第四步
我們接下來要處理OP_EQUALVERIFY。這個操作符消耗堆頂的兩個元素,檢測兩個元素是否相等。如果相等,腳本繼續執行。如果不相等,腳本理解停止,以失敗退出。假設兩個元素相等,如圖Figure 6-23。
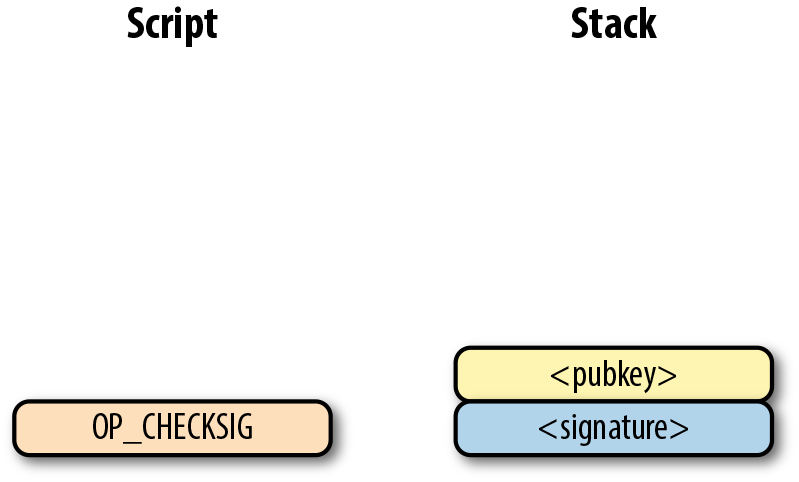
Figure 6-23. p2pkh 第五步
接下來的步驟和之前處理p2pk中的OP_CHECKSIG一樣。同樣假設簽名有效。(Figure6-24)
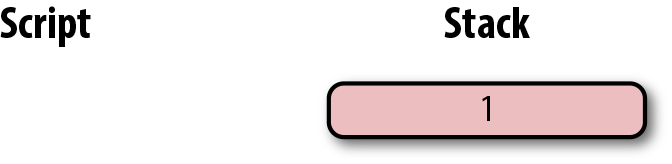
Figure 6-24. p2pkh 結束
有兩種情況會使得腳本計算以失敗退出。如果簽名腳本提供的公鑰的hash160計算結果與簽名的公鑰不符合,腳本會在OP_EQUALVERIFY(Figure 6-22)時以失敗退出。另一個情況是雖然公鑰雜湊與簽名的公鑰相符,但簽名本身是無效的。這會使腳本的計算結果為0,以失敗退出。
p2pkh的主要優勢是公鑰腳本更短(只需要25個字節)。一個比特幣盜竊者除了必須要破解ECDSA的離散對數問題,還要能計算出ripemd160和sha256 的原象。
(譯注:帶來的一個更常見的好處是可以編碼成二維碼。這裡我們再復習一下地址、公鑰,公鑰雜湊和私鑰的關係,私鑰單向生成公鑰,公鑰兩次雜湊運算單向生成公鑰雜湊,公鑰雜湊和地址可以相互轉換。如果你曾經通過二維碼收發比特幣交易,不難推理出該交易的格式為P2PKH)。
6.10. 腳本可以被任意構建
值得強調的是,腳本可以包含任意的代碼。Script是智能合約語言,可以使用多種方式來鎖定比特幣。圖Figure 6-25是一個公鑰腳本的例子。

Figure 6-25 . 公鑰腳本例子
Figure 6-26的簽名腳本能夠解鎖Figure 6-25的公鑰腳本。

Figure 6-26. 簽名腳本例子
合併後腳本如圖Figure 6-27所示。

Figure 6-27. 合併後腳本
腳本計算如下圖Figure 6-28。
Figure 6-28. 開始計算
OP_4 將4壓入棧(Figure 6-29)
Figure 6-29. 第一步
OP_5 將5 壓入棧(Figure 6-30)。
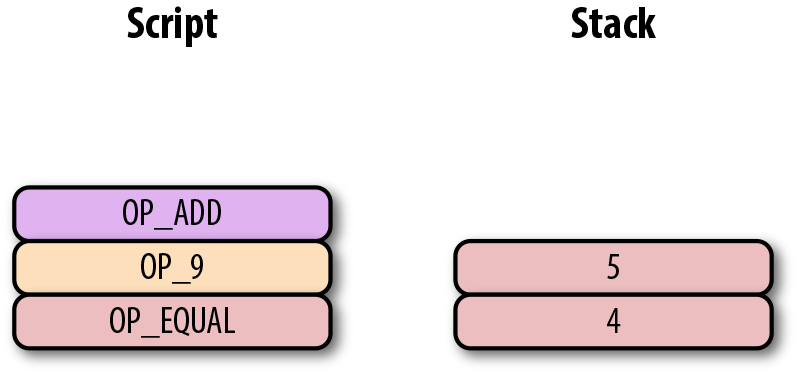
Figure 6-30. 第二步
OP_ADD 將會消耗棧頂的兩個元素,把相加後的和壓入棧。(Figure 6-31)
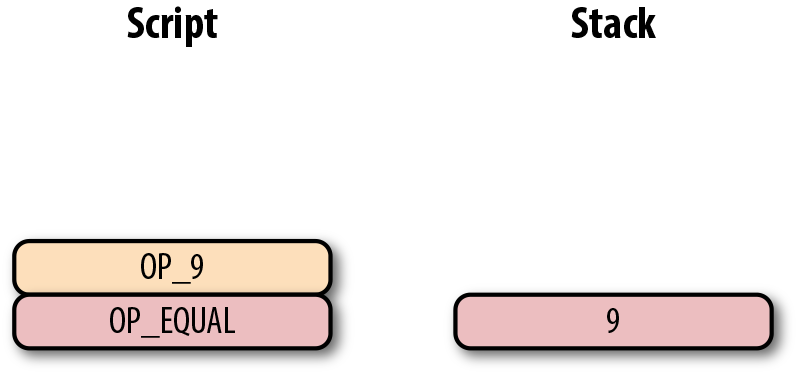
Figure 6-31. 第三步
OP_9 將9 壓入棧 (Figure 6-32)。
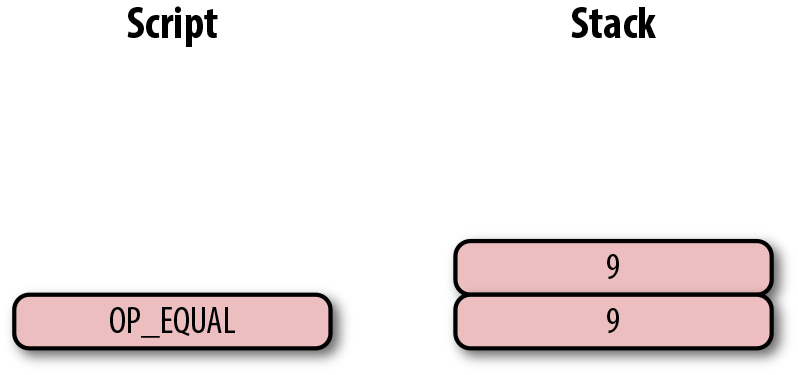
Figure 6-32. 第四步
OP_EQUAL 會消耗兩個堆頂元素,如果兩個元素相等,壓入1,反之壓入0。(Figure 6-33)

Figure 6-33. 計算結束
值得強調的是,簽名腳本的內容並不是很難理解,其中也不包含任何簽名。這會導致公鑰腳本內的比特幣很容易被取走,因為每個人都解得出。這好比公鑰腳本作為一個保險櫃,卻只有一個非常弱的鎖,所有人都能破解它。出於這個原因,大部分的交易要求在簽名腳本中至少有一個簽名。
一旦一個UTXO在交易中被使用,進入區塊,交易的安全性將由工作量證明(proof of work)來保證。其中的比特幣將被一個不同的公鑰腳本鎖定,不再輕易地被使用(譯注:指這次交易的UTXO已經從未使用的狀態變成已使用)。如果有人嘗試使用一個已經使用過的UTXO 必須通過工作量證明來實現,而這是非常昂貴的(參考第九章)。
6.10.1. Exercise 3
創建一個簽名腳本來解鎖下面的公鑰腳本: 767695935687 注意 OP_MUL 會消耗堆頂的兩個元素。
-
56 = OP_6
-
76 = OP_DUP
-
87 = OP_EQUAL
-
93 = OP_ADD
-
95 = OP_MUL
6.10.2. 腳本的使用
上一個練習存在和現實不符合的部分,即OP_MUL 運算符在目前的比特幣網路中已經被禁止。在比特幣的 0.3.5 的版本中禁止了許多操作符(即使有微小可能性在比特幣網路上產生漏洞的操作符都被禁用了)。
這並沒有使比特幣網路出現太大的變化,因為Script中的大多數功能實際上並沒有被廣泛使用。從軟體維護的角度來看,這並不是一個很好的選擇,因為儘管使用次數不多,但代碼仍然需要維護。簡化並禁用某些功能帶來的好處是可以使比特幣更安全。
這也是比特幣和其他項目的顯著區別。很多項目嘗試擴展智能合約語言,但帶來新特性的同時也會引入安全問題。
6.10.3. Exercise 4
理解下面的腳本在做什麼: 6e879169a77ca787
-
69 = OP_VERIFY
-
6e = OP_2DUP
-
7c = OP_SWAP
-
87 = OP_EQUAL
-
91 = OP_NOT
-
a7 = OP_SHA1
使用Script.parse 方法並通過查找en.bitcoin.it/wiki/Script來腳本中的操作符的功能。
6.10.4. SHA-1 Pinata
2013年,Peter Todd 創建了一個和Exercise 4 類似的腳本,附帶了一些比特幣以激勵人們嘗試發現雜湊碰撞。捐款達到了2.49153717 比特幣,當Google在2017年2月實際發現SHA-1的雜湊碰撞時,該腳本立即被解鎖。交易轉出了2.48個比特幣,在當時大概價值2,848.88 美元。
Peter 也構造了更多的pinatas,包括 sha256,hash256和hash160。這為尋找這些雜湊函數的雜湊碰撞提供經濟激勵。
(譯注:Peter Todd比特幣的核心開發人員。2012年開始提交比特幣軟體代碼。 Pinata 是西班牙語,容器,在慶典和生日時懸掛起來,當人們用棒棍打破後,會掉落玩具和糖果。這裡指SHA-1 發現雜湊碰撞的懸賞。在Exercise 4中的腳本的意思指提供兩個不同的元素,如果雜湊後相同則能取走比特幣。)
7. 第七章 交易的創建與驗證
在比特幣中代碼實現中最棘手的事情之一是驗證交易。另一個是交易創建。在本章中,我們將介紹兩者的具體步驟。在本章的最後,我們將創建一筆testnet交易並進行廣播。
7.1. 交易驗證
當節點接受網路中的交易時,節點要確保每個交易都遵循網路的規則。這個過程被稱為交易驗證。節點會主要校驗交易的三個方面:
-
校驗交易輸入(Input)在此前沒有被使用過
-
校驗交易輸入的比特幣數量總和大於交易輸出(Output)的總和
-
校驗簽名腳本是否能成功解鎖公鑰腳本
\#1 防止雙花交易。任何已經被使用的(即被記錄在區塊鏈中的)的交易輸入不能被再次使用。
\#2 確保沒有新的比特幣產生(比特幣的coinbase 礦工獎勵是一個例外,會在第九章討論)。
\#3 確保簽名腳本與公鑰腳本合併後的腳本是合法的。這對大部分交易來說意味著去驗證簽名腳本里的一個或者更多的簽名是否有效。
接下來我們分別討論如何完成各個校驗。
7.1.1. 校驗交易輸入是否可用
為了防止雙花交易,節點將會確認每個input的存在並且沒有被使用過。每一個全節點都可以通過查詢UTXO集(參考第五章來完成校驗)。我們不能只通過交易本身來判定交易其是否是雙花交易。這好比我們不能只通過一張個人支票來判斷他的兌付能力。唯一的方式是查詢UTXO集來判斷,而這需要通過計算全部交易來獲得。
在比特幣中,我們可以通過維護UTXO集合來判斷一個交易輸入是否被雙花(二次使用)。如果一個交易輸入被記錄在UTXO集合中,那麼我們認為該交易輸入是存在的並且沒有被二次使用的。如果這個交易還通過了之後的校驗,我們會把這個交易全部的交易輸入從UTXO集合中移除。不能直接訪問區塊鏈所有信息的輕節點則不得不信任其他的全節點來獲取信息,包括一個交易輸入是否已經被使用。
一個全節點可以非常容易地判斷交易輸入是否被使用,但一個輕節點不得不從其他人那裡獲取信息。
7.1.2. 校驗交易輸入的比特幣數量總和大於交易輸出的總和
節點還要確保交易中的交易輸入所代表的比特幣總數要大於或者等於交易輸出所代表的比特幣總數。這確保了交易不會產生新的比特幣。一個例外是coinbase交易,我們將在第九章中學習。由於交易輸入中沒有描述比特幣數量的欄位,所以必須要去區塊鏈查詢。和之前一樣,全節點可以獲取未花費的交易輸出的比特幣總數,輕節點需要依賴全節點提供比特幣數量的信息。
我們在第五章中討論了如何計算手續費。校驗交易輸入的比特幣數量總和大於等於交易輸出等價於校驗手續費不為負(也就是非法地製造新幣)。在第五章地最後一個練習中,fee方法如下定義:
class Tx:
...
def fee(self):
'''Returns the fee of this transaction in satoshi'''
input_sum, output_sum = 0, 0
for tx_in in self.tx_ins:
input_sum += tx_in.value(self.testnet)
for tx_out in self.tx_outs:
output_sum += tx_out.amount
return input_sum - output_sum我們可以使用下面地方法來校驗其交易是否印刷了新的錢:
>>> from tx import Tx
>>> from io import BytesIO
>>> raw_tx = ('0100000001813f79011acb80925dfe69b3def355fe914bd1d96a3f5f71bf830
3c6a989c7d1000000006b483045022100ed81ff192e75a3fd2304004dcadb746fa5e24c5031ccf
cf21320b0277457c98f02207a986d955c6e0cb35d446a89d3f56100f4d7f67801c31967743a9c8
e10615bed01210349fc4e631e3624a545de3f89f5d8684c7b8138bd94bdd531d2e213bf016b278
afeffffff02a135ef01000000001976a914bc3b654dca7e56b04dca18f2566cdaf02e8d9ada88a
c99c39800000000001976a9141c4bc762dd5423e332166702cb75f40df79fea1288ac19430600')
>>> stream = BytesIO(bytes.fromhex(raw_tx))
>>> transaction = Tx.parse(stream)
>>> print(transaction.fee() >= 0)#1
True\#1 只有我們在使用python的情況下才成立(參考下面的比特幣值溢出事故)。
如果交易手續費為負,我們可以推理出output_sum 比input_sum要大,也就是交易在試圖無中生有地創造比特幣。
(譯注:作者在此處使用的原文為out of the ether。Ether,以太是古希臘哲學家亞里士多德所設想的一種物質。在科學史上,帶有神秘色彩,指光和電的載體,邁克耳孫莫雷干涉實驗證明瞭以太不存在,也就是物理學著名的兩朵烏雲之一。結合語境,out of ether指超出常理地,無中生有地。作者使用out of the ether 這一非常少見的短語可能的原因是想隱晦地吐槽以太坊(ethereum)。
|
值溢出事故
在2010年,在一筆交易中創造了1840億新的比特幣。這是因為在C++ 中,數量欄位使用的類型為signed integer 而不是 unsigned integer。也就是說這允許負數值的存在。 這個巧妙設計的交易通過了全部的校驗,包括沒有新比特幣產生的校驗。這是因為交易輸出上溢超過最大值。 264≈ 1.84× 1019 聰,大約是1840億個比特幣。因為手續費是一個非常大的負數,使得C++ 認為該手續費為正0.1 比特幣。 此漏洞在 CVE-2010-5139 中詳細說明,在比特幣core 客戶端 0.3.11 中的軟分叉升級中修復。交易和它創建的比特幣被區塊重組(回滾)判為無效,也就是包含此交易的區塊和在這個區塊之後的所有區塊都被替換了。 |
7.1.3. 校驗簽名
交易校驗過程中最難的就是簽名的校驗。交易的每個交易輸入至少有一個簽名,如果使用的是一個多重簽名的交易輸出就會有更多的簽名。在第三章中學習過,ECDSA簽名算法需要公鑰 P,和簽名文本雜湊 z,和簽名結果 (r,s)。如果給出全部的上述信息,簽名的驗證過程非常簡單,如我們在第三章中實現的:
>>> from ecc import S256Point, Signature
>>> sec = bytes.fromhex('0349fc4e631e3624a545de3f89f5d8684c7b8138bd94bdd531d2e213bf016b278a')
>>> der = bytes.fromhex('3045022100ed81ff192e75a3fd2304004dcadb746fa5e24c5031ccfcf21320b0277457c98f02207a986d955c6e0cb35d446a89d3f56100f4d7f67801c31967743a9c8e10615bed')
>>> z = 0x27e0c5994dec7824e56dec6b2fcb342eb7cdb0d0957c2fce9882f715e85d81a6
>>> point = S256Point.parse(sec)
>>> signature = Signature.parse(der)
>>> print(point.verify(z, signature))
True當我們執行類似OP_CHECKSIG的操作符時,SEC 公鑰 和 DER簽名也會在棧內,這使得獲取公鑰和簽名非常容易(見第六章)。最難的部分是獲取交易雜湊。一個簡單的實現方法是對交易的序列化數據做雜湊(如圖(Figure 7-1))。不幸的是,這是行不通的,因為簽名是簽名腳本的一部分,簽名不能對自己本身簽名。

Figure 7-1.簽名,或者說是簽名腳本,如圖中高亮部分
因此,我們會在簽名前修改交易。即對每個交易輸入做一次不同的交易簽名雜湊,流程如下。
第一步:清空所有簽名腳本
第一步,當校驗交易簽名時,先清空所有簽名腳本(如圖Figure 7-2)。這一步驟和簽名構造相同,但簽名腳本通常已經是空的了。

Figure 7-2. 清空交易輸入的簽名腳本(黃色高亮欄位,當前被替換為00)
注意當前這個例子中只有一個交易輸入,所以也只有一個交易輸入的簽名腳本被清空。如果是交易有多個交易輸入的情況下,我們也需要分別清空處理。
第二步:以父交易的公鑰腳本替換被簽名交易輸入的簽名腳本
每一個交易輸入都指向夫交易的一個交易輸出和其對應的公鑰腳本。這裡我們引用第六章的圖片Figure 7-3。
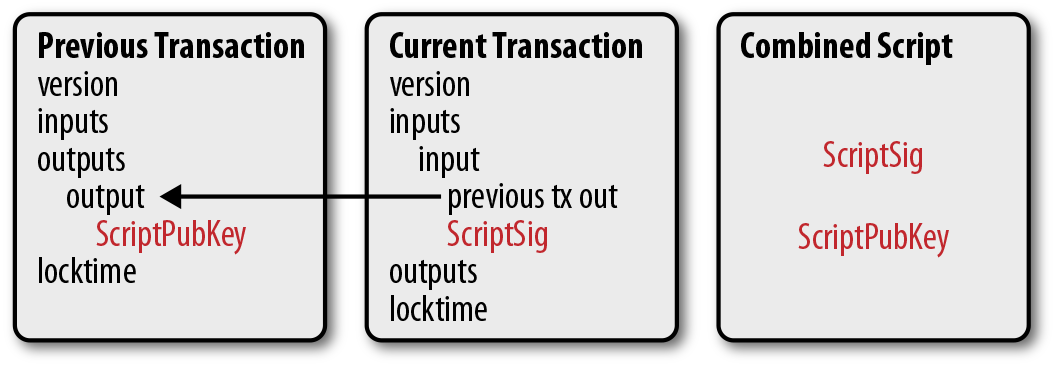
Figure 7-3. 合併公鑰腳本和簽名腳本
我們把交易輸入指向的公鑰腳本放置在清空的簽名腳本的位置(圖Figure 7-4)。這需要在區塊鏈上獲取相關信息,但是在實踐中籤名者已知公鑰腳本,因為他擁有該交易輸入對應的私鑰。

Figure 7-4. 將簽名腳本替換為交易輸入對應的父交易的公鑰腳本
第三步 追加雜湊類型
最後,我們在尾部追加4個字節的雜湊類型用來確定簽名的授權範圍。該簽名可以授權自己簽名的交易輸入以外的全部交易輸入和交易輸出(SIGHASH_ALL),也可以指定一個交易輸出(SIGHHASH_SINGLE)或者不指定任何交易輸出(SIGHASH_NONE)。後面兩個只有理論上的使用場景。在實踐中幾乎所有的交易都使用SIGHASH_ALL雜湊類型。極少數的場景也會使用SIGHASH_ANYONECANPAY類型,可以和任何父交易的交易輸出結合,這裡就不深入討論了。SIGHASH_ALL要求交易必須有和簽名指定一致的交易輸出,否則簽名失效。
SIGHASH_ALL對應的整數是1,我們需要以小端序編碼成4字節。我們修改交易如下Figure 7-5。

Figure 7-5. 在交易結尾追加交易的雜湊類型(SIGHASH_ALL),即棕色的01000000
我們對這個修改後的交易數據進行sha256運算後並對結果進行大端序編碼,我們就獲得了 z。從修改的交易轉換成 z 的過程代碼如下:
>>> from helper import hash256
>>> modified_tx = bytes.fromhex('0100000001813f79011acb80925dfe69b3def355fe914bd1d96a3f5f71bf8303c6a989c7d1000000001976a914a802fc56c704ce87c42d7c92eb75e7896bdc41ae88acfeffffff02a135ef01000000001976a914bc3b654dca7e56b04dca18f2566cdaf02e8d9ada88ac99c39800000000001976a9141c4bc762dd5423e332166702cb75f40df79fea1288ac1943060001000000')
>>> h256 = hash256(modified_tx)
>>> z = int.from_bytes(h256, 'big')
>>> print(hex(z))
0x27e0c5994dec7824e56dec6b2fcb342eb7cdb0d0957c2fce9882f715e85d81a6至此,我們已經計算出了 z,接下來我們使用 SEC格式的公鑰和從簽名腳本中得到的DER格式的簽名來校驗簽名是否合法:
>>> from ecc import S256Point, Signature
>>> sec = bytes.fromhex('0349fc4e631e3624a545de3f89f5d8684c7b8138bd94bdd531d2e213bf016b278a')
>>> der = bytes.fromhex('3045022100ed81ff192e75a3fd2304004dcadb746fa5e24c5031ccfcf21320b0277457c98f02207a986d955c6e0cb35d446a89d3f56100f4d7f67801c31967743a9c8e10615bed')
>>> z = 0x27e0c5994dec7824e56dec6b2fcb342eb7cdb0d0957c2fce9882f715e85d81a6
>>> point = S256Point.parse(sec)
>>> signature = Signature.parse(der)
>>> point.verify(z, signature)
True我們可以在Tx類中編寫交易驗證過程的方法了。幸運的是,Script的引擎已經能處理交易的簽名驗證了(參加第六章)。我們需要把 z 即簽名雜湊傳遞給evalute方法,之後合併簽名腳本和公鑰腳本。
|
二次增長的雜湊計算
簽名的雜湊算法效率低下,浪費計算資源。二次增長雜湊問題(quadratic hashing problem)指雜湊的簽名雜湊的計算量根據簽名數量的二次增長。具體的說,不但雜湊計算的數量根據交易輸入數量而增長,更多的交易輸入還導致交易體積增長,這也會拖慢hash256的計算速度,因為對每個交易輸入都要重新計算整個簽名散列。 尤為明顯的是如下的迄今為止最大的交易: bb41a757f405890fb0f5856228e23b715702d714d59bf2b1feb70d8b2b4e3e08 這筆交易有5569個交易輸入和一個交易輸出,很多礦工需要超過一分鐘來驗證這筆交易。這筆交易的雜湊值非常難計算。 隔離見證(第十三章)通過在BIP中0143中提出不同的雜湊計算方法來解決此問題。 |
7.1.6. 校驗交易的全部內容
我們已經能校驗交易的input,那麼校驗整個交易就非常簡單了:
class Tx:
...
def verify(self):
'''Verify this transaction'''
if self.fee() < 0:#1
return False
for i in range(len(self.tx_ins)):
if not self.verify_input(i): #2
return False
return True\#1 確保交易沒有產生新的比特幣
\#2 確保交易的每個交易輸入都有正確的簽名腳本
此外,一個全節點也會校驗其他內容,比如檢查交易是否雙花,和一些不在本章討論的其他共識規則(比如 max sigops,簽名腳本大小等)。但目前實現對我們的代碼庫來說已經足夠使用了。
7.2. 創建交易
我們實現的驗證交易的代碼也能幫助我們很好地理解交易的創建。我們可以創建一個符合驗證過程的交易。我們創建的交易要滿足交易輸入代表的比特幣總量大於等於交易輸出代表的比特幣總量。類似的,交易的簽名腳本在和公鑰腳本合併後應當是有效的。
創建一個交易需要至少一個我們收到的output。即我們需要一個在UTXO集合內的output,並且我們能夠結果該output。絕大部分情況,我們需要一個或者多個對應公鑰腳本的被雜湊計算的公鑰的私鑰。
本章的後續部分將討論以p2pkh公鑰腳本鎖定的output作為input的交易的創建。
7.2.1. 構建交易
交易的構建過程需要回答下面三個基本問題: . 我們希望比特幣支付到哪裡? . 我們可以使用哪些UTXO? . 我們希望交易進入區塊鏈的時間是?
我們使用測試鏈為例,儘管也很容易在主鏈上實踐。
第一個問題是包含了我們要給誰支付多少比特幣。我們可以支付到一個或者更多個地址。在這個了例子中我們支付0.1 個測試鏈的比特幣(tBTC)到地址。mnrVtF8DWjMu839VW3rBfgYaAfKk8983Xf。
第二個問題是指,我們的錢包里有哪些鈔票。我們可以使用哪些utxo來支付?在這個例子中我們使用output的交易雜湊和序號如下:
0d6fe5213c0b3291f208cba8bfb59b7476dffacc4e5cb66f6eb20a080843a299:13
我們可以在測試鏈的區塊鏈瀏覽器中查看此交易。(Figure 7-6)可以看到我們的output中含有0.44 個tBTC。 (譯注:tBTC ,t 指測試鏈 testnet)
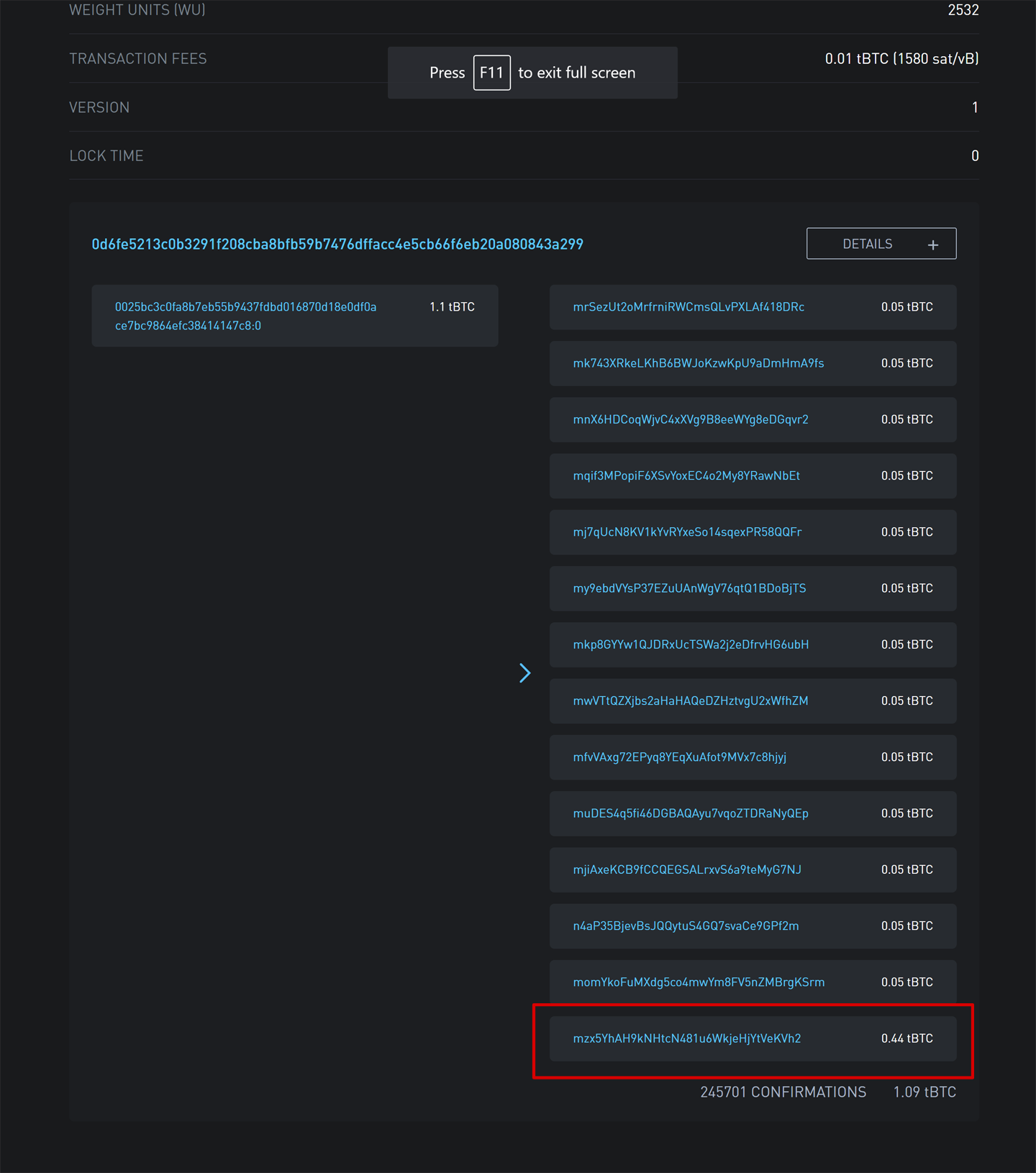
Figure 7-6. 我們要使用的UTXO
由於UTXO的價值超過0.1 tBTC,我們要將超過的其餘部分支付給我們自己。雖然出於安全和隱私的考慮,重復使用地址的並不合適,我們把超過部分支付給mzx5YhAH9kNHtcN481u6WkjeHjYtVeKVh2,這樣會使我們的交易構造容易一些。
第三個問題和手續費相關。如果我們希望交易進區塊進入區塊鏈,我們需要支付更多手續費。如果我們不介意多一會,我們也可以少支付手續費。在這個例子中我們設定手續費為0.01。
|
為什麼重復使用地址是個糟糕的想法
在第六章中我們提到過p2phk優於p2pk,部分原因是p2pk安全性只由橢圓曲線方案ECDSA提供保護。而p2pkh則還增加了sha256和ripemd160。但是由於我們區塊鏈是公開的,我們當第一次從公鑰腳本對應的地址時,我們也就公開了我們的公鑰。如果我們公開公鑰,那sha256和ripemd160也就不會提供額外的安全性了。因為潛在的攻擊者已經知道地址對應的公鑰,不需要再去試錯破解了。 在本書寫作時,離散對數問題仍然能提供安全性,也不太可能在短時間內被破解。出於安全角度考慮,我們還是有必要理解我們由什麼提供了安全性。 另一個不應該重用地址的原因是隱私。使用一個地址來處理全部交易意味著地址擁有人和地址是綁定的。比如我們秘密的購買某個東西(比如治療不想被公開的疾病的藥物)同時我們還使用同樣的公鑰腳本的另一個output捐贈給一些慈善機構。這種情況下慈善機構和藥物供應商都會知道我們和另外一個機構有交易。 隨著時間的推移,隱私洩露往往會成為安全漏洞。 |
|
交易手續費估計
交易手續費以每字節比特幣計價。如果一個交易的長度為600字節,我們的手續費會是長度為300字節的交易的兩倍。這是因為區塊鏈的區塊空間是有上限的,體積更大的交易會佔用更多的空間。這個計價方式在Segwit生效後(參考第十三章)有一些小的變動。但大體上還是使用這個計價方案。我們要支付足夠高的每字節比特幣作為手續費報價,這樣才會激勵礦工盡快將交易打包進入區塊鏈。 當區塊鏈的區塊不滿時,幾乎所有提供超過默認手續費額度(relay limit)(1 聰/字節)的手續費的交易都會被打包進入區塊鏈。但是當區塊鏈的區塊填滿的時候,估計手續費並不容易。下面是幾個估計手續費的方案:
(譯注:指節點儲存待處理交易的交易池。在比特幣中長期存在過粉塵攻擊,即支付非常小的交易手續費,雖然不會影響礦工給這種交易非常低優先級。但是會導致非出區塊的節點忙於廣播合法但低價值交易,以堵塞節點通訊。這種攻擊是無成本的。此外粉塵攻擊也可以指另一種有成本的攻擊方式,不同之處是支付了合理的手續費作為攻擊成本,最終導致區塊鏈交易填滿區塊上限,導致其他用戶交易手續費成本上升或者交易延遲進入區塊)。 |
7.2.2. 製作交易
我們已計劃好製作一個交易,有一個交易輸入,兩個輸出。但我們還是首先考察一下其他我們需要使用到的工具:
我們需要一個轉換地址到20字節雜湊的工具。這也就是編碼地址的反向計算,所以我們命名這個函數為decode_base58:
def decode_base58(s):
num = 0
for c in s:#1
num *= 58
num += BASE58_ALPHABET.index(c)
combined = num.to_bytes(25, byteorder='big')#2
checksum = combined[-4:]
if hash256(combined[:-4])[:4] != checksum:
raise ValueError('bad address: {} {}'.format(checksum,\
hash256(combined[:-4])[:4]))
return combined[1:-4]#3
\#1 獲取被編碼成地址的對應數字
\#2 一旦我們獲得了數字,我們就可以以大端序編碼
\#3 第一個字節是代表網路的前綴,最後4個字節是校驗碼,中間的20個字節是20個字節是實際上的20字節的雜湊(也就是hash160)。
此外我們還需要一個根據20字節雜湊生成公鑰雜湊的工具。我們稱這個函數為p2pkh_script,因為我們把hash160轉換成p2pkh:
def p2pkh_script(h160):
'''Takes a hash160 and returns the p2pkh ScriptPubKey'''
return Script([0x76, 0xa9, h160, 0x88, 0xac])0x76 對應操作符 OP_DUP, 0xa9 對應 OP_HASH160, h160 是一個20字節長度的腳本的元素,0x88 對應操作符 OP_EQUALVERIFY,0xac 對應 OP_CHECKSIG。組合起來就是我們第六章中講述的公鑰腳本的指令集。
通過這些工具,我們可以通過以下過程製作交易。
>>> from helper import decode_base58, SIGHASH_ALL
>>> from script import p2pkh_script, Script
>>> from tx import TxIn, TxOut, Tx
>>> prev_tx = bytes.fromhex('0d6fe5213c0b3291f208cba8bfb59b7476dffacc4e5cb66f6\
eb20a080843a299')
>>> prev_index = 13
>>> tx_in = TxIn(prev_tx, prev_index)
>>> tx_outs = []
>>> change_amount = int(0.33*100000000)#1
>>> change_h160 = decode_base58('mzx5YhAH9kNHtcN481u6WkjeHjYtVeKVh2')
>>> change_script = p2pkh_script(change_h160)
>>> change_output = TxOut(amount=change_amount, script_pubkey=change_script)
>>> target_amount = int(0.1*100000000)#1
>>> target_h160 = decode_base58('mnrVtF8DWjMu839VW3rBfgYaAfKk8983Xf')
>>> target_script = p2pkh_script(target_h160)
>>> target_output = TxOut(amount=target_amount, script_pubkey=target_script)
>>> tx_obj = Tx(1, [tx_in], [change_output, target_output], 0, True)#2
>>> print(tx_obj)
tx: cd30a8da777d28ef0e61efe68a9f7c559c1d3e5bcd7b265c850ccb4068598d11
version: 1
tx_ins:
0d6fe5213c0b3291f208cba8bfb59b7476dffacc4e5cb66f6eb20a080843a299:13
tx_outs:
33000000:OP_DUP OP_HASH160 d52ad7ca9b3d096a38e752c2018e6fbc40cdf26f OP_EQUALVE\
RIFY OP_CHECKSIG
10000000:OP_DUP OP_HASH160 507b27411ccf7f16f10297de6cef3f291623eddf OP_EQUALVE\
RIFY OP_CHECKSIG
locktime: 0\#1 交易中的比特幣數量要以聰計,每100,000,000聰為1個比特幣。需要乘以系數,轉換成整數。
\#2 通過test=Ture,我們制定了交易在哪裡網路上。
我們完成了交易的大部分,但還交易中的簽名腳本還是空的。接下來我們填充這部分。
7.2.3. 簽名交易
簽名交易比較複雜,但是我們已經在本章的前面部分中知道如何獲得待簽名雜湊文本 z。如果我們掌握私鑰,其公鑰對應公鑰腳本中20字節雜湊,我們就可以簽名 z,製作DER格式的簽名:
>>> from ecc import PrivateKey
>>> from helper import SIGHASH_ALL
>>> z = transaction.sig_hash(0)#1
>>> private_key = PrivateKey(secret=8675309)
>>> der = private_key.sign(z).der()
>>> sig = der + SIGHASH_ALL.to_bytes(1, 'big')#2
>>> sec = private_key.point.sec()
>>> script_sig = Script([sig, sec])#3
>>> transaction.tx_ins[0].script_sig = script_sig#4
>>> print(transaction.serialize().hex())
0100000001813f79011acb80925dfe69b3def355fe914bd1d96a3f5f71bf8303c6a989c7d10000\
00006a47304402207db2402a3311a3b845b038885e3dd889c08126a8570f26a844e3e4049c482a\
11022010178cdca4129eacbeab7c44648bf5ac1f9cac217cd609d216ec2ebc8d242c0a01210393\
5581e52c354cd2f484fe8ed83af7a3097005b2f9c60bff71d35bd795f54b67feffffff02a135ef\
01000000001976a914bc3b654dca7e56b04dca18f2566cdaf02e8d9ada88ac99c3980000000000\
1976a9141c4bc762dd5423e332166702cb75f40df79fea1288ac19430600\#1 我們只需要簽名第一個,也為唯一的input,當有多個簽名時,需要我們使用正確的私鑰依次簽名每個input。
\#2 簽名實際上需要合併DER格式的簽名和指定的雜湊類型,在我們的例子中是SIGHASH_ALL。
\#3 如我們在第六章討論的,p2pkh的簽名腳本中只有這兩個元素:簽名和SEC格式的公鑰。
\#4 我們只有一個input 需要簽名,如果有更多input,我們也需要多次對每個input分別構造簽名腳本。
7.3. 在測試網路創建你自己的交易
為了創建你自己的交易,你需要要有自己的測試比特幣。首先你要有一個地址。如果你完成了第四章的最後的練習,你應該擁有自己的地址的對應的私鑰。如果你已經不記得了,可以參考下面的代碼:
>>> from ecc import PrivateKey
>>> from helper import hash256, little_endian_to_int
>>> secret = little_endian_to_int(hash256(b'Jimmy Song secret'))#1
>>> private_key = PrivateKey(secret)
>>> print(private_key.point.address(testnet=True))
mn81594PzKZa9K3Jyy1ushpuEzrnTnxhVg\#1 請務必換一個助記詞,而不是"Jimmy Song secret"。
一旦有一個地址,你可以從我們的測試鏈水龍頭獲取一些測試幣,測試鏈水龍頭指為測試者提供免費的測試幣的網站。你可以搜索「testnet bitcoin faucet」(比特幣測試鏈水龍頭)或者在 比特幣項目的wiki的列表中找到測試鏈水龍頭。我的個人網站 https://faucet.programmingbitcoin.com也更新並提供測試鏈水龍頭服務。填寫你的測試鏈地址到這些測試幣水龍頭來獲取一些測試鏈的比特幣。
收到一些測試幣後,使用本章的代碼庫花掉你的測試幣。這對比特幣開發者是重要成就,請花一些時間完成這一練習。
7.3.1. Exercise 5
創建一個交易,支付一個UTXO的60%的到地址 mwJn1YPMq7y5F8J3LkC5Hxg9PHyZ5K4cFv。 排除手續費的其餘部分支付給你自己的找零地址。也就是一個input 兩個output。
你可以在網站https://live.blockcypher.com/btc/pushtx廣播你的交易。
7.3.2. Exercise 6
高級內容:從測試幣水龍頭中收集更多測試比,創建一個包括兩個input,兩個output的交易。一個input來自水龍頭,另一個來自上一個練習的找零地址。output可以是你自己的地址。
你可以在網站https://live.blockcypher.com/btc/pushtx廣播你的交易。
8. 第八章 支付到腳本雜湊交易(P2SH)
目前為止,我們已經討論了如何處理單私鑰交易,即每個input只需要一個私鑰簽名。但是如果我們需要更複雜的功能該怎麼處理呢?比如一家持有1億美元比特幣的公司不會希望其資產通過一個私鑰保存:如果一個私鑰丟失或者被竊,所有的資產都會丟失。我們怎麼做才能減少此類的單點故障的風險呢?
答案是multsig,多重簽名。該功能在比特幣誕生時就提供了,因為難以使用,起初並沒有人使用它。在本章中我們會發現,中本聰可能沒有對多重簽名做測試,因為它有一個大小差一錯誤(off-by-one error,參考OP_CHECKMULTISIG 的差一錯誤)。這個漏洞一直存在比特幣協議中,因為修復它需要硬分叉。
|
多個私鑰聚合成單私鑰
事實上我們可以將要給私鑰拆分成多個私鑰,並通過交互的方式完成簽名而不需要使用原始私鑰。但在日常實踐中很少採用。Schnorr簽名可以使簽名的聚合過程更方便,有可能在未來中採用。 |
8.1. 裸多簽
裸多簽是第一個嘗試創建需要來自多方簽名的交易output。思路是將單點故障轉換成一個更有彈性來對抗攻擊的東西。要理解裸多簽,我們首先要學習OP_CHECKMULTSIG 操作符。如我們在第六章中討論的那樣,Script有許多不同的操作符。OP_CHECKMULTSIG是其中之一,對應字節為0xae。這個操作符會消耗棧中的許多元素,返回提供的簽名是否能有效解鎖input。
交易的output被稱為「裸」多重簽名是因為其有一個很長的公鑰簽名。圖Figure 8-1展示了一個1-of-2 的多重簽名的公鑰腳本:
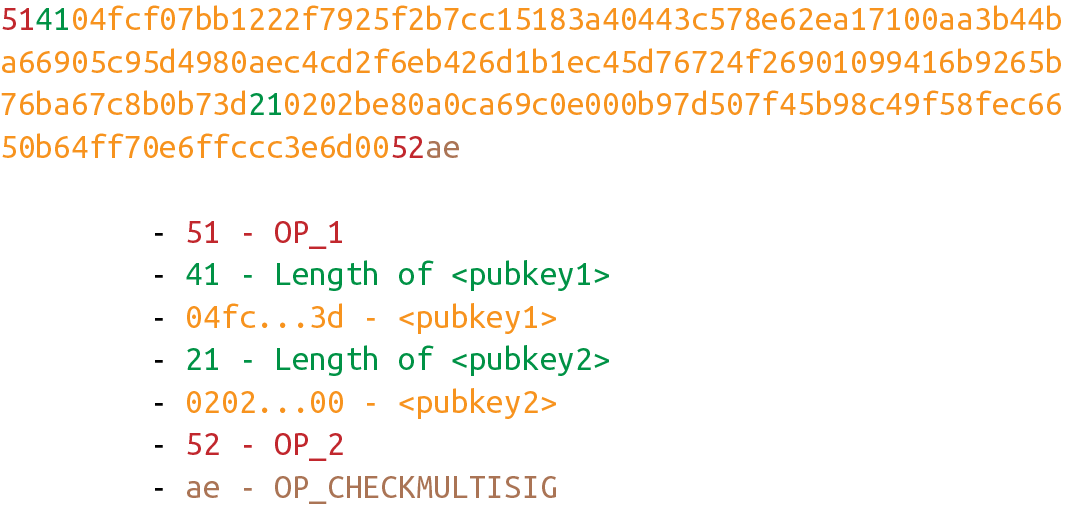
Figure 8-1 裸多簽公鑰腳本
上面的例子雖然很長,但在裸多簽中已經是比較小的了。p2okh 的公鑰簽名有25個字節,但上面的裸多簽公鑰腳本長度為101字節(顯然使用壓縮SEC格式的公鑰會略微減少長度),但這僅僅是1-of-2 的多重簽名。Figure 8-2是對應的簽名腳本。

Figure 8-2 裸多簽的簽名腳本
對於這個1-of-2的多簽名output,我們只需要一個簽名就可以解鎖,所以其長度也相對小。但如果是一個5-of-7的需要5個DER格式的簽名,那麼簽名腳本的長度就會非常長(大約360個字節)。圖Figure 8-3為合併後的簽名腳本和公鑰腳本。
Figure 8-3. 合併後的裸多簽的腳本
這裡我們概括地使用m-of-n的多重簽名(m 和n 可以是任意從1到 包括20在內的整數,給小整數的操作符安排到OP_16, 把整數18壓入棧要使用操作符0x0112,我們使用相同的方法處理17到20 的整數)。腳本計算初始狀態如圖Figure 8-4。
Figure 8-4. 裸多簽的初始狀態
OP_0把數字0壓入棧(Figure 8-5)。
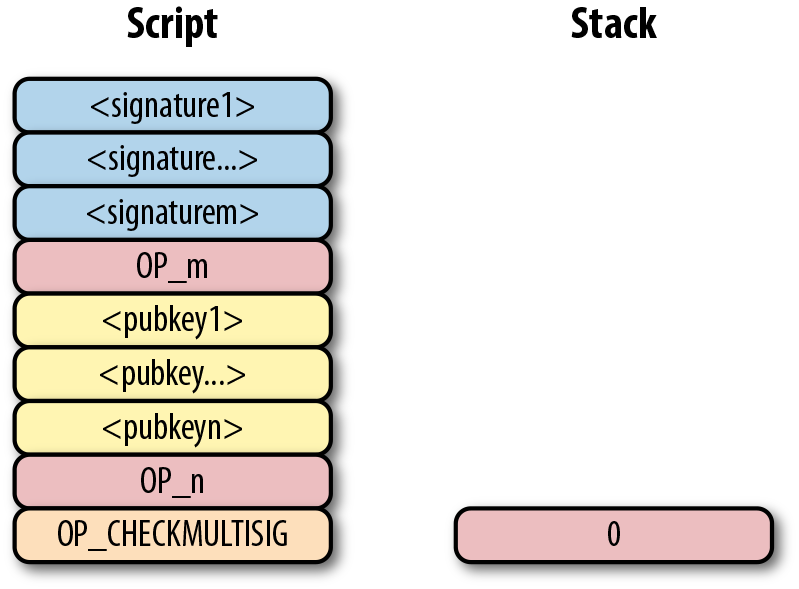
Figure 8-5. 裸多簽的第一步
簽名屬於元素。我們我們直接把他們壓入棧(Figure 8-6)。
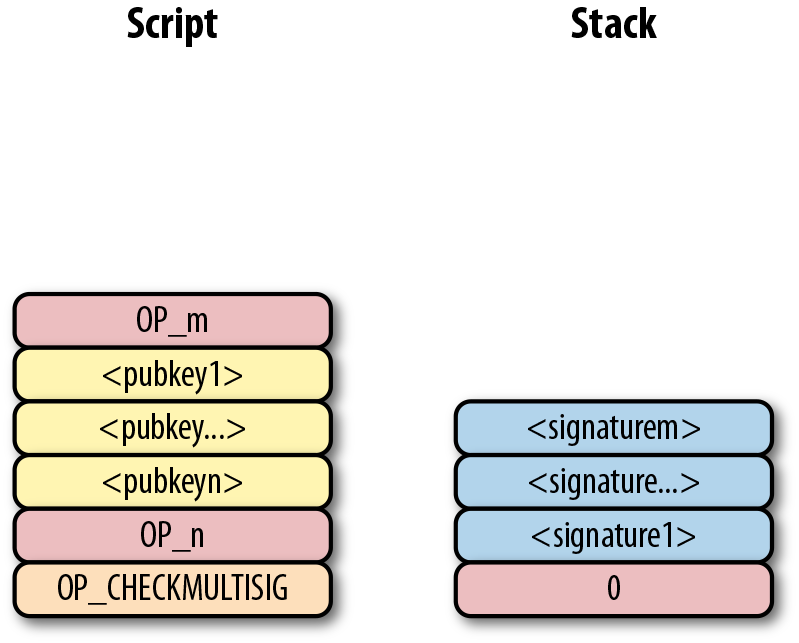
Figure 8-6. 裸多簽的第二步
OP_m把數字m壓入棧,公鑰也會被壓入棧,OP_n會把 n 壓入棧(Figure 8-7)。
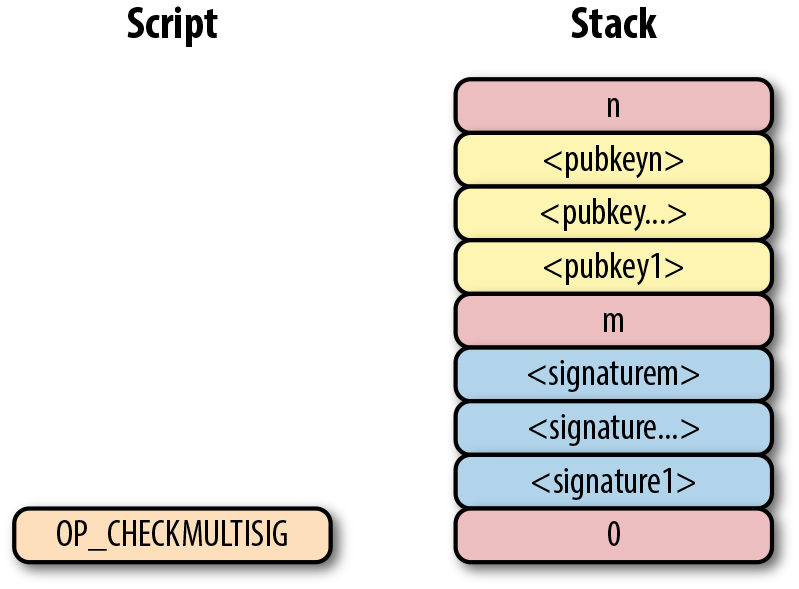
Figure 8-7. 裸多簽的第三步
此時,OP_CHECKMULTSIG 會消耗 m+n+3 個元素(參見OP_CHECKMULTISIG 的差一錯誤),如果簽名用的 m 個不同的公鑰來自公鑰腳本中的 n 個公鑰,則簽名是有效的,向棧中壓入1。否則 壓入0。假設簽名是有效的,則棧中只有一個元素 1,這也就驗證了合併後的腳本。(Figure 8-8)。
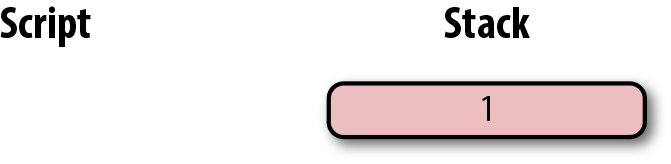
Figure 8-8. 裸多簽腳本計算結束
|
OP_CHECKMULTISIG 的差一錯誤
OP_CHECKMULTISIG 操作符理應消耗元素 m 和對應的 m 個不同的簽名、 n 和對應的 n 個公鑰。所以消耗的元素總數應當為2(元素 m 和元素 n) +m(簽名) +n(公鑰)。但不幸的是,OP_CHECKMULTISIG操作符消耗了比 2+m+n 多一個元素。因為OP_CHECKMULTISIG會消耗 m+n+3 個元素,我們需要在棧中額外增加一個元素(我們的例子中使用的額是OP_0)來防止失敗。 操作符並不會對這個額外的元素做任何計算,所以這個元素也可以是任意的。為了克服延展性,實際上大部分比特幣網路的節點廣播交易時會要求額外的元素為OP_0,否則節點拒絕廣播。注意,如果我們只有 m+n+2 個元素時,OP_CHECKMULTSIG會計算失敗,因為沒有的元素供該操作符使用,合併的腳本也就是不合法的,進而導致交易不合法。 |
8.2. 實現OP_CHECKMULTISIG
在m-of-n 的裸多簽中,棧中從棧頂依次是數字 n、 n 個公鑰、數字 m 、 m 個簽名 和最後的由於差一錯誤被過濾的一個元素,在op.py中的OP_CHECKMULTISIG 中大致實現如下:
def op_checkmultisig(stack, z):
if len(stack) < 1:
return False
n = decode_num(stack.pop())
if len(stack) < n + 1:
return False
sec_pubkeys = []
for _ in range(n):
sec_pubkeys.append(stack.pop())
m = decode_num(stack.pop())
if len(stack) < m + 1:
return False
der_signatures = []
for _ in range(m):
der_signatures.append(stack.pop()[:-1])#1
stack.pop()#2
try:
raise NotImplementedError #3
except (ValueError, SyntaxError):
return False
return True\#1 我們假定每個DER的簽名都是使用SIGHASH_ALL的簽名類型。
\#2 我們通過消耗掉棧頂的元素,不對其做任何處理來解決差一錯誤。
\#3 該部分需要你在下面的練習中完成。
8.3. 裸多簽的問題
裸多簽雖然實現有一些醜陋,但還是能正常使用的。它避免了單點故障問題,只需要 n 中的 m 個私鑰就能解鎖對應的UTXO。output的多重簽名很多使用場景,尤其是在商業實體中。但裸多簽也有下面的一些問題:
-
如果公鑰腳本中包含多個不同的公鑰,這會使得公鑰腳本非常的長。不同於p2pkh甚至p2pk類型的公鑰腳本,很難通過語音甚至短信傳遞。
-
由於output 非常長,大概為普通p2pkh類型的output 的5到10倍,對節點來說需要更多資源來處output。節點需要維護UTXO集,追蹤記錄體積大的公鑰腳本會更昂貴。一個大的output在記錄到快速訪問儲存(例如 RAM)時也會成本更高。
-
另外由於允許公鑰腳本非常長,裸多簽有可能被濫用。在高度為230009的區塊中,中本聰原始白皮書的完整版pdf文檔被編碼到下面的交易:
54e48e5f5c656b26c3bca14a8c95aa583d07ebe84dde3b7dd4a78f4e4186e713
交易的創建者將比特幣白皮書的pdf 文檔拆分成多個64字節為單位小區塊,然後將其製作成無效的未壓縮公鑰。白皮書最後編碼成一個 947個 1-of-3 的裸多簽output。這些output 也不能被使用但全節點的utxo集合卻必須對他們做索引。這對每個全節點都是負擔,在這種情況下,即濫用裸多簽。
為了化解這些問題,支付到腳本雜湊(pay-to-script-hash,p2sh)誕生了。
8.4. 支付到腳本雜湊(p2sh)
支付到腳本雜湊格式的交易是對長地址或者公鑰腳本的一個通用的解決方案。比裸多簽更複雜的公鑰腳本也很容易構造,也會和裸多簽一樣面對很多問題。
p2sh解決方案是獲取Script指令集的雜湊,並在之後揭露其原來的Script指令集。在2011年比特幣引入支付到腳本雜湊(p2sh)時 引起了很多爭議。也有很多其他方案,但正如我們看到的,雖然p2sh有缺陷,但能解決問題。
在p2sh 中,出現如圖Figure 8-9的模式時,會執行特殊的計算規則。
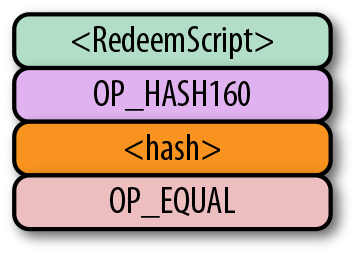
Figure 8-9. 支付到腳本雜湊模式(p2sh)執行特殊模式
如果該指令集以棧頂為1作為計算結果,那麼會解析RedeemScript(贖回腳本,Figure 8-9中頂部的元素)並將其添加到Script的指令集。在BIP0016中引入了這個特殊的模式,實現了比特幣BIP0016 的軟體會(對2011年後的交易)做對該模式的檢查。只有與這個模式完全一致並且計算結果為1時,RedeemScript 中的指令才會加入到Script 指令。
雖然看上去旁門左道,在我們實現它之前,讓我們再進一步瞭解其如何運作。
比如說有一個2-of-2 的裸多簽的公鑰腳本。(Figure 8-10)
Figure 8-10. 支付到腳本雜湊 (p2sh,pay-to-script-hash)的贖回腳本
我們要把它轉換成p2sh格式,這需要對腳本做雜湊並將腳本放在手邊,以方便我們解鎖時使用。我們稱之為贖回腳本(RedeemScript),因為贖回腳本只在贖回解鎖比特幣時才公開。我們將贖回腳本的雜湊作為公鑰腳本(Figure 8-11)。

Figure 8-10. 支付到腳本雜湊 (p2sh,pay-to-script-hash)的公鑰腳本
和公鑰腳本一致,我們此處贖回腳本使用的雜湊函數也是hash160。我們把資產以贖回腳本的雜湊鎖定,需要在解鎖時揭露。
構造p2sh 的簽名腳本時需要公開並解鎖贖回腳本。這裡你可能好奇,贖回腳本儲存在哪裡呢。直到交易被真正地贖回解鎖,贖回腳本才會進入區塊鏈,所以贖回腳本必須要儲存到交易構造者的p2sh地址中。 如果贖回腳本丟失且不能被重建,那麼其資產也就丟失了。我們保存贖回腳本非常重要。
|
保存贖回腳本的重要性
如果你以p2sh 地址接收比特幣,確保你儲存並備份了贖回腳本!更好的做法是讓重構贖回腳本更方便。 |
2-of-2 的多簽的簽名腳本如下圖Figure 8-12。
Figure 8-12. 支付到腳本雜湊(p2sh)的簽名腳本
合併的腳本的過程如圖Figure 8-13。
合併後的p2sh 腳本
和之前一樣,由於OP_CHECKMULTISIG 漏洞,OP_0也出現在腳本中。理解p2sh的關鍵是如圖Figure 8-14的執行序列。
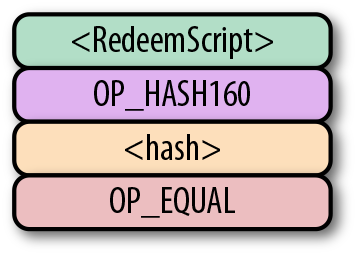
Figure 8-14. p2sh模式執行特殊規則
在執行這個序列時,如果棧內為1,那麼贖回腳本會被添加到Script 的指令集。也就是如果我們公開的贖回腳本的hash160 和公鑰腳本中的hash160一致,那麼贖回腳本就會如同公鑰腳本一樣計算。我們對贖回腳本做雜湊來鎖定資產,並把其雜湊而不是贖回腳本提交到區塊鏈上。我們稱這類公鑰腳本為支付到腳本雜湊(pay-to-script-hash)。
我們來仔細研究它是如何運行的。我們腳本的指令集開始(Figure 8-15)。
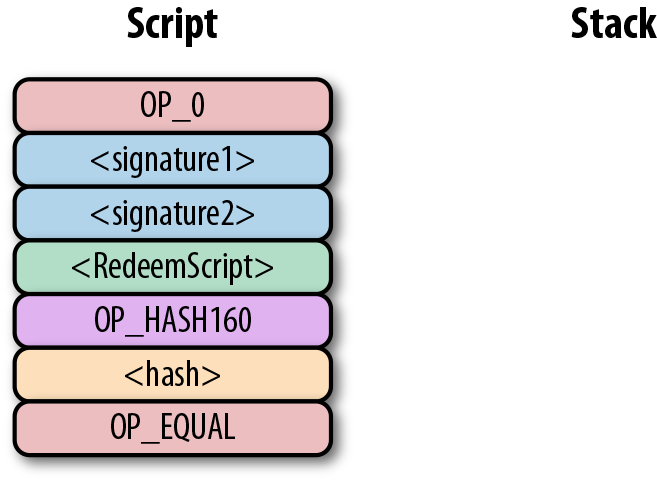
Figure 8-15. p2sh 開始計算
OP_0 首先會被壓入棧,之後兩個簽名和贖回腳本的雜湊也會被直接壓入棧,如圖Figure 8-16。
Figure 8-16. p2sh 的第一步
OP_HASH160 會對贖回腳本做雜湊,計算後的棧如圖Figure 8-17。
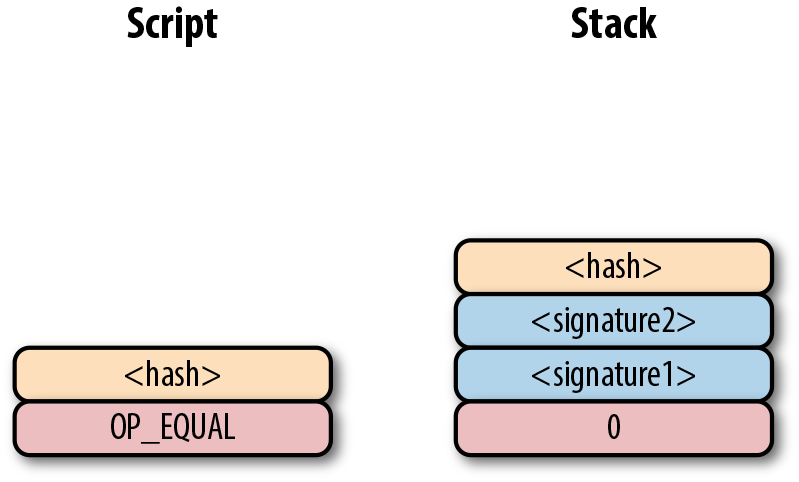
Figure 8-17. p2sh 的第二步
20個字節的雜湊將會被壓入棧(Figure 8-18)。
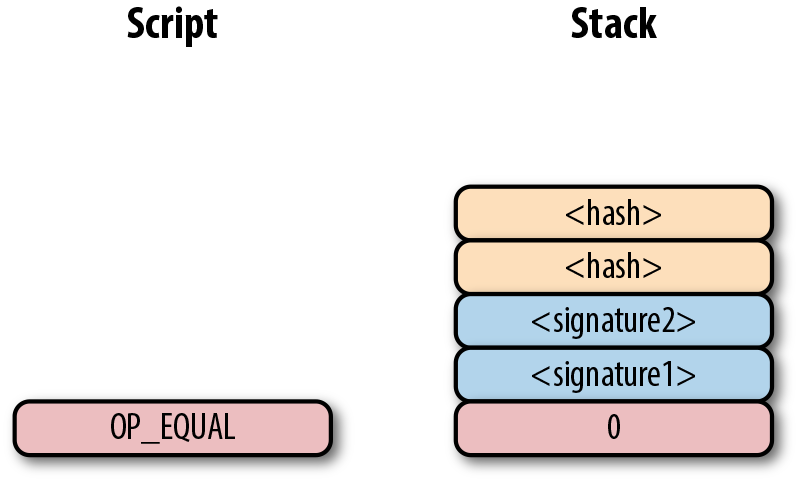
Figure 8-18. p2sh 的第三步
最後,OP_EQUAL 會比較堆頂的兩個元素,如果使用的軟體沒有實現BIP0016,那麼計算將以Figure 8-19結束計算。
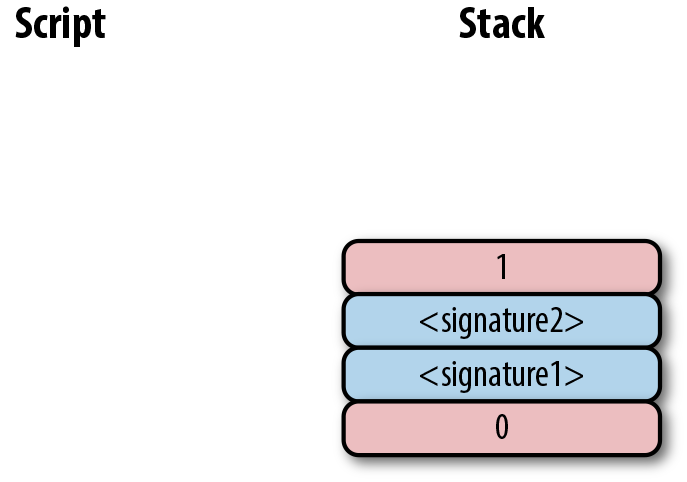
Figure 8-19. 沒有實現BIP0016的軟體的p2sh計算結果
對沒有實現BIP0016的節點,假設兩個雜湊是相同的,年麼其計算結果為合法。
對於目前佔絕大多數的實現了BIP0016的節點將會解析贖回腳本並將其作為Script 指令(Figure 8-20)。
Figure 8-20. p2sh 的贖回腳本
解析後的內容將會進入Script 的指令集(Figure 8-21)。
Figure 8-21 p2sh 的第四步
OP_2向棧中壓入數字2。兩個公鑰隨後壓入棧,最後一個OP_2將另一個數字2 壓入棧(Figure 8-22)。
Figure 8-22. p2sh 的第五步
OP_CHECKMULTISIG 消耗 m+n+3 個元素,也就是整個棧。這個過程和裸多重簽名一樣(Figure 8-23)。

Figure 8-23. 實現了BIP0016軟體結束p2sh 的計算
贖回腳本的替換實現有些旁門左道,需要在比特幣軟體中實現特殊處理的相關代碼。為什麼不採用更直接簡明符合直覺的方法呢?BIP0012是當時與其競爭的一個提案,使用OP_EVAL的操作符,實現起來也更優雅。使用BIP0012的公鑰腳本如圖Figure 8-24。
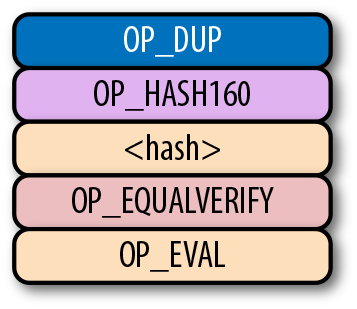
Figure 8-24 OP_EVAL 指令將根據為棧頂增加額外的指令
OP_EVAL 會消耗對應的一個元素並將其解析為Script指令並追繳到指令集中。
不幸的是這個更優雅的設計帶來一個不受歡迎的副作用,圖靈完備性。圖靈完備並不是一個好的特性,這會使得智能合約語言的安全性更難保證(參考第六章)。因此,雖然BIP0016實現非常曲折,但出於安全考慮,我們還是選擇了BIP0016。BIP0016(p2sh)在2011年實現,至今仍然是比特幣網路協議的一部分。
8.5. 實現p2sh
我們需要特殊處理模式,包括贖回腳本、OP_HASH160、雜湊值和OP_EQUAL。在script.py中的evalueate 方法會處理這類特殊情況:
class Script:
...
def evaluate(self, z):
...
while len(commands) > 0:
command = commands.pop(0)
if type(command) == int:
...
else:
stack.append(cmd)
if len(cmds) == 3 and cmds[0] == 0xa9 \
and type(cmds[1]) == bytes and len(cmds[1]) == 20 \
and cmds[2] == 0x87:#1
cmds.pop()#2
h160 = cmds.pop()
cmds.pop()
if not op_hash160(stack):#3
return False
stack.append(h160)
if not op_equal(stack):
return False
if not op_verify(stack):#4
LOGGER.info('bad p2sh h160')
return False
redeem_script = encode_varint(len(cmd)) + cmd#5
stream = BytesIO(redeem_script)
cmds.extend(Script.parse(stream).cmds)#6
\#1 0xa9 對應 OP_HASH160,0x87對應 OP_EQUAL。我們要檢測接下來的三個指令來確定這是BIP0016的特殊模式。
\#2 我們知道這是OP_HASH160,所以我們從棧中將其彈出。類似我們也知道下一個指令是20字節的雜湊值,第三個指令OP_EQUAL,我們在上級的if中檢測過。
\#3 我們計算OP_HASH160,將20個字節的雜湊壓入棧,OP_EQUAL如正常運算。
\#4 棧應該剩元素1,將由op_verify來檢測(OP_VERIFY 消耗堆頂一個元素,不向棧返回任何元素)。
\#5 由於我們希望解析贖回腳本,我們要前綴其長度。
\#6 我們將解析後的指令追加到指令集中。
8.5.1. 更複雜的腳本
p2sh 還帶來了一個好處,贖回腳本可以長到520字節,即通過OP_PUSHDATA2壓入的最大的元素。多重簽名只是p2sh 的一種應用。你可以通過腳本來定義更負複雜的邏輯,比如「提供三個公鑰中的兩個(2 of 3)或者七個其他公鑰中的五個(5 of 7 )時可以解鎖資產」。p2sh的主要特性時帶來了靈活性的同時還縮減了UTXO集合的大小,將儲存的責任交給了使用者。
在第13章中,我們通過p2sh實現了隔離見證(segwit)的向後兼容。 (向後兼容,和軟體行業常見的向前兼容相反。由於比特幣的升級成本非常高還涉及到新舊共識如何統一,所以一種低成本的方案是讓舊軟體兼容新版本的軟體,即向後兼容,另一種說法是軟分叉(soft fork))。
8.5.2. 地址
我們使用了類似p2pkh計算地址的方法來計算p2sh地址。hash160前綴一個字節,後綴一個校驗和(checksum)。
主網的p2sh使用0x05字節,在經過base58轉換後會變成3。測試鏈p2sh使用0xc4字節,對應的base58為2。我們可以使用helper.py 中的encode_base58_checksum函數來計算地址,如下:
>>> from helper import encode_base58_checksum
>>> h160 = bytes.fromhex('74d691da1574e6b3c192ecfb52cc8984ee7b6c56')
>>> print(encode_base58_checksum(b'\x05' + h160))
3CLoMMyuoDQTPRD3XYZtCvgvkadrAdvdXh8.5.5. p2sh簽名驗證
和p2pkh一樣,最難的部分也還是簽名的驗證。 p2sh的簽名驗證與第七章中討論的p2pkh不同。
不像p2pkh每個簽名都有一個對應的公鑰。在p2sh中我們 有一些公鑰(贖回腳本中的SEC格式公鑰)但對應的簽名數量(簽名腳本中的DER格式簽名)可以小於等於公鑰數量。好在簽名必須和公鑰的順序一致否則簽名會被判定非法。
一旦我們有一個特定的簽名和公鑰,我們只需要獲得簽名雜湊 z 就可以判定簽名是否合法(Figure 8-25)。

Figure 8-25. 驗證p2sh的input
和p2pkh類似,獲得簽名雜湊是p2sh簽名驗證過程中最難的部分。我們接下來詳細討論。

第二步 將p2sh的被簽名input的簽名腳本替換為贖回腳本
每個p2sh的input有對應的贖回腳本。我們將贖回腳本放置在之前清空的簽名腳本的位置(Figure 8-27)。這和p2pkh使用公鑰腳本不同。

Figure 8-27. 將我們要檢測的input的簽名腳本替換為贖回腳本
第三步 追加雜湊類型
最後,我們在結尾附加長度為4個字節的雜湊類型,和p2pkh一樣。SIGHASH_ALL對應的整數時1,我們需要將其小端序編碼成四字節,最後交易會如Figure 8-28。

Figure 8-28. 追加交易類型(SIGHASH_ALL),01000000
我們對上面的處理後交易做hash256並以大端序編碼的整數就是我們的 z,我們獲取簽名雜湊的的代碼如下:
>>> from helper import hash256
>>> modified_tx = bytes.fromhex('0100000001868278ed6ddfb6c1ed3ad5f8181eb0c7a385aa0836f01d5e4789e6bd304d87221a000000475221022626e955ea6ea6d98850c994f9107b036b1334f18ca8830bfff1295d21cfdb702103b287eaf122eea69030a0e9feed096bed8045c8b98bec453e1ffac7fbdbd4bb7152aeffffffff04d3b11400000000001976a914904a49878c0adfc3aa05de7afad2cc15f483a56a88ac7f400900000000001976a914418327e3f3dda4cf5b9089325a4b95abdfa0334088ac722c0c00000000001976a914ba35042cfe9fc66fd35ac2224eebdafd1028ad2788acdc4ace020000000017a91474d691da1574e6b3c192ecfb52cc8984ee7b6c56870000000001000000')
>>> s256 = hash256(modified_tx)
>>> z = int.from_bytes(s256, 'big')
>>> print(hex(z))
0xe71bfa115715d6fd33796948126f40a8cdd39f187e4afb03896795189fe1423c現在我們已經獲得了 z,我們可以從簽名腳本和贖回腳本中獲取SEC格式的公鑰和DER格式的簽名(Figure 8-29)。

Figure 8-29. DER 簽名和SEC公鑰
現在我們驗證簽名了:
>>> from ecc import S256Point, Signature
>>> from helper import hash256
>>> modified_tx = bytes.fromhex('0100000001868278ed6ddfb6c1ed3ad5f8181eb0c7a38\
5aa0836f01d5e4789e6bd304d87221a000000475221022626e955ea6ea6d98850c994f9107b036\
b1334f18ca8830bfff1295d21cfdb702103b287eaf122eea69030a0e9feed096bed8045c8b98be\
c453e1ffac7fbdbd4bb7152aeffffffff04d3b11400000000001976a914904a49878c0adfc3aa0\
5de7afad2cc15f483a56a88ac7f400900000000001976a914418327e3f3dda4cf5b9089325a4b9\
5abdfa0334088ac722c0c00000000001976a914ba35042cfe9fc66fd35ac2224eebdafd1028ad2\
788acdc4ace020000000017a91474d691da1574e6b3c192ecfb52cc8984ee7b6c5687000000000\
1000000')
>>> h256 = hash256(modified_tx)
>>> z = int.from_bytes(h256, 'big')#1
>>> sec = bytes.fromhex('022626e955ea6ea6d98850c994f9107b036b1334f18ca8830bfff\
1295d21cfdb70')
>>> der = bytes.fromhex('3045022100dc92655fe37036f47756db8102e0d7d5e28b3beb83a\
8fef4f5dc0559bddfb94e02205a36d4e4e6c7fcd16658c50783e00c341609977aed3ad00937bf4\
ee942a89937')
>>> point = S256Point.parse(sec)
>>> sig = Signature.parse(der)
>>> print(point.verify(z, sig))
True\# 1 z 的計算在之前的代碼有解釋。
我們已經驗證了要解鎖p2sh多簽資產的需要兩個簽名中的一個。
9. 第九章 區塊
所有將一些地址上的比特幣轉移到其他地址的交易行為都是由簽名來解鎖的,或者說被授予了使用權。 簽名保證了發送者對於交易的授權,但是如果發送者將同一筆交易發送給多個地址會發生什麼呢?「保險箱」的擁有人也有可能將它轉出兩次。這樣的行為被稱為「雙花問題」(double spending)。就好像給出了一張可能會失效的支票一樣,接受的人需要確認這筆交易最終是有效的。
而這正是我們引入區塊(block)這一比特幣的關鍵性創新的原因。我們可以將區塊理解為一種排序交易的方式。如果我們將所有的交易有條有理地排好順序,那麼防止「雙花問題」的出現就只需要讓任何較晚出現的,與原交易內容有衝突的交易無效就可以了。我們也可以認為在有衝突的情況下,這是將早些出現的交易認定為有效。
如果我們可以將所有的交易按照時間排序,那麼實現這樣的規則還是容易的。(這裡的規則指的是將早些出現的交易認定為有效交易,將有衝突的,晚些出現的交易認定為無效)不幸的是,這需要網路中的節點都針對「交易的順序」這一件事達成共識,而這會導致大量的網路傳輸開銷。當然,我們也可以選擇將一大批交易排序後打包然後一天同步一次,但會顯得非常地不實際因為交易的清算只能一天執行一次而且在清算之前交易的有效性都是沒有定論的。
比特幣在這兩個極端的例子中間找到了一個妥協的方案:每10分鐘清算一批交易。在這裡這一批批的交易我們稱之為一個個區塊。在這一章中,我們會考慮如何解析區塊以及如何驗證工作量證明(proof-of-work)。我們會從一種名為創區塊交易(coinbase transaction)的特殊交易開始,它也是每一個區塊裡面的第一筆交易。
9.1. 創區塊交易
創區塊交易 (coinbase transaction)與同名的美國公司並沒有任何關係(這裡指美國科技公司Coinbase)。創世交易(根據比特幣協議)是每一個區塊的第一筆交易,同時也是唯一能夠產生新比特幣的交易的交易類型。創世交易的交易outputs的所有權將由挖礦主體來指定,通常交易input包含區塊中其他所有交易的交易手續費以及我們所說的出區塊獎勵(block reward)。
創區塊交易讓礦工與挖礦的存在具有價值。[figure-9-1]展示了一筆創區塊交易。
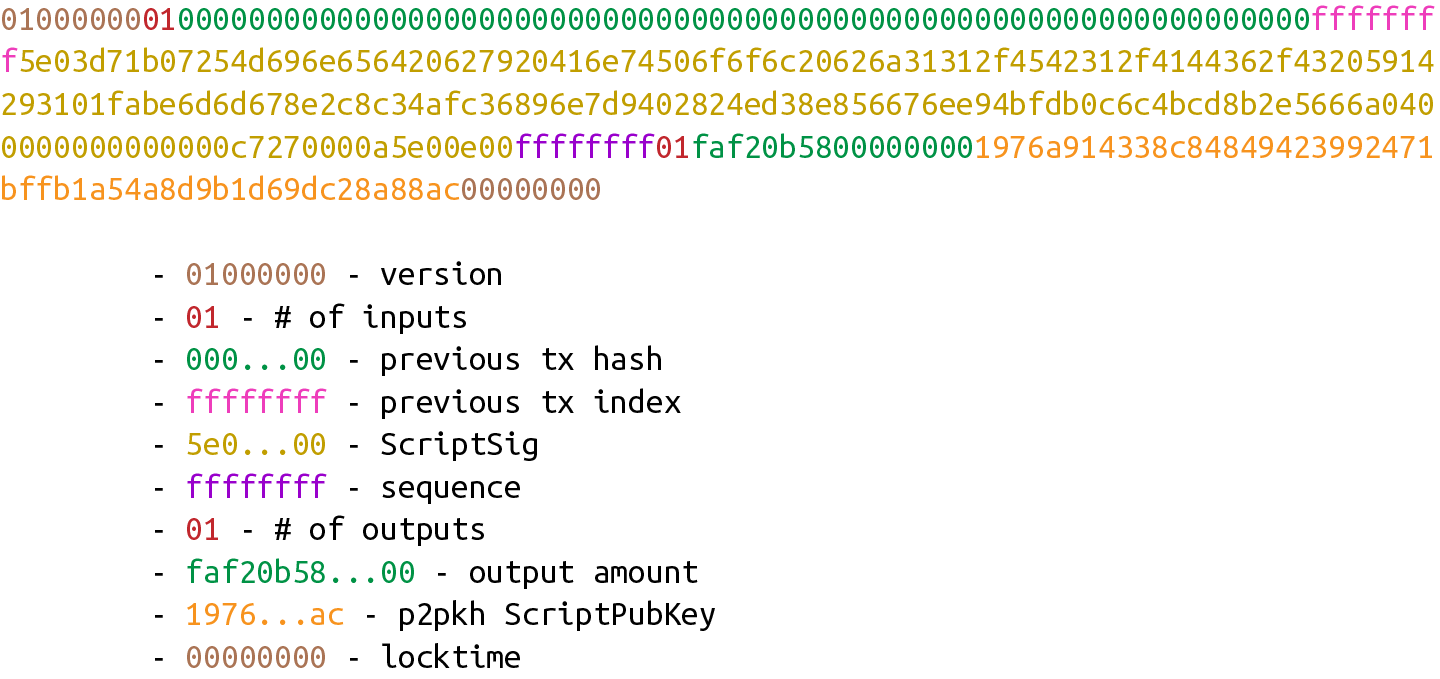
Figure 9-1. 創區塊交易
除了一下幾個方面,比特幣網路中的一個創區塊交易與其他的交易並沒有什麼區別:
-
創區塊交易一定只有一個交易input
-
這個交易input的父交易雜湊是32個字節的00
-
這個交易input的父交易序號是ffffffff
以上三點決定了一筆交易是否是創區塊交易。
9.1.2. 簽名腳本 ScriptSig
創區塊交易並沒有一筆父交易用於引用,因此它的交易input並不解鎖任何東西。那麼它的簽名腳本裡面都有什麼呢?
創區塊交易的簽名腳本由成功「挖出」該交易的礦工設置。簽名腳本的主要限制是最少兩個字節以及最多不超過100個字節。除了這些限制以及BIP0034規定的內容(我們在下一節會講到),在沒有公鑰腳本的情況下簽名腳本可以是礦工定義的任何自洽的內容。 讓我們來看一下創世區塊(genesis block,指區塊鏈的第一個區塊)的創區塊交易:
4d04ffff001d0104455468652054696d65732030332f4a616e2f32303039204368616e63656c6c6f72206f6e206272696e6b206f66207365636f6e64206261696c6f757420666f722062616e6b73
這個簽名腳本是中本聰寫下的,裡面包含了一條信息:
>>> from io import BytesIO
>>> from script import Script
>>> stream = BytesIO(bytes.fromhex('4d04ffff001d0104455468652054696d6573203033\ 2f4a616e2f32303039204368616e63656c6c6f72206f6e206272696e6b206f66207365636f6e64\ 206261696c6f757420666f722062616e6b73'))
>>> s = Script.parse(stream)
>>> print(s.cmds[2])
b'The Times 03/Jan/2009 Chancellor on brink of second bailout for banks'這是2009年1月3號倫敦泰晤士報的頭條標題。 這證明瞭創世區塊是由這個時間(或者這個時間之後)創建的,而不是在這之前。其他的創區塊交易的簽名腳本裡面也包含著類似的一些隨意的數據。
9.1.3. BIP0034
BIP0034規定了創區塊交易的簽名腳本裡面的第一個元素。這是因為曾經的礦工們使用同一個創區塊交易來創建區塊。
因為對交易內容進行hash256運算的結果是確定的,所以使用相同的創區塊交易意味著交易ID是相同的。為了防止交易ID對重復,Gavin Andresen寫下了BIP0034,這是一個把新創建的區塊高度寫入作為創區塊交易簽名腳本的第一個元素的軟分叉規則。
這個以小端序整型寫入的高度值必須等於區塊的高度(即從創世區塊開始到該區塊的數量)。由於區塊高度都是不一樣的,因此同一個創區塊交易不可能出現在不同區塊中。以下是我們怎麼解析[figure-9-1]中創區塊交易裡面區塊高度的方法:
>>> from io import BytesIO
>>> from script import Script
>>> from helper import little_endian_to_int
>>> stream = BytesIO(bytes.fromhex('5e03d71b07254d696e656420627920416e74506f6f\ 6c20626a31312f4542312f4144362f43205914293101fabe6d6d678e2c8c34afc36896e7d94028\ 24ed38e856676ee94bfdb0c6c4bcd8b2e5666a0400000000000000c7270000a5e00e00'))
>>> script_sig = Script.parse(stream)
>>> print(little_endian_to_int(script_sig.cmds[0]))
465879一個創區塊交易透露了它在哪一個區塊裡面。不同區塊中的創區塊交易都會有不同的簽名腳本,因此就會有不同的交易ID。這個規則一直被執行因為如果不這樣的話就會出現不同區塊有相同的創區塊交易ID。
9.2. 區塊頭
一個區塊指的是一批交易,而區塊頭(block header)則是這批被包含在區塊里的交易的元數據。圖[figure-9-2]中顯示的區塊頭包含了一下內容:
-
Version 版本號
-
Previous block 父區塊
-
Merkle root 默克爾根
-
Timestamp 時間戳
-
Bits 工作量/工作數
-
Nonce 序號
Figure 9-2. 解析後的區塊
區塊頭指的是區塊的元數據。跟交易不同,[figure-9-2]里列出的區塊頭裡的每一個內容都是定長的;一個區塊頭一定是80個字節長度。到目前為止,一共有大概550,000個區塊,或者說大約有45MB的區塊頭數據。而整個區塊鏈的體量則大概有200G,因此區塊頭的體量僅佔總題量的0.023%。區塊頭的體量如此小是一個非常重要的特性,我們會在第11章簡易支付驗證(simplified payment verification)介紹這個內容。
類似於交易ID,區塊ID是區塊頭的小端序表示,經過hash256運算後的16進制編碼結果。區塊ID其實非常的有趣:
>>> from helper import hash256
>>> block_hash = hash256(bytes.fromhex('020000208ec39428b17323fa0ddec8e887b4a7\
c53b8c0a0a220cfd0000000000000000005b0750fce0a889502d40508d39576821155e9c9e3f5c\
3157f961db38fd8b25be1e77a759e93c0118a4ffd71d'))[::-1]
>>> block_id = block_hash.hex()
>>> print(block_id)
0000000000000000007e9e4c586439b0cdbe13b1370bdd9435d76a644d047523這個區塊ID事實上是我們在創建一個新區快時定義的prev_block,我們將一個新的區塊建立在這個區塊之上。現在,你可能注意到這個ID以許多的0開頭。在我們研究更多的區塊頭內容之後,我們會在第170頁(原書170頁)的「工作量證明」一節中講到。
根據我們已經掌握的知識,我們可以開始編寫Block 類了:
class Block:
def __init__(self, version, prev_block, merkle_root, timestamp, bits, nonce):
self.version = version
self.prev_block = prev_block
self.merkle_root = merkle_root
self.timestamp = timestamp
self.bits = bits
self.nonce = nonce9.2.4. Version 版本號
在一個常見的軟體中,版本號指的是一系列特定的特性。對於一個區塊,這個概念是相似的,版本號反映的是產生這個區塊的軟體的特性。在過去它被用來當作是一種表示產生區塊的礦工已經準備好新的單一特性版本部署的方法。版本號2意味著這個挖礦軟體兼容BIP0034,我們在之前介紹過這個特性用於在創區塊交易中引入區塊高度。版本號3意味著這個挖礦軟體兼容BIP0066,這個特性強制要求嚴格的DER編碼。版本號4意味著這個軟體兼容BIP0065,這個特性兼容了新的操作碼OP_CHECKLOCKTIMEVERIFY。
不幸的是,版本號的增加意味著在網路中一次只能有一個特性起作用。為了緩解這個情況,開發者們提出了BIP0009,這個方案允許最多同時能有29個不同的特性兼容。
BIP0009通過將4個字節的區塊頭的前3個比特固定為001表示礦工正在使用兼容BIP0009的軟體。如果前三個比特一定要為001的話,那麼其他的比特幣軟體就會將版本號欄位解讀為一個大於或等於4的數字,而這個為4的版本號就是在啓用BIP0009之前的最後一個版本號。
這樣做也就意味著在16進制中,第一個字符一定會是2或者3。剩下的29個比特則可以被礦工用來分配給不同的軟分叉特性上以表示其兼容性。例如,第0比特位(最右邊)可以改成1用來表示對一個軟分叉兼容,第1個比特位(從最右邊起第二個)可以改成1表示對另一個軟分叉兼容,第2個比特位(從最右邊起第三個)可以改成1表示對另一個軟分叉兼容,以此類推。
BIP0009要求在一個以2016個區塊為區間(這是一次難度調整的區間;本章之後會提到相關概念)的內的95%個區塊在網路中的軟分叉特性激活前都表達成功兼容。在使用BIP0009的軟分叉之前就已經兼容BIP0068/BIP0112/BIP0113(OP_CHECKSEQUENCEVERIFY以及相關修改)和BIP0141了。比特幣軟體分別使用0或者1來表示對這些BIP的兼容性。BIP0091的兼容方法類似於BIP0009只是區塊要求降到了80%且區間變短了,因此BIP0009並不是嚴格要求要兼容的。第4個比特位用來表示BIP0091兼容與否。
確認這些特性也相對直接:
>>> from io import BytesIO
>>> from block import Block
>>> b = Block.parse(BytesIO(bytes.fromhex('020000208ec39428b17323fa0ddec8e887b\ 4a7c53b8c0a0a220cfd0000000000000000005b0750fce0a889502d40508d39576821155e9c9e3\ f5c3157f961db38fd8b25be1e77a759e93c0118a4ffd71d')))
>>> print('BIP9: {}'.format(b.version >> 29 == 0b001)) #1
BIP9: True
>>> print('BIP91: {}'.format(b.version >> 4 & 1 == 1)) #2
BIP91: False
>>> print('BIP141: {}'.format(b.version >> 1 & 1 == 1)) #3
BIP141: True#1 >>操作符是右位移操作符,它會捨棄掉最右邊的29個比特位
#2 &操作符是「按位與」操作符。在我們的例子里,我們先右移4位然後確認最右位是不是1
#3 我們將1移到右邊因為BIP0141被分配在第1個比特位上
9.2.8. 父區塊
所有的區塊都會指向一個父區塊。這也是為什麼這樣的數據結構被稱為區塊鏈。所有的區塊串聯起來延伸到最早的那一個區塊,或者我們稱作創世區塊。父區塊欄位以許多00字節結尾,我們將在本章後面討論更多相關內容。
9.2.10. 時間戳
時間戳是Unix格式的且佔用4個字節。Unix時間戳是指從1970年1月1日開始到現在的秒數。這個時間戳有兩個用處:驗證區塊裡面交易中基於時間戳的鎖定時間以及用於每2016個區塊計算一次新的工作量要求/雜湊目標/難度。這裡說的鎖定時間適用於在一個特定時間點區塊里的一筆交易,但是BIP0113將這個行為從使用當前區塊時間戳改為過去11個區塊的時間戳中位數(MTP)。
[[169]]
|
比特幣會因為時間戳溢出嗎?
比特幣區塊頭上的時間戳欄位是4個字節,或者說32個比特。這意味著如果Unix時間戳超過 232-1 就裝不下了。 232-1 秒接近136年這也意味著在2106年(從1970年後的第136年)時就沒有足夠的空間了。 許多人錯誤地以為我們只有68年( 231 是68年),但是這只適用於有符號的整型,在時間戳的表示上我們其實還有1個比特位可以用,因此事實上可以用到2106年。 在2106年,區塊頭會需要進行一些軟分叉升級因為區塊頭裡的時間戳無法再繼續增加了。 |
9.3. 工作量證明
工作量證明是保證比特幣安全,從深層次上講允許比特幣去中心化挖礦的方法。計算出一個工作量證明將授予礦工把一個區塊添加到區塊鏈上的權力。 因為工作量證明非常地稀有(此處指不易計算),因此也不是件簡單的事情。但是由於工作量證明是客觀的且易於驗證的,任何人只要願意參與都可以成為一個礦工。
計算工作量證明被稱作「挖礦」是有一個很棒的原因的。就好像真實生活中的挖礦一樣,礦工們都在尋找一些資源。一個典型的案例是在金礦的挖掘過程中在得到1盎司的黃金之前要處理45噸的渣土和岩石。 這是因為金礦非常的稀有。然而,一旦黃金被挖掘出來了,就十分容易驗證這些黃金的真假。我們有化學檢測,試金石等許多相對廉價的方法來測試黃金是不是真的。
同樣的,工作量證明是一個提供一種非常稀有的數學結果的數字。為了計算工作量證明,比特幣網路中的礦工需要先計算像45噸渣土一樣多的數學問題,而驗證工作量證明則必計算出它容易的多。
所以到底什麼是工作量證明?讓我們先從我們之前看到的hash256的區塊頭開始看起:
020000208ec39428b17323fa0ddec8e887b4a7c53b8c0a0a220cfd0000000000000000005b0750fce0a889502d40508d39576821155e9c9e3f5c3157f961db38fd8b25be1e77a759e93c0118a4ffd71d
>>> from helper import hash256
>>> block_id = hash256(bytes.fromhex('020000208ec39428b17323fa0ddec8e887b4a7c53b8c0a0a220cfd0000000000000000005b0750fce0a889502d40508d39576821155e9c9e3f5c3157f961db38fd8b25be1e77a759e93c0118a4ffd71d'))[::-1]
>>> print('{}'.format(block_id.hex()).zfill(64)) #1
0000000000000000007e9e4c586439b0cdbe13b1370bdd9435d76a644d047523#1 我們有意將這個數字以64個16進制的數字打印出來是為了展示它在256位數字裡有多小
sha256被用來生成均勻分布的值。在這一點下,我們使用兩次的sha256,或者說hash256來產生一個隨機數。像這樣隨機生成一個的如此小的256位的數字的概率非常小。一個256位的數字的第一位為0的概率是0.5,前兩位為0的概率是0.25,前三位為0的概率是0.125以此類推。請注意,每一個0在16進制中僅表示為四個0比特位。在這個例子里,我們的前73個比特位都是0,它的概率是 0.573 或者說是 frac11022 。這是一個非常小的概率。平均而言,在找到一個這麼小的數字之前需要生成 1022 (或者說10萬億萬億)個隨機的256位的數字。換句話說,我們平均需要計算 1022 次雜湊來找到一個這麼小的數。類似的,計算工作量證明的過程就是要求我們處理 1022 個比特的渣土和岩石來找到我們的數字黃金。
9.3.1. 礦工如何生成新的雜湊
礦工們怎麼確定從哪一堆渣土開始處理來找到符合條件的工作量證明呢?這也是我們引入Nonce序號的原因。礦工通過改變序號欄位然後借以改變區塊頭的雜湊值。
不幸的是4個字節(32個比特)的序號欄位(或者說礦工有 232 個有可能性的序號值嘗試)對於工作量證明而言並不夠。現代ASIC設備每秒能計算多於 232 不同的雜湊值。以螞蟻礦機S9為例,算力為12T每秒。這相當於是約每秒 243 次雜湊,這也意味著它可以在0.0003秒內遍歷完所有的序號值空間。
當礦工在用完序號值之後,就只能改變創區塊交易,因此改變了默克爾根,然後礦工會得到一個全新的序號值空間。另一個選擇是改變版本號或者使用公開是ASICBOOST。關於改變區塊內一筆交易後會改變默克爾根的機制將會在第11章討論。
9.3.2. 計算目標
工作量證明要求比特幣里每個區塊頭的雜湊一定要小於某一個特定的目標。計算目標指的是一個256比特的直接由比特空間里直接計算的數字(在我們的例子里指的是e93c0118)。計算目標平均而言相比於一個256位的數字要小得多。
比特空間事實上是兩個不同的數字。第一個是指數,也就是最後一個字節。第二個是系數,也就是小端序里的另外三個字節。計算目標的公式如下:
- target=coefficient × 256exponent-3
以下是我們怎麼用Python從給定的比特空間里計算目標:
>>> from helper import little_endian_to_int
>>> bits = bytes.fromhex('e93c0118')
>>> exponent = bits[-1]
>>> coefficient = little_endian_to_int(bits[:-1])
>>> target = coefficient * 256**(exponent - 3)
>>> print('{:x}'.format(target).zfill(64)) #1 0000000000000000013ce9000000000000000000000000000000000000000000#1 我們有意將這個數字以64個16進制的數字打印出來是為了展示它在256位數字裡有多小
一個有效的工作量證明是一個當我們用小端序整型表示時小於計算目標的區塊頭雜湊。工作量證明的雜湊值都極度稀有,而挖礦的過程就是找出這些雜湊的過程。為了找到一個小於計算目標的工作量證明的值,整個比特幣網路作為一個整體必須計算 3.8× 1021 次雜湊值,當一個區塊被找到時大概要花費10分鐘。為了讓我們更好地理解這個些數值,讓我們來舉一個例子,目前世界上最好的GPU需要運行50000年來找到一個小於計算目標的工作量證明的值。
我們可以校驗下面這個區塊頭的雜湊滿足工作量證明的要求:
>>> from helper import little_endian_to_int
>>> proof = little_endian_to_int(hash256(bytes.fromhex('020000208ec39428b17323\ fa0ddec8e887b4a7c53b8c0a0a220cfd0000000000000000005b0750fce0a889502d40508d3957\ 6821155e9c9e3f5c3157f961db38fd8b25be1e77a759e93c0118a4ffd71d')))
>>> print(proof < target) #1
True#1 target已經在上面計算過了
我們可以看到用64位的16進制的數值表示出來工作量證明的值小於計算目標
TG: 0000000000000000013ce9000000000000000000000000000000000000000000 ID: 0000000000000000007e9e4c586439b0cdbe13b1370bdd9435d76a644d047523
9.3.4. 計算難度
計算目標對於人類而言很難理解。計算目標指的是雜湊值的上限,而人類卻不容易分辨一個180比特的和一個190比特的數字。前者比後者小1000倍,但是站在計算目標的角度上,這麼大的數字也不容易處理。
為了使得不同的計算目標更容易做比較,我們引入計算難度的概念。有趣的是計算難度是計算目標的倒數,這樣使得比較更容易些。它的公式為:
- difficulty = 0xffff × 256^(0x1d-3) / target
代碼如下:
>>> from helper import little_endian_to_int
>>> bits = bytes.fromhex('e93c0118')
>>> exponent = bits[-1]
>>> coefficient = little_endian_to_int(bits[:-1]) >>> target = coefficient*256**(exponent-3)
>>> difficulty = 0xffff * 256**(0x1d-3) / target >>> print(difficulty)
888171856257.3206比特幣中創世區塊的計算難度是1。這也讓我們更好的理解現在比特幣主網路中的計算難度是什麼樣的。計算難度可以被理解為現在挖礦比剛開始挖礦時要難多少。上面的例子里的挖礦的計算難度大約是比特幣剛開始時的8880億倍。
我們經常能在區塊瀏覽器或者比特幣價格服務上看到計算難度,因為它是一個更直觀的理解產生一個新區塊要花多少力氣的指標。
9.3.6. 校驗工作量證明
我們已經學習了工作量證明可以通過計算區塊頭的hash256的值並且以小端序整型表示來獲得。如果這個值比計算目標小,那麼這是一個有效的工作量證明。反之,這個區塊是無效的因為工作量證明不充分。
9.3.8. 計算難度調整
在比特幣中,每2016個區塊為一組被稱為一個難度調整週期。在每一個難度調整週期的結尾,計算目標都會根據以下這個公式去調整:
- 時間增量=(難度調整週期的第一個區塊的時間戳)-(難度調整週期的最後一個區塊的時間戳)
- 新的計算目標=上一個計算目標*時間增量/(2周)
時間增量需要這麼計算的原因是如果超過了8周,那麼我們就使用8周來計算,如果小於3.5天,我們就使用3.5天來計算。在這種計算方法下,計算難度才不會在兩個方向的任意一個上增加或者減少超過4倍。因此,計算目標每次最多增加或者減少4倍。
如果每一個區塊平均都需要10分鐘來產生,那麼2016個區塊就需要20160分鐘。每天有1440分鐘而2016個區塊則代表著需要 20160/1440=14 天來產生。計算難度調整的作用是是的每個區塊的產生時間能夠回歸到10分鐘。這意味著長遠看來區塊的產生時間會趨向10分鐘即是有許多算力進入或者離開需網路。
新的工作量證明的值的計算應該用當前難度調整週期和上一個難度調整週期的最後一個區塊的時間戳。中本聰卻不巧有著一個錯位錯誤因為時間戳增量計算中他用的一個難度調整週期的第一個和最後一個區塊的時間戳。因此時間戳增量是基於2015個區塊的而不是2016個區塊。
我們如下編寫計算公式對應的代碼:
>>> from block import Block
>>> from helper import TWO_WEEKS #1
>>> last_block = Block.parse(BytesIO(bytes.fromhex('00000020fdf740b0e49cf75bb3d5168fb3586f7613dcc5cd89675b0100000000000000002e37b144c0baced07eb7e7b64da916cd3121f2427005551aeb0ec6a6402ac7d7f0e4235954d801187f5da9f5')))
>>> first_block = Block.parse(BytesIO(bytes.fromhex('000000201ecd89664fd205a37566e694269ed76e425803003628ab010000000000000000bfcade29d080d9aae8fd461254b041805ae442749f2a40100440fc0e3d5868e55019345954d80118a1721b2e')))
>>> time_differential = last_block.timestamp - first_block.timestamp
>>> if time_differential > TWO_WEEKS * 4: #2
... time_differential = TWO_WEEKS * 4
>>> if time_differential < TWO_WEEKS // 4: #3
... time_differential = TWO_WEEKS // 4
>>> new_target = last_block.target() * time_differential // TWO_WEEKS
>>> print('{:x}'.format(new_target).zfill(64)) 0000000000000000007615000000000000000000000000000000000000000000#1 請注意 TWO_WEEKS=60*60*24*14 是兩周的的秒數
#2 這確保了如果我們花了超過8周來產生過去的2015個區塊,我們就不會把計算難度降低太多
#3 這確保了如果我們花了少於3.5天來產生過去的2015個區塊,我們就不會把計算難度增加太多
請注意在這裡我們只需要區塊頭來計算下一個區塊頭計算目標。一旦我們知道了這個目標,我們可以把這個目標轉換為比特位。這個逆過程的代碼如下:
def target_to_bits(target):
'''Turns a target integer back into bits'''
raw_bytes = target.to_bytes(32, 'big')
raw_bytes = raw_bytes.lstrip(b'\x00')#1
if raw_bytes[0] > 0x7f:#2
exponent = len(raw_bytes) + 1
coefficient = b'\x00' + raw_bytes[:2]
else:
exponent = len(raw_bytes)#3
coefficient = raw_bytes[:3]#4
new_bits = coefficient[::-1] + bytes([exponent]) #5
return new_bits#1 去掉所有的0前綴
#2 比特位格式是一種表示簡要地表示極大數的方法,並且它也可以被用來表示正數和負數。如果系數中的第一個比特位是1,那麼比特空間應該是一個負數。因為計算目標對於我們而言一直是一個正數,如果第一個比特位是1,我們就將所有的值位移1個字節。
#3 指數指的是在256比特中這個數字有多長
#4 系數是這個256比特數的前三位數字
[[175 ]]
#5 系數是小端序的,在比特格式中指數是最後一個數
如果一個區塊的計算量沒有被正確地使用難度調整公式計算,我們可以很安心地拒絕這個區塊
9.3.9. Exercise 12
給定2016個區塊的難度調整區間的第一個區塊和最後一個區塊,計算新的計算量:
第471744個區塊:
000000203471101bbda3fe307664b3283a9ef0e97d9a38a7eacd8800000000000000000010c8aba8479bbaa5e0848152fd3c2289ca50e1c3e58c9a4faaafbdf5803c5448ddb845597e8b0118e43a81d3
第473759個區塊:
02000020f1472d9db4b563c35f97c428ac903f23b7fc055d1cfc26000000000000000000b3f449fcbe1bc4cfbcb8283a0d2c037f961a3fdf2b8bedc144973735eea707e1264258597e8b0118e5f00474
10. 第十章 比特幣網路通訊
比特幣採用的點對的通訊為其帶來了網路的穩定性。在本書撰寫時有超過65000個節點在比特幣網路上運行並持續地通訊。
比特幣的網路是廣播網路和流言網路(gossip network)。每個節點都在聲明不同的交易,區塊和已知的其他節點信息。經過多年的發展,協議的內容已經非常豐富並擴展了很多功能。
值得強調的是,網路協議本身並不是達成共識所必備的。可以使用其他協議將相同的數據從一個節點發送到另一個節點,這並不會影響區塊鏈。
請牢記上面的觀點,我們將在本章中討論如何使用網路協議來 發送請求,接收數據和驗證區塊頭。
10.1. 網路消息
網路消息的格式如圖[figure-10-1]。
前四個字節是固定不變的,是比特幣網路的魔數(network magic)。魔術字節在網路編程中很常見,因為通信是異步的並且可能是間歇性的。如果通信中斷(比如,使用的手機信號失靈),魔數字節會為消息接收者提供一個啓動位置。魔數字節也被用來做網路的標識符,舉例來說,你不會希望你的比特幣節點連接到萊特幣節點。因此萊特幣也有一個不同的魔數。比特幣的測試鏈也使用了與主鏈不同的魔數 0b110907,是比特幣主鏈魔數f9beb4d9 的補碼。
Figure 10-1. 網路消息樣例-封裝了真實的payload
接下來的12個字節是指令欄位,用來描述payload所攜帶的信息。有非常多種指令,詳細列表可以參考 文檔:https://en.bitcoin.it/wiki/Protocol_documentation。 指令欄位是人類可讀的,例子中消息是ASCII字節表示的「版本」(version),剩餘部分以0字節填充。 (譯注: 即我們對 76 65 72 73 69 6f 6e 轉換成 ASCII字符集後為 "version"。)
再之後的四個字節為payload 的長度,以小端序編碼。如我們在第五章和第九章討論的那樣,對於playload 這一變長欄位,必須要有長度欄位。 232 可以代表大約40億字節,所以payload可以多達4GB,但相關的客戶端會拒絕超過32MB 的payload。在[figure-10-1]的例子中, 我們的payload大小為101字節。
接下來的四個字節為校驗和(checksum)欄位。這裡使用的checksum算法非常少見,對payload 做hash256後取前四位。我們說它少見的原因是網路協議的校驗和一般都帶有糾錯能力但hash256並沒有。可能是因為hash256也經常出現在比特幣協議的其他地方,所以這裡也使用了它。
我們需要編寫一個新的class 來處理網路信息:
NETWORK_MAGIC = b'\xf9\xbe\xb4\xd9'
TESTNET_NETWORK_MAGIC = b'\x0b\x11\x09\x07'
class NetworkEnvelope:
def __init__(self, command, payload, testnet=False):
self.command = command
self.payload = payload
if testnet:
self.magic = TESTNET_NETWORK_MAGIC
else:
self.magic = NETWORK_MAGIC
def __repr__(self):
return '{}: {}'.format(
self.command.decode('ascii'),
self.payload.hex(),
)10.2. 解析payload
每個指令都有自己單獨的payload 規範。[figure-10-2] 為對版本號(version)解析後的payload。
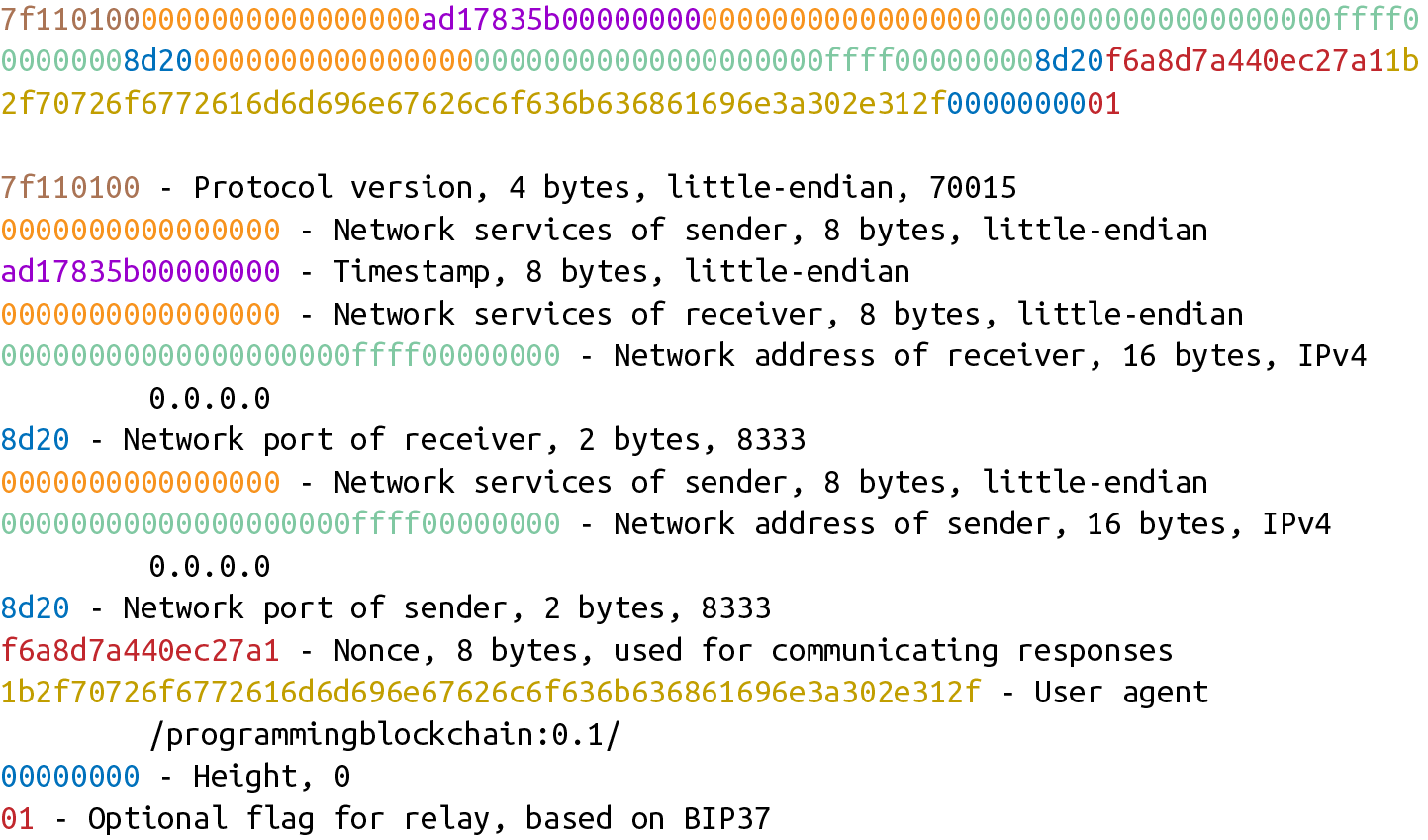
Figure 10-2. 解析版本號
這些欄位旨在為兩個節點提供足夠的信息,以便節點之間的溝通。
第一個欄位是網路協議版本,它指定傳遞的信息的類型。service欄位給出了節點的服務能力。 timestamp欄位有8個字節(和區塊頭的4個字節不同),是小端序的Unix 時間戳。
IP地址可以是IPv6,IPv4 和 OnionCat(指TOR的 .onion地址到IPv6的映射)。如果是IPv4,對應欄位的前12個字節為00000000000000000000ffff,最後的4個字節為IP。端口以小端序編碼佔用兩個字節。主網默認使用8333,16進制的小端序對應為8d20。
(譯注:洋蔥網路是一種匿名通訊技術,Tor是一個佔主導地位的洋蔥網路的實現,使用了Tor網路的用戶可以匿名的發送信息)
Nonce 是節點用來檢測自身連接的數字。user agent欄位會標識正在運行的軟體,高度或者最新區塊(height or latest block)欄位幫助其他節點瞭解sender節點同步到了哪個高度。
Relay欄位 會被布隆過濾器使用,我們會在第十二章討論。
設定合理的默認值後,我們的VersionMessage 類的代碼如下:
class VersionMessage:
command = b'version'
def __init__(self, version=70015, services=0, timestamp=None,
receiver_services=0,
receiver_ip=b'\x00\x00\x00\x00', receiver_port=8333,
sender_services=0,
sender_ip=b'\x00\x00\x00\x00', sender_port=8333,
nonce=None, user_agent=b'/programmingbitcoin:0.1/',
latest_block=0, relay=False):
self.version = version
self.services = services
if timestamp is None:
self.timestamp = int(time.time())
else:
self.timestamp = timestamp
self.receiver_services = receiver_services
self.receiver_ip = receiver_ip
self.receiver_port = receiver_port
self.sender_services = sender_services
self.sender_ip = sender_ip
self.sender_port = sender_port
if nonce is None:
self.nonce = int_to_little_endian(randint(0, 2**64), 8)
else:
self.nonce = nonce
self.user_agent = user_agent
self.latest_block = latest_block
self.relay = relay至此,我們需要實現這個消息的方法。
10.3. 網路握手
網路握手是節點建立通訊的方式:
-
A 節點想要連接到B節點,發送版本信息到B。
-
B 接受版本信息後,回復verack信息併發送自己的版本信息
-
A 接受 B的版本信息和verack 信息後再回復verack信息
-
B 接受verack信息後,連個節點開始傳遞信息
(譯注 verack 為比特幣社區和軟體創造的新詞彙,ver 代表版本,ack代表確認)
10.4. 連接到比特幣網路
由於其異步特性,網路通信實現非常棘手。出於實驗考慮,我們可以同步地建立網路上的節點的連接:
>>> import socket
>>> from network import NetworkEnvelope, VersionMessage
>>> host = 'testnet.programmingbitcoin.com'#1
>>> port = 18333
>>> socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
>>> socket.connect((host, port))
>>> stream = socket.makefile('rb', None)#2
>>> version = VersionMessage()#3
>>> envelope = NetworkEnvelope(version.command, version.serialize())
>>> socket.sendall(envelope.serialize())#4
>>> while True:
... new_message = NetworkEnvelope.parse(stream)#5
... print(new_message)#1 這是作者建立的測試鏈節點服務,測試鏈的端口使用默認的18333。
#2 這裡創建了流(stream)來從socket中讀取數據。通過這種方式構造的流可以傳遞給其他所有的parse 方法。
#3 握手的第一步是發送版本號消息。
#4 我們需要將消息封裝到正確的envelope中。
#5 這行代碼將從我們連接的socket中讀取任何接收到的消息。
通過這種方式連接到其他節點,我們只能在接收消息後才能發送並且不能智能地同時響應多個消息。一個更健壯的時間是使用異步庫(比如python3 中的 asyncio庫)來無阻塞的收發消息。
我們還需要一個確認版本號消息(verack message)的類,代碼如下:
class VerAckMessage:
command = b'verack'
def __init__(self):
pass
@classmethod
def parse(cls, s):
return cls()
def serialize(self):
return b''VerAckMessage 是最小的網路消息。
創建如下的類來自動化地為我們處理通訊:
class SimpleNode:
def __init__(self, host, port=None, testnet=False, logging=False):
if port is None:
if testnet:
port = 18333
else:
port = 8333
self.testnet = testnet
self.logging = logging
self.socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.socket.connect((host, port))
self.stream = self.socket.makefile('rb', None)
def send(self, message):#1
'''Send a message to the connected node'''
envelope = NetworkEnvelope(
message.command, message.serialize(), testnet=self.testnet)
if self.logging:
print('sending: {}'.format(envelope))
self.socket.sendall(envelope.serialize())
def read(self):#2
'''Read a message from the socket'''
envelope = NetworkEnvelope.parse(self.stream, testnet=self.testnet)
if self.logging:
print('receiving: {}'.format(envelope))
return envelope
def wait_for(self, *message_classes):
'''Wait for one of the messages in the list'''
command = None
command_to_class = {m.command: m for m in message_classes}
while command not in command_to_class.keys():
envelope = self.read()
command = envelope.command
if command == VersionMessage.command:
self.send(VerAckMessage())
elif command == PingMessage.command:
self.send(PongMessage(envelope.payload))
return command_to_class[command].parse(envelope.stream())#1 send 方法會通過socket 發送消息。假定command 的屬性和serialize 方法在message 對象中已經實現。
#2 read 方法會從socket 中讀取消息。
#3 wait_for 方法會等待幾個指令中的任何一個(指message 類中的command)。這個方法為對象帶來的異步的特性,這使得後續的編程更方便。一個商用的節點肯定不會使用了類似的實現。
目前我們已經實現了一個節點,我們可以與另一個節點進行通訊握手了:
>>> from network import SimpleNode, VersionMessage
>>> node = SimpleNode('testnet.programmingbitcoin.com', testnet=True)
>>> version = VersionMessage()
>>> node.send(version)
>>> verack_received = False
>>> version_received = False
>>> while not verack_received and not version_received:
... message = node.wait_for(VersionMessage, VerAckMessage)
... if message.command == VerAckMessage.command:
... verack_received = True
... else:
... version_received = True
... node.send(VerAckMessage())#1 大部分的節點並不關心版本信息中的IP欄位。我們可以使用默認設置連接,全部程序也會正常運行。
#2 我們通過發送版本號消息來開啓通訊握手。
#3 當接收 verack 和version 消息後才結束。
#4 我們預期會接收一個我們自己版本號的確認消息(verack)和連接的節點的版本消息。但我們不確定兩個消息哪個先接收到。
10.5. 獲取區塊頭信息
目前我們已經準備好連接節點的代碼了,那麼下一步應該做什麼呢?當一個節點連接到網路時,區塊頭是最重要數據,需要我們首先獲取並且驗證。對於全節點來說,下載區塊頭之後會使得全節點可以異步地從多個節點中獲取數據,並行下載區塊。對於輕節點來說,下載區塊頭之後可以對每個區塊進行工作量證明的驗證。我們將在第十一章看到,輕節點的客戶端將能夠對網路的數據實現存在性證明,但這需要輕節點有區塊頭信息。
節點可以在不佔用太多帶寬的情況下傳輸區塊頭。獲取區塊頭的指令是getheader,如下圖[figure-10-3]。

Figure 10-3. 解析後的getheaders 指令
我們首先處理協議的版本號,之後是包含的區塊頭的組的數量(當數字大於1時意味著可能存在網路分叉)。接下來是本次消息要傳輸的起始區塊頭和結束區塊頭(譯注:用來指定我們需要哪些區塊頭數據)。如果我們把結束區塊社團設定成000…000,這表明我們需要其他節點盡可能地多給出區塊頭信息。我們最多能獲取一次獲取2000個區塊,差不多等於一次難度調整週期(2016 區塊)。
實現如下:
class GetHeadersMessage:
command = b'getheaders'
def __init__(self, version=70015, num_hashes=1,
start_block=None, end_block=None):
self.version = version
self.num_hashes = num_hashes#1
if start_block is None:#2
raise RuntimeError('a start block is required')
self.start_block = start_block
if end_block is None:
self.end_block = b'\x00' * 32#3
else:
self.end_block = end_block[[184]]
#1 在本章中,我們假設區塊頭的組的數量為1。更健壯的實現方式會處理超過1個區塊組,但我們能總是能通過單一區塊組的方式同步區塊頭數據。
#2 開始的區塊是必須的。否則我我們不能構造一個符合規則的消息。
#3 我們假定null 為結束區塊,即在定義結束區塊(ending block)時,我們希望其他節點盡可能多的同步給我們數據。
10.6. 區塊頭回應(Headers Response)
此時我們已經可以創建一個節點,通訊握手,並請求區塊頭了。
>>> from io import BytesIO
>>> from block import Block, GENESIS_BLOCK
>>> from network import SimpleNode, GetHeadersMessage
>>> node = SimpleNode('mainnet.programmingbitcoin.com', testnet=False)
>>> node.handshake()
>>> genesis = Block.parse(BytesIO(GENESIS_BLOCK))
>>> getheaders = GetHeadersMessage(start_block=genesis.hash())
>>> node.send(getheaders)我們還需要對應的接收區塊頭的方法。其他節點在收到我們的請求後會返回給我們headers指令。即包含區塊頭的列表([figure-10-4]),我們已經在第九章中學習過如何解析它們。HeaderMessage 類可以在解析時利用之前的實現。
解析後的headers
header消息以一個變長整數表達的header數量作為起始,範圍為1到2000 的閉區間。如我們之前討論的,每個區塊頭有80個字節。接下來的消息內容是交易的數量。在header消息中,這個數字永遠為1。雖然看上去令人困惑,但這是因為我們我們請求了區塊頭而沒有請求交易。作為節點同時發送交易數量的信息則是因為header消息要與區塊消息(block message)的格式兼容,而區塊消息包含區塊頭,交易數量,最後是每個交易的詳細信息。通過設定交易數量為0,我們就可以復用解析一個完整區塊的代碼:
class HeadersMessage:
command = b'headers'
def __init__(self, blocks):
self.blocks = blocks
@classmethod
def parse(cls, stream):
num_headers = read_varint(stream)
blocks = []
for _ in range(num_headers):
blocks.append(Block.parse(stream))#1
num_txs = read_varint(stream)#2
if num_txs != 0:#3
raise RuntimeError('number of txs not 0')
return cls(blocks)#1 區塊通過Block 類的parse 方法解析,使用相同的數據流(stream)。
#2 交易的數量總是0,也是區塊解析過程最後剩餘的部分。
#3 如果解析的交易數量不是0,一定是我們哪裡出錯了。
如果我們成功的啓動了區塊鏈網路,我們可以開始下載區塊頭,驗證他們提供的工作量證明,其中校驗區塊頭中的難度調整系數的代碼如下:
>>> from io import BytesIO
>>> from network import SimpleNode, GetHeadersMessage, HeadersMessage
>>> from block import Block, GENESIS_BLOCK, LOWEST_BITS
>>> from helper import calculate_new_bits
>>> previous = Block.parse(BytesIO(GENESIS_BLOCK))
>>> first_epoch_timestamp = previous.timestamp
>>> expected_bits = LOWEST_BITS
>>> count = 1
>>> node = SimpleNode('mainnet.programmingbitcoin.com', testnet=False)
>>> node.handshake()
>>> for _ in range(19):
... getheaders = GetHeadersMessage(start_block=previous.hash())
... node.send(getheaders)
... headers = node.wait_for(HeadersMessage)
... for header in headers.blocks:
... if not header.check_pow():#1
... raise RuntimeError('bad PoW at block {}'.format(count))
... if header.prev_block != previous.hash():#2
... raise RuntimeError('discontinuous block at {}'.format(count))
... if count % 2016 == 0:
... time_diff = previous.timestamp - first_epoch_timestamp
... expected_bits = calculate_new_bits(previous.bits, time_diff)#4
... print(expected_bits.hex())
... first_epoch_timestamp = header.timestamp#5
... if header.bits != expected_bits:#3
... raise RuntimeError('bad bits at block {}'.format(count))
... previous = header
... count += 1
ffff001d
ffff001d
ffff001d
ffff001d
ffff001d
ffff001d
ffff001d
ffff001d
ffff001d
ffff001d
ffff001d
ffff001d
ffff001d
ffff001d
ffff001d
6ad8001d
28c4001d
71be001d#1 驗證工作量證明。
#2 檢測當前區塊是否位於上一區塊之後。
#3 根據上一個區塊數據和難度週期的計算,檢測當前比特位/目標/難度(bits/target/difficulty)是否符合。
#4 當區塊恰好在難度調整區塊時,計算接下來的週期的比特位/目標/難度(bits/target/difficulty)。
#5 儲存難度週期的第一個區塊,方便之後難度週期調整時的比特位(bits)。
注意,因為測試鏈難度調整的算法和上面代碼不同,所以代碼不能在測試鏈中使用。在測試鏈,為了平穩的產出區塊,當測試鏈20分鐘沒有新區塊產生時,難度會下降1,這使得挖掘一個新區塊非常容易。這樣的設計使得測試者可以在沒有昂貴的挖礦設備的情況下,指出挖出區塊,保證網路穩定。一個約30美元的USB特殊集成電路(ASIC)可以在最小難度時每分鐘產出幾個區塊。
11. 第十一章 簡單支付驗證
在第九章中我們還有一個header 的欄位沒有討論,即默克爾根(merkle root)。要理解默克爾根為什麼有用,我們需要先深刻地瞭解默克爾樹(merkle tree)和其性質。在本章中我們將學習默克爾樹的具體內容並通過存在性證明(proof of inclusion)——這一問題來推動本章內容的學習。
11.1. 動機
對於一個沒有太多硬碟空間、帶寬和計算資源的設備,儲存、接收和驗證整個區塊鏈是非常昂貴的。在本書寫作時,整個區塊鏈的數據大約有200GB,已經超過許多手機的儲存能力。高效地同步數據也非常困難,同時還會佔用大量CPU 資源。如果我們不能把整個區塊鏈同步到手機,我們還有其他方案嗎?有可能在沒有全部數據的情況下在手機上創建一個比特幣錢包嗎?
對於任何錢包來說,我們關心下面兩個場景:
-
支付給其他人
-
接收付款
如果你使用你的比特幣錢包發起支付,那麼驗證支付是否成功的責任在收款者。一旦驗證交易進入區塊鏈並有足夠多確認區塊,交易的對手方會給與你購買的商品或者服務。當你完成支付後,除了等待對手方發送你要交易的東西,你什麼也做不了。
[[189 ]]
當我們是收款者時,我們會遇到如下困難。如果我們連接到比特幣網路並同步了全部數據,我們可以容易驗證交易是否有足夠多的區塊確認,也就能決定我們什麼時候給支付發起人對應的服務和商品。但是我們如果只有手機,而沒有全節點時,我們應該怎麼做呢?
答案在在第九章討論的區塊頭(block header)的默克爾樹欄位。我們在上一章學習了,下載區塊頭並且驗證其是否符合比特幣的共識規則。在本章中,我們將重點證明某個特定交易是否存在於我們所已知的區塊中。由於區塊頭用工作量證明提供了安全性,有存在性證明的交易的所在區塊的產生過程會消耗大量能源。這意味著欺騙你的成本至少也是該區塊的工作量證明的成本。本章接下來的內容會討論什麼是存在性證明和我們如何驗證它。 (譯注:存在性的簡單理解可以是我們想知道一個元素是否在要在一個數據結構中,在本章指交易是否在一個特定的區塊里。簡單的處理方法是下載區塊數據,逐個比對。這不僅消耗硬碟帶寬等資源,效率也非常低,而查詢交易又是一個常見的行為。因此比特幣軟體或者協議引入了默克爾樹來高效的實現存在性證明。)
11.2. 默克爾樹
默克爾樹(Merkle tree)是一種計算機領域的數據結構,它能高效的驗證存在性。 構成默克爾樹需要用到有序列表和加密散列函數(cryptographic hash function)。在本章的語境下,有序列表中的元素指區塊中的交易,雜湊(或者散列)函數指hash256。我們執行下面的算法來構造默克爾樹:
-
使用提供的雜湊函數對有序列表中的所有元素做雜湊。
-
如果列表中只有一個雜湊,結束退出。
-
否則,如果雜湊數量為奇數,我們複製最後一個元素並追加到結尾。這樣我們就有了偶數個雜湊。
-
依次兩兩組合,合併後做雜湊計算,成為每對雜湊的父節點。這樣我們在父節點這一層就只有一半的雜湊了。
-
重復#2。
設計思路是用最後合併的一個雜湊值來「代表」整個有序列表。圖像上理解,一個默克爾樹如圖[figure-11-1]。
底部排的節點我們稱之為樹的葉節點。除了葉節點之外的節點我們稱為中間節點。兩個葉節點一起構造了父節點( HAB 和 HCD )。當我們再計算兩個父節點的父節點時,我們得到了默克爾根。
接下來我們將詳細討論該過程的每個部分。
Figure 11-1. 默克爾樹
|
注意默克爾樹!
在Bitcoin0.4-0.6 的軟體中存在和默克爾根相關的漏洞,詳細內容在CVE-2012-2459中。利用默克爾樹中複製列表最後一個元素的過程,實現了拒絕服務攻擊的手段(denial-of-service vector)。這導致了一些節點對合法的區塊也判定為不合法。 |
11.3. 默克爾樹的父雜湊
根據兩個雜湊值,我們計算出一個新的雜湊值代表兩個雜湊值。由於兩個雜湊值是有序的,我們可以稱之為左雜湊(left hash)和右雜湊(right hash)。我們對合併的左雜湊和右雜湊做雜湊運算,我們計算出父雜湊。下面是計算父雜湊的算法:
-
H= Hashing function
-
P= Parent hash
-
L= Left hash
-
R= Right hash
P=H(L||R)
|| 符號代表拼接(concatenation)。
下面是我們在python 的計算過程:
>>> from helper import hash256
>>> hash0 = bytes.fromhex('c117ea8ec828342f4dfb0ad6bd140e03a50720ece40169ee38bdc15d9eb64cf5')
>>> hash1 = bytes.fromhex('c131474164b412e3406696da1ee20ab0fc9bf41c8f05fa8ceea7a08d672d7cc5')
>>> parent = hash256(hash0 + hash1)
>>> print(parent.hex())
8b30c5ba100f6f2e5ad1e2a742e5020491240f8eb514fe97c713c31718ad7ecd我們對雜湊合併並做雜湊的來計算父雜湊,這樣我們就能方便地證明存在性。具體來說,我們可以通過公開 R 來證明 L 存在於 P 中。也就是說,如果我們像證明 L 在 P 中, P 的構造者可以公開 R ,就可以讓我們知道 L 是 P 的左子葉節點。我們可以將 L 和 R 合併來構造 P 就可以證明 L 曾用來構造 P 。如果 L 不存在於 P ,構造合法的 R 等同於計算出雜湊的原象(preimage),我們都知道這是非常困難的。這就是我們說的存在性證明。
11.4. 父節點層數
如果有序列表的元素超過兩個,我們可以對每對雜湊計算其父節點,我們稱之為計算默克爾父節點層(Merkle parent level)。如果是偶數個雜湊,計算將非常直接,我們依次配對。如果我們有奇數的雜湊,我們需要做些什麼來處理最後剩餘的那個雜湊。我們可以通過複製最後一個元素到尾部來解決。
比如,我們有一個列表[A,B,C],我們在結尾最後加入C 得到[A,B,C,C]。接下來我們就可以計算A 和B 的默克爾父節點 、C和C 的默克爾父節點。最後得到
由於默克爾父節點總是由兩個雜湊構成,默克爾父節點層的數量總是子雜湊數量的一半。如下是我們計算默克爾父節點層的過程:
>>> from helper import merkle_parent
>>> hex_hashes = [
... 'c117ea8ec828342f4dfb0ad6bd140e03a50720ece40169ee38bdc15d9eb64cf5',
... 'c131474164b412e3406696da1ee20ab0fc9bf41c8f05fa8ceea7a08d672d7cc5',
... 'f391da6ecfeed1814efae39e7fcb3838ae0b02c02ae7d0a5848a66947c0727b0',
... '3d238a92a94532b946c90e19c49351c763696cff3db400485b813aecb8a13181',
... '10092f2633be5f3ce349bf9ddbde36caa3dd10dfa0ec8106bce23acbff637dae',
... ]
>>> hashes = [bytes.fromhex(x) for x in hex_hashes]
>>> if len(hashes) % 2 == 1:
... hashes.append(hashes[-1])#1
>>> parent_level = []
>>> for i in range(0, len(hashes), 2):#2
... parent = merkle_parent(hashes[i], hashes[i+1])
... parent_level.append(parent)
>>> for item in parent_level:
... print(item.hex())
8b30c5ba100f6f2e5ad1e2a742e5020491240f8eb514fe97c713c31718ad7ecd
7f4e6f9e224e20fda0ae4c44114237f97cd35aca38d83081c9bfd41feb907800
3ecf6115380c77e8aae56660f5634982ee897351ba906a6837d15ebc3a225df0-
我們將最後的元素在複製到列表中,hash[-1]代表列表的最後一個元素,這讓我們雜湊的數量變成偶數。
-
這是我們在python 中如果步長為2地進行循環,i 一開始值為0,第二次循環 為2,第三次循環為4,循環下去。
上面的代碼計算出了一個新的雜湊值組成的列表,代表了默克爾父節點層。
11.5. 默克爾根
要計算默克爾根,我們就需要迭代地計算默克爾父節點層直到只得到一個雜湊值。比如我們有七個元素從A 到G, 我們可以先計算默克爾父節點層如下:
接下來我們再對其計算默克爾父節點層:
此時我們就剩下兩個元素,所以我們再做一次默克爾父節點,就能得到默克爾根:
H(H(H(A||B)||H(C||D))||H(H(E||F)||H(G||G)))
由於此時已經只有一個雜湊值了,我們完成了默克爾根的計算。每層都會對節點的數量減半,如果我們不斷地計算默克爾父節點層,我們最終會計算出一個最終的雜湊值,被稱為默克爾根:
>>> from helper import merkle_parent_level
>>> hex_hashes = [
... 'c117ea8ec828342f4dfb0ad6bd140e03a50720ece40169ee38bdc15d9eb64cf5',
... 'c131474164b412e3406696da1ee20ab0fc9bf41c8f05fa8ceea7a08d672d7cc5',
... 'f391da6ecfeed1814efae39e7fcb3838ae0b02c02ae7d0a5848a66947c0727b0',
... '3d238a92a94532b946c90e19c49351c763696cff3db400485b813aecb8a13181',
... '10092f2633be5f3ce349bf9ddbde36caa3dd10dfa0ec8106bce23acbff637dae',
... '7d37b3d54fa6a64869084bfd2e831309118b9e833610e6228adacdbd1b4ba161',
... '8118a77e542892fe15ae3fc771a4abfd2f5d5d5997544c3487ac36b5c85170fc',
... 'dff6879848c2c9b62fe652720b8df5272093acfaa45a43cdb3696fe2466a3877',
... 'b825c0745f46ac58f7d3759e6dc535a1fec7820377f24d4c2c6ad2cc55c0cb59',
... '95513952a04bd8992721e9b7e2937f1c04ba31e0469fbe615a78197f68f52b7c',
... '2e6d722e5e4dbdf2447ddecc9f7dabb8e299bae921c99ad5b0184cd9eb8e5908',
... 'b13a750047bc0bdceb2473e5fe488c2596d7a7124b4e716fdd29b046ef99bbf0',
... ]
>>> hashes = [bytes.fromhex(x) for x in hex_hashes]
>>> current_hashes = hashes
>>> while len(current_hashes) > 1:#1
... current_hashes = merkle_parent_level(current_hashes)
>>> print(current_hashes[0].hex())#2
acbcab8bcc1af95d8d563b77d24c3d19b18f1486383d75a5085c4e86c86beed6[[193]]
-
循環的停止條件是只剩下1個雜湊
-
因為我們退出了循環,所以列表中應該只有一個元素
11.6. 區塊中的默克爾根
計算區塊的默克爾根應該也非常簡單,但是由於編碼端序的問題,計算實際上也有些困難。具體來說,我們用小端序來排序默克爾樹的葉節點,當我們用計算出默克爾根後,再用小端序排序一次。
實踐上,我們會在最後將默克爾根倒序之前,我們會先對葉節點做倒序:
>>> from helper import merkle_root
>>> tx_hex_hashes = [
... '42f6f52f17620653dcc909e58bb352e0bd4bd1381e2955d19c00959a22122b2e',
... '94c3af34b9667bf787e1c6a0a009201589755d01d02fe2877cc69b929d2418d4',
... '959428d7c48113cb9149d0566bde3d46e98cf028053c522b8fa8f735241aa953',
... 'a9f27b99d5d108dede755710d4a1ffa2c74af70b4ca71726fa57d68454e609a2',
... '62af110031e29de1efcad103b3ad4bec7bdcf6cb9c9f4afdd586981795516577',
... '766900590ece194667e9da2984018057512887110bf54fe0aa800157aec796ba',
... 'e8270fb475763bc8d855cfe45ed98060988c1bdcad2ffc8364f783c98999a208',
... ]
>>> tx_hashes = [bytes.fromhex(x) for x in tx_hex_hashes]
>>> hashes = [h[::-1] for h in tx_hashes]#1
>>> print(merkle_root(hashes)[::-1].hex())#2
654d6181e18e4ac4368383fdc5eead11bf138f9b7ac1e15334e4411b3c4797d9#1 我們使用python列表推導特性來逆序每一個雜湊
#2 我們最後對默克爾根葉會做一次逆序
我們要計算出一個區塊的默克爾根,所以我們增加tx_hashes 參數:
class Block:
def __init__(self, version, prev_block, merkle_root,
timestamp, bits, nonce, tx_hashes=None):
self.version = version
self.prev_block = prev_block
self.merkle_root = merkle_root
self.timestamp = timestamp
self.bits = bits
self.nonce = nonce
self.tx_hashes = tx_hashes#1 我們現在允許交易雜湊作為區塊block類的初始化的一部分了。在這裡這些交易雜湊需要是有序的。
如果我們掌握一個全節點,我們就能計算出默克爾根並交易區塊中的默克爾根計算是否正確。
11.7. 默克爾樹的使用
目前我們已經掌握了如何構造默克爾樹,我們可以構造並驗證存存在性證明。輕節點可以在不掌握全部區塊內的交易的情況下,獲取我們關心的交易的是否存在的證明([figure-11-2])。
假設我們的輕節點關心兩筆交易,兩筆的交易雜湊 HK,HN 由圖[figure-11-2]中的兩個綠色方區塊代表。一個全節點可以通過發送所有藍色的方區塊的雜湊來完成存在性證明。即 HABCDEFGH,HIJ,HL,HM和HOP 。輕節點將完成下面的計算:
-
HKL = merkle_parent(HK, HL)
-
HMN = merkle_parent(HM, HN)
-
HIJKL = merkle_parent(HIJ, HKL)
-
HMNOP = merkle_parent(HPMN, HOP)
-
HMNOP = merkle_parent(HPMN, HOP)
-
HIJKLMNOP = merkle_parent(HIJKL, HMNOP)
-
HABCDEFGHIJKLMNOP = merkle_parent(HABCDEFGH, HIJKLMNOP)
[[195]]
默克爾根
在圖[figure-11-2],虛線方框的雜湊是輕節點計算出來的。實際上默克爾根是 HABCDEFGHIJKLMNOP ,計算出的默克爾根可以和工作量證明保證的區塊中的默克爾根比對。
簡單支付驗證(SPV proof)有多安全?
全節點可以發送和區塊相關的有限的信息給輕節點,輕節點就可以從新計算默克爾根,如果默克爾根和區塊頭中的一致,我們的關心的交易的存在性得到了證明。雖然不能完全確保交易在最長的區塊鏈內,但可以向輕節點保證,全節點需要花費非常大的雜湊計算量才能完成工作量證明。只要完成工作量證明的收益大於交易的價值,那麼輕節點至少可以確信全節點沒有明確的經濟激勵對輕節點撒謊。
由於區塊頭可以從多個節點獲取,輕節點可以通過這種方式來驗證節點給出的區塊頭是否是當前的最長區塊鏈。一個誠實的節點就可以否決一百個不誠實節點,因為工作量證明是客觀的。因此,輕節點的孤立(也就是能控制輕節點連接到哪些節點)是欺騙輕節點所必備的條件。所以簡單支付驗證(SPV)需要網路上有許多的誠實節點。
另一方面說,輕節點的安全性依賴節點網路的穩定性和完成工作量證明的經濟成本。對於相對於區塊產出的比特幣(目前是12.5個比特幣)的小額交易,我們不太需要擔憂安全性。對於大額交易(比如說100個比特幣),全節點可能有經濟動力來欺騙你。總的來說,大額交易應當使用全節點來驗證。
11.8. 默克爾區塊
我們需要一個全節點來發送存在性證明,包括下面兩個信息。首先是輕節點要獲取默克爾樹的數據結構,另一個是輕節點需要知道每個雜湊在默克爾樹的位置。當輕節點獲取這個兩個信息後就可以重構部分的默克爾樹,進一步計算出默克爾根並驗證存在性證明。一個全節點使用默克爾區塊(merkle block)與輕節點通訊這兩個消息。
要理解默克爾區塊,我們首先要理解一點有關默克爾樹,或者更常見的二叉樹的遍歷方法。在二叉樹中,節點可以使用深度優先和寬度優先兩種遍歷策略。寬度優先的策略遍歷順序如下圖[figure-11-3]。
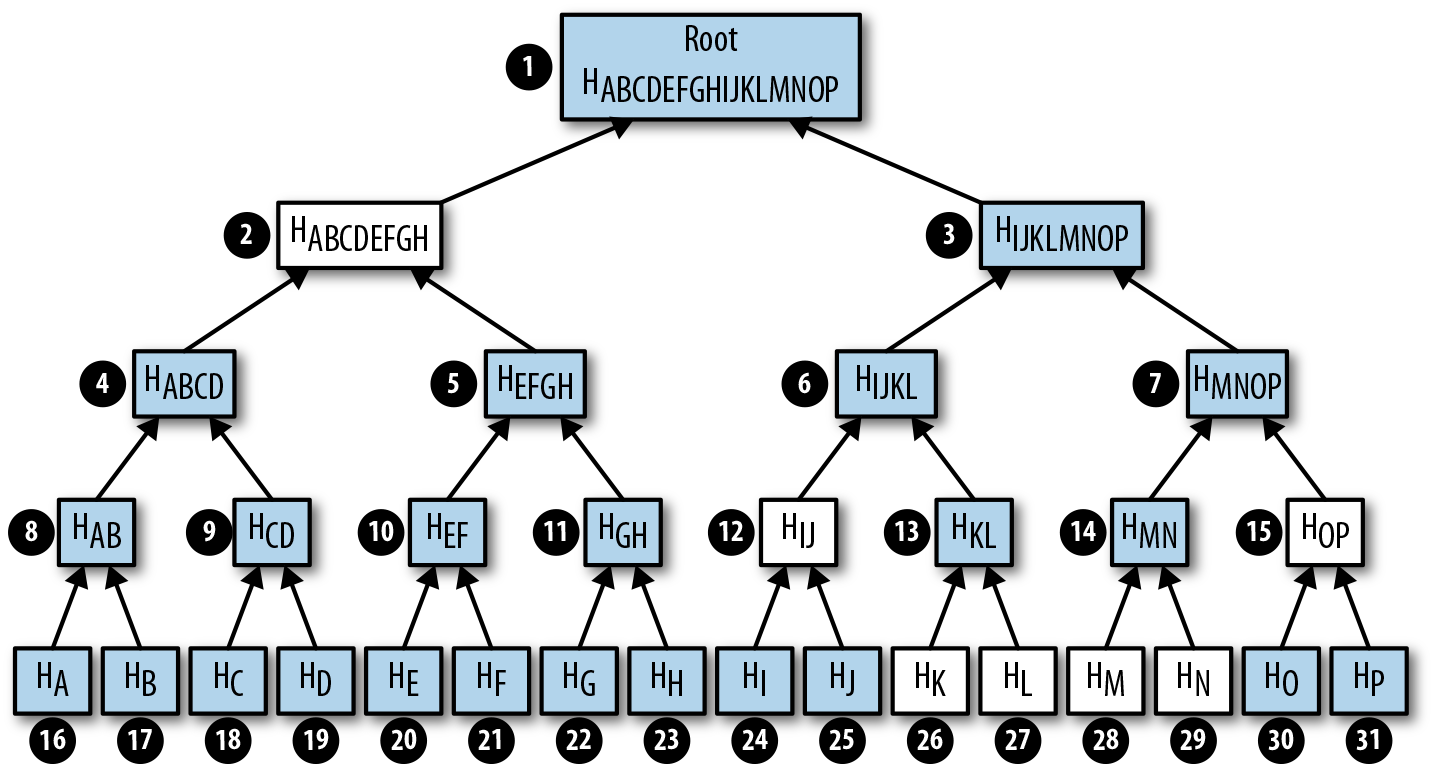
Figure 11-3. 寬度優先遍歷
寬度優先遍歷從根節點開始,從左到右先遍歷完根節點,再遍歷葉節點。
深度優先遍歷與此不同,如圖[figure-11-4]。
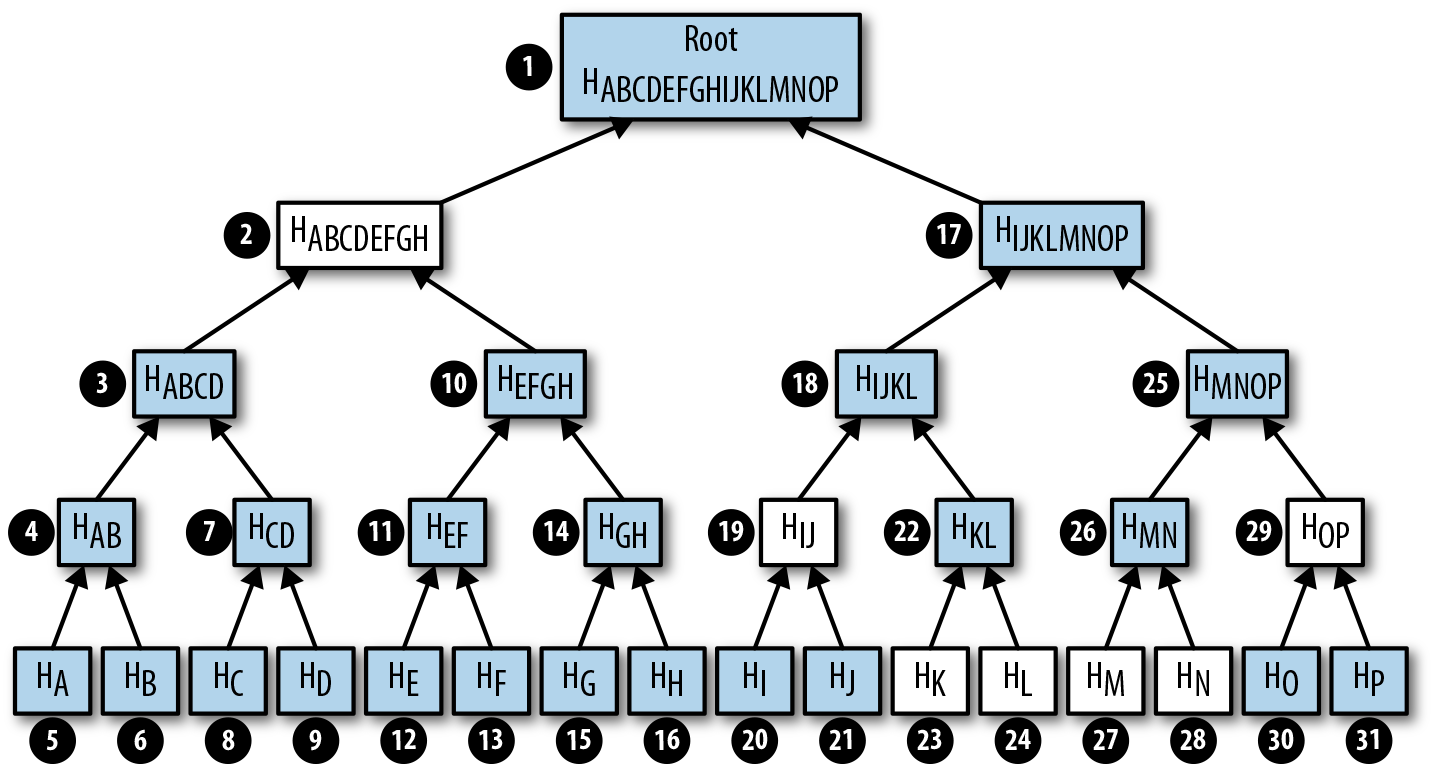
Figure 11-4. 深度優先遍歷
深度優先遍歷將從根節點開始,遍歷完左葉節點再遍歷右葉節點。
要發送一個存在性證明([figure-11-5]),全節點會發送綠色的方框的 HK 和 HN ,並隨之發送藍色方框的 HABCDEFGH,HIJ,HL,HM 和 HOP 。其在默克爾樹中的位置使用深度優先遍歷。樹的重建過程,即計算虛線框內容,將在下面的部分討論。
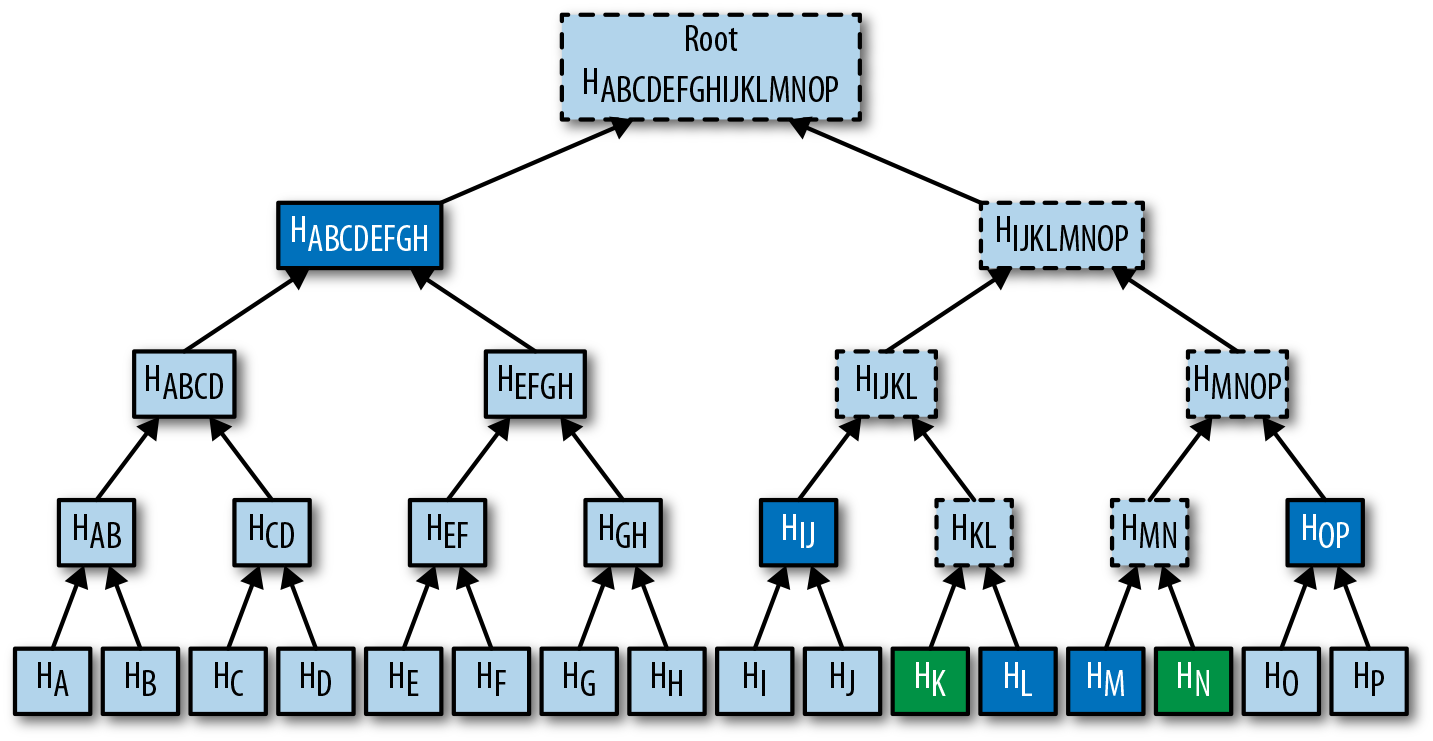
Figure 11-5. 默克爾證明
11.8.1. 默克爾樹結構
輕節點首先構造默克爾樹的通用數據結構。因為默克爾樹是從底層葉節點開始構造,所以輕節點只要知道葉節點的數量就能得知默克爾樹的結構。[figure-11-5]的樹有16個葉節點,輕節點可以如下構造空的默克爾樹:
>>> import math
>>> total = 16
>>> max_depth = math.ceil(math.log(total, 2))#1
>>> merkle_tree = []#2
>>> for depth in range(max_depth + 1):#3
... num_items = math.ceil(total / 2**(max_depth - depth))#4
... level_hashes = [None] * num_items#5
... merkle_tree.append(level_hashes)#6
>>> for level in merkle_tree:
... print(level)
[None]
[None, None]
[None, None, None, None]
[None, None, None, None, None, None, None, None]
[None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None]-
由於每層節點數量都會相比子節點減半,所以我們使用 log2 來計算默克爾樹需要多少層。注意我們使用math.ceil 來向上取整。也可以使用更有技巧的 len(bin(total)) -2 。
-
默克爾根的的index為0,之後的子層為1。也就是以到頂端的層數作為索引。
-
默克爾樹中有從0到max_depth的層數。
-
對於特定的一層,其節點數量是將全部子節點數量,從底層到該層,每層除以2 。
-
由於目前我們還不知道填入的雜湊值,我們填入None。
-
注意 merkle_tree 是一個列表的列表,即二維列表。
11.8.3. 實現默克爾樹
至此,我們可以著手構造MerkleTree 類了:
class MerkleTree:
def __init__(self, total):
self.total = total
self.max_depth = math.ceil(math.log(self.total, 2)) self.nodes = []
for depth in range(self.max_depth + 1):
num_items = math.ceil(self.total / 2**(self.max_depth - depth))
level_hashes = [None] * num_items
self.nodes.append(level_hashes)
self.current_depth = 0#1
self.current_index = 0
def __repr__(self):#2
result = []
for depth, level in enumerate(self.nodes):
items = []
for index, h in enumerate(level):
if h is None:
short = 'None'
else:
short = '{}...'.format(h.hex()[:8])
if depth == self.current_depth and index == self.current_index:
items.append('*{}*'.format(short[:-2]))
else:
items.append('{}'.format(short))
result.append(', '.join(items))
return '\n'.join(result)-
我們維護一個指向樹中特定節點的指針
-
打印輸出時使用該函數
我們已經有一個空的樹了,我們接下來向其填入雜湊值,並計算默克爾根。如果我們有全部的葉節點,其計算過程如下:
>>> from merkleblock import MerkleTree
>>> from helper import merkle_parent_level
>>> hex_hashes = [
... "9745f7173ef14ee4155722d1cbf13304339fd00d900b759c6f9d58579b5765fb",
... "5573c8ede34936c29cdfdfe743f7f5fdfbd4f54ba0705259e62f39917065cb9b",
... "82a02ecbb6623b4274dfcab82b336dc017a27136e08521091e443e62582e8f05",
... "507ccae5ed9b340363a0e6d765af148be9cb1c8766ccc922f83e4ae681658308",
... "a7a4aec28e7162e1e9ef33dfa30f0bc0526e6cf4b11a576f6c5de58593898330",
... "bb6267664bd833fd9fc82582853ab144fece26b7a8a5bf328f8a059445b59add",
... "ea6d7ac1ee77fbacee58fc717b990c4fcccf1b19af43103c090f601677fd8836",
... "457743861de496c429912558a106b810b0507975a49773228aa788df40730d41",
... "7688029288efc9e9a0011c960a6ed9e5466581abf3e3a6c26ee317461add619a",
... "b1ae7f15836cb2286cdd4e2c37bf9bb7da0a2846d06867a429f654b2e7f383c9",
... "9b74f89fa3f93e71ff2c241f32945d877281a6a50a6bf94adac002980aafe5ab",
... "b3a92b5b255019bdaf754875633c2de9fec2ab03e6b8ce669d07cb5b18804638",
... "b5c0b915312b9bdaedd2b86aa2d0f8feffc73a2d37668fd9010179261e25e263",
... "c9d52c5cb1e557b92c84c52e7c4bfbce859408bedffc8a5560fd6e35e10b8800",
... "c555bc5fc3bc096df0a0c9532f07640bfb76bfe4fc1ace214b8b228a1297a4c2",
... "f9dbfafc3af3400954975da24eb325e326960a25b87fffe23eef3e7ed2fb610e",
... ]
>>> tree = MerkleTree(len(hex_hashes))
>>> tree.nodes[4] = [bytes.fromhex(h) for h in hex_hashes]
>>> tree.nodes[3] = merkle_parent_level(tree.nodes[4])
>>> tree.nodes[2] = merkle_parent_level(tree.nodes[3])
>>> tree.nodes[1] = merkle_parent_level(tree.nodes[2])
>>> tree.nodes[0] = merkle_parent_level(tree.nodes[1])
>>> print(tree)
*597c4baf.*
6382df3f..., 87cf8fa3...
3ba6c080..., 8e894862..., 7ab01bb6..., 3df760ac...
272945ec..., 9a38d037..., 4a64abd9..., ec7c95e1..., 3b67006c..., 850683df..., d40d268b..., 8636b7a3...
9745f717..., 5573c8ed..., 82a02ecb..., 507ccae5..., a7a4aec2..., bb626766..., ea6d7ac1..., 45774386..., 76880292..., b1ae7f15..., 9b74f89f..., b3a92b5b..., b5c0b915..., c9d52c5c..., c555bc5f..., f9dbfafc...上面的代碼將數據填充到樹中,並計算出了默克爾根。然而在比特幣的網路上一般不會給出全部的葉節點。消息可能包含一些中間節點。需要一個更好的方法來填充樹。
我們將使用樹的遍歷方法。首先進行一個深度優先遍歷,並只填入我們能計算的節點。在遍歷中,我們需要記錄我們目前在樹的什麼地方,所以我們在類中設計了self.current_depth 和 self。current_index 屬性。
我們還需要一些方法來遍歷默克爾樹。我們需要引入如下的一些工具函數:
class MerkleTree:
...
def up(self):
self.current_depth -= 1
self.current_index //= 2
def left(self):
self.current_depth += 1
self.current_index *= 2
def right(self):
self.current_depth += 1
self.current_index = self.current_index * 2 + 1
def root(self):
return self.nodes[0][0]
def set_current_node(self, value):#1
self.nodes[self.current_depth][self.current_index] = value
def get_current_node(self):
return self.nodes[self.current_depth][self.current_index]
def get_left_node(self):
return self.nodes[self.current_depth + 1][self.current_index * 2]
def get_right_node(self):
return self.nodes[self.current_depth + 1][self.current_index * 2 + 1]
def is_leaf(self):#2
return self.current_depth == self.max_depth
def right_exists(self):#3
return len(self.nodes[self.current_depth + 1]) > \
self.current_index * 2 + 1-
要有對節點寫入值的能力
-
判斷目前是否在葉節點上
-
在特定情況下,比如當我們在某層的最右的節點且子節點只有奇數個時,我們可能沒有右子節點
我們實現了默克爾樹的遍歷方法, left,right和 up。讓我們使用這些方法來通過深度優先遍歷策略來填入數據:
>>> from merkleblock import MerkleTree
>>> from helper import merkle_parent
>>> hex_hashes = [
... "9745f7173ef14ee4155722d1cbf13304339fd00d900b759c6f9d58579b5765fb",
... "5573c8ede34936c29cdfdfe743f7f5fdfbd4f54ba0705259e62f39917065cb9b",
... "82a02ecbb6623b4274dfcab82b336dc017a27136e08521091e443e62582e8f05",
... "507ccae5ed9b340363a0e6d765af148be9cb1c8766ccc922f83e4ae681658308",
... "a7a4aec28e7162e1e9ef33dfa30f0bc0526e6cf4b11a576f6c5de58593898330",
... "bb6267664bd833fd9fc82582853ab144fece26b7a8a5bf328f8a059445b59add",
... "ea6d7ac1ee77fbacee58fc717b990c4fcccf1b19af43103c090f601677fd8836",
... "457743861de496c429912558a106b810b0507975a49773228aa788df40730d41",
... "7688029288efc9e9a0011c960a6ed9e5466581abf3e3a6c26ee317461add619a",
... "b1ae7f15836cb2286cdd4e2c37bf9bb7da0a2846d06867a429f654b2e7f383c9",
... "9b74f89fa3f93e71ff2c241f32945d877281a6a50a6bf94adac002980aafe5ab",
... "b3a92b5b255019bdaf754875633c2de9fec2ab03e6b8ce669d07cb5b18804638",
... "b5c0b915312b9bdaedd2b86aa2d0f8feffc73a2d37668fd9010179261e25e263",
... "c9d52c5cb1e557b92c84c52e7c4bfbce859408bedffc8a5560fd6e35e10b8800",
... "c555bc5fc3bc096df0a0c9532f07640bfb76bfe4fc1ace214b8b228a1297a4c2",
... "f9dbfafc3af3400954975da24eb325e326960a25b87fffe23eef3e7ed2fb610e",
... ]
>>> tree = MerkleTree(len(hex_hashes))
>>> tree.nodes[4] = [bytes.fromhex(h) for h in hex_hashes]
>>> while tree.root() is None:#1
... if tree.is_leaf():#2
... tree.up()
... else:
... left_hash = tree.get_left_node()
... right_hash = tree.get_right_node()
... if left_hash is None:#3
... tree.left()
... elif right_hash is None:#4
... tree.right()
... else:
... tree.set_current_node(merkle_parent(left_hash, right_hash))
... tree.up()
>>> print(tree)
597c4baf...
6382df3f..., 87cf8fa3...
3ba6c080..., 8e894862..., 7ab01bb6..., 3df760ac...
272945ec..., 9a38d037..., 4a64abd9..., ec7c95e1..., 3b67006c..., 850683df..., \
d40d268b..., 8636b7a3...
9745f717..., 5573c8ed..., 82a02ecb..., 507ccae5..., a7a4aec2..., bb626766..., \
ea6d7ac1..., 45774386..., 76880292..., b1ae7f15..., 9b74f89f..., b3a92b5b..., \
b5c0b915..., c9d52c5c..., c555bc5f..., f9dbfafc...#1 我們不斷遍歷,直到計算出默克爾根。每次循環,我們都處在特定的位置的節點
#2 如果我們在葉節點,我們已經有了雜湊值,所以我們不需要做任何事,返回到父節點即可
#3 如果我們沒有左子節點的雜湊,我們則先計算其左子節點的雜湊再計算當前位置的節點雜湊
#4 如果我們右節點的雜湊,我們先計算其右子節點雜湊再自己算當前位置節點的雜湊。注意,由於我們採用的是深度優先遍歷,所以左子節點的雜湊一定已經計算完成
#5 我們已經計算完成左子節點的雜湊和右子節點的雜湊,也就能計算其父節點的雜湊,計算後賦值給當前節點。完成後返回上層父節點
上述代碼只有在節點數量是2的冪的整數時才能使用,一些邊界清空則無法處理,比如任意一層的節點個數是奇數個的時候。
我們如下處理父節點是該層最右節點且該層為奇數的情況:
>>> from merkleblock import MerkleTree
>>> from helper import merkle_parent
>>> hex_hashes = [
... "9745f7173ef14ee4155722d1cbf13304339fd00d900b759c6f9d58579b5765fb",
... "5573c8ede34936c29cdfdfe743f7f5fdfbd4f54ba0705259e62f39917065cb9b",
... "82a02ecbb6623b4274dfcab82b336dc017a27136e08521091e443e62582e8f05",
... "507ccae5ed9b340363a0e6d765af148be9cb1c8766ccc922f83e4ae681658308",
... "a7a4aec28e7162e1e9ef33dfa30f0bc0526e6cf4b11a576f6c5de58593898330",
... "bb6267664bd833fd9fc82582853ab144fece26b7a8a5bf328f8a059445b59add",
... "ea6d7ac1ee77fbacee58fc717b990c4fcccf1b19af43103c090f601677fd8836",
... "457743861de496c429912558a106b810b0507975a49773228aa788df40730d41",
... "7688029288efc9e9a0011c960a6ed9e5466581abf3e3a6c26ee317461add619a",
... "b1ae7f15836cb2286cdd4e2c37bf9bb7da0a2846d06867a429f654b2e7f383c9",
... "9b74f89fa3f93e71ff2c241f32945d877281a6a50a6bf94adac002980aafe5ab",
... "b3a92b5b255019bdaf754875633c2de9fec2ab03e6b8ce669d07cb5b18804638",
... "b5c0b915312b9bdaedd2b86aa2d0f8feffc73a2d37668fd9010179261e25e263",
... "c9d52c5cb1e557b92c84c52e7c4bfbce859408bedffc8a5560fd6e35e10b8800",
... "c555bc5fc3bc096df0a0c9532f07640bfb76bfe4fc1ace214b8b228a1297a4c2",
... "f9dbfafc3af3400954975da24eb325e326960a25b87fffe23eef3e7ed2fb610e",
... "38faf8c811988dff0a7e6080b1771c97bcc0801c64d9068cffb85e6e7aacaf51",
... ]
>>> tree = MerkleTree(len(hex_hashes))
>>> tree.nodes[5] = [bytes.fromhex(h) for h in hex_hashes]
>>> while tree.root() is None:
... if tree.is_leaf():
... tree.up()
... else:
... left_hash = tree.get_left_node()
... if left_hash is None:#1
... tree.left()
... elif tree.right_exists():#2
... right_hash = tree.get_right_node()
... if right_hash is None:#3
... tree.right()
... else:#4
... tree.set_current_node(merkle_parent(left_hash, right_hash))
... tree.up()
... else:#5
... tree.set_current_node(merkle_parent(left_hash, left_hash))
... tree.up()
>>> print(tree)
0a313864...
597c4baf..., 6f8a8190...
6382df3f..., 87cf8fa3..., 5647f416...
3ba6c080..., 8e894862..., 7ab01bb6..., 3df760ac..., 28e93b98...
272945ec..., 9a38d037..., 4a64abd9..., ec7c95e1..., 3b67006c..., 850683df..., \
d40d268b..., 8636b7a3..., ce26d40b...
9745f717..., 5573c8ed..., 82a02ecb..., 507ccae5..., a7a4aec2..., bb626766..., \
ea6d7ac1..., 45774386..., 76880292..., b1ae7f15..., 9b74f89f..., b3a92b5b..., \
b5c0b915..., c9d52c5c..., c555bc5f..., f9dbfafc..., 38faf8c8...-
如果我們沒有左子節點的值,我們將遍歷左子節點,所有的中間節點都能確保其有左節點
-
需要首先判斷是否有右子節點。只有當節點最右節點的子節點層節點數量為奇數時才會為真
-
如果我們沒有右子節點的值,我們遍歷其右子節點
-
如果我們左右子節點的值,我們就可以使用merkle_parent方法來計算當前節點的值了
-
當我們有左子節點的值,但沒有右子節點時,左子節點就是該層最右節點,我們需要將複製並左子節點來計算當前節點
至此,我們已經可以處理葉子節點數量不為2的冪時的情況。
11.8.4. 默克爾區塊指令(merkleblock command)
驗證我們所關心的交易是否在默克爾根中需要全部信息會由全節點通訊默克爾區塊來傳遞。默克爾區塊通訊指令(merkleblock network command)就是用來傳遞此信息的指令。如圖[figure-11-6]。
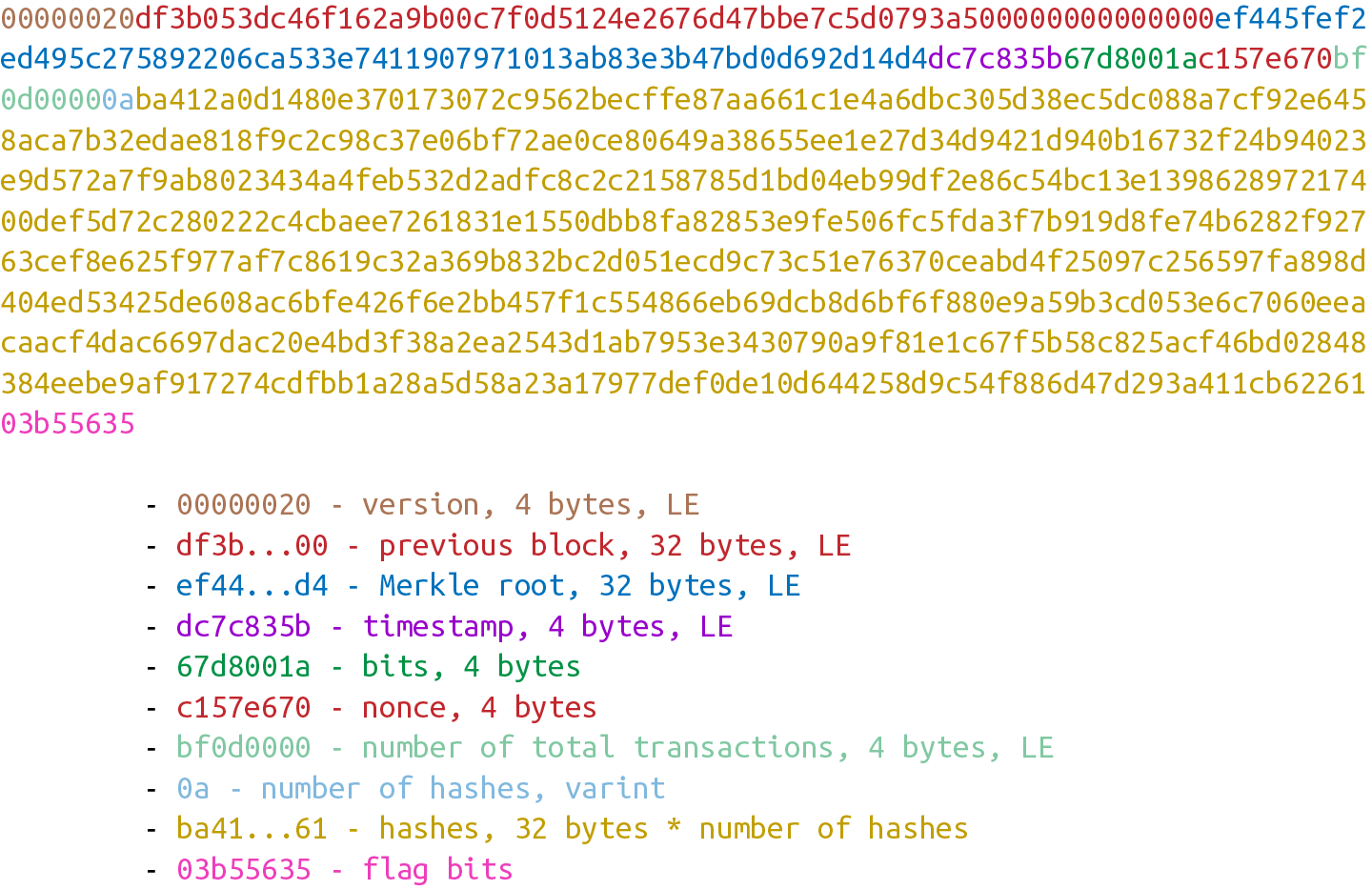
Figure 11-6. 解析默克爾區塊
前六個欄位和第九章中的區塊頭一致。最後四個欄位是存在性證明。
交易數量欄位代表了默克爾樹有多少個葉子節點。輕節點會根據這個數據來構建對應的空默克爾樹。雜湊欄位代表了圖[figure-11-5]中的藍色和綠色框的數據。由於該欄位中的雜湊數量是不固定的,所以前綴雜湊的數量。最後的欄位是標記(flag)欄位,提供了雜湊在默克爾樹中的位置信息。標記欄位的數據使用如下的bytes_to_bits_field函數解析,轉換成一個二進制位(0 和 1)的列表:
def bytes_to_bit_field(some_bytes): flag_bits = []
for byte in some_bytes:
for _ in range(8):
flag_bits.append(byte & 1)
byte >>= 1
return flag_bits字節的排序雖然顯得有些奇怪,但可以方便地轉化成重構默克爾樹所需要的標記位(flag bit)。
11.8.6. 標記位(bit)和雜湊的使用
標記位代表了以深度優先遍歷策略下,對應雜湊的位置。
標記位的規則為:
-
如果節點的值在已經在雜湊欄位中,則其標記位0。
-
如果節點是中間節點,其值需要輕節點計算得出(即[figure-11-7]中虛線框)其標記位為1。
-
如果節點是葉節點並且是我們關心的交易(即[figure-11-7]中綠色框),雖然其雜湊在雜湊欄位中已經存在,仍將其標記位設為1。我們要證明此類的交易存在於默克爾樹中。
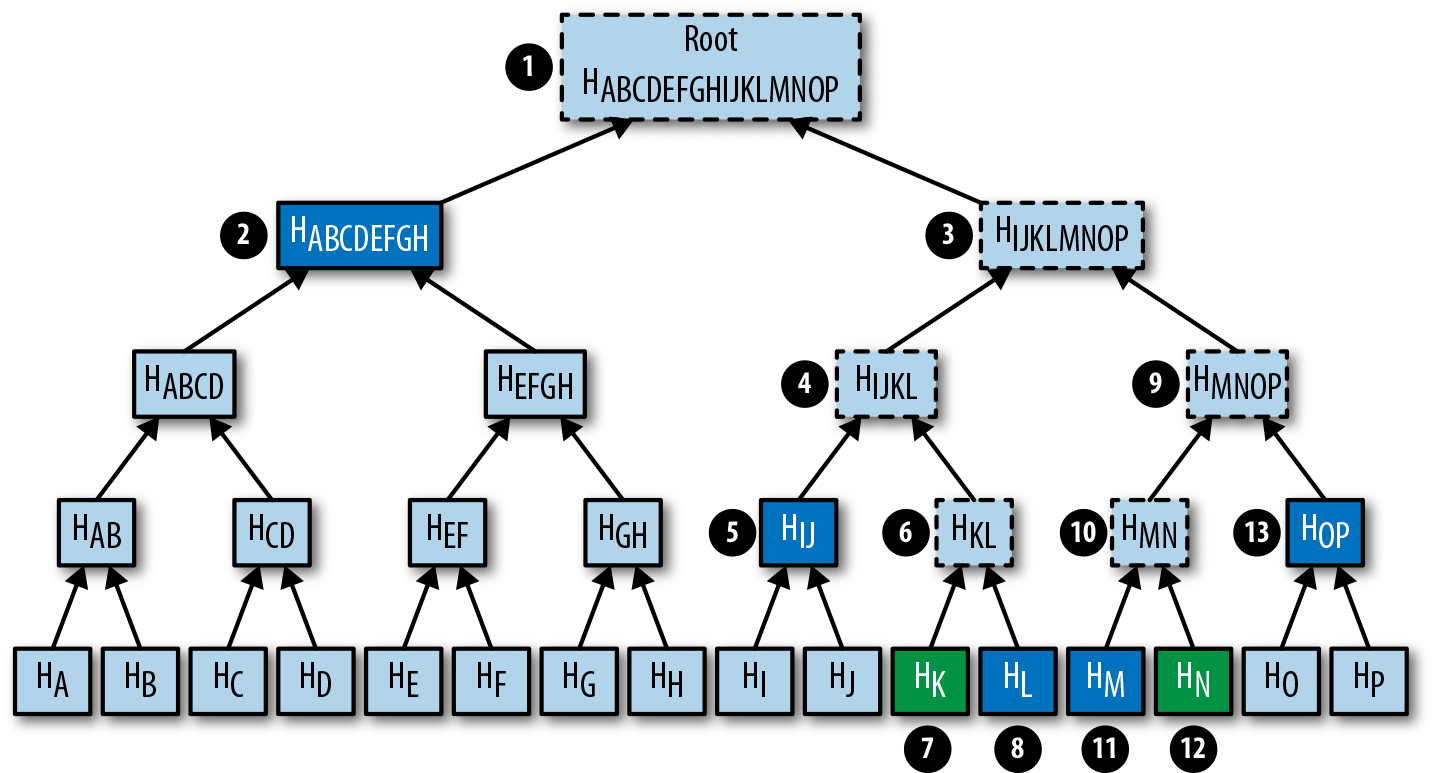
Figure 11-7 處理默克爾區塊
從[figure-11-7]我們可以得知:
-
根節點(1)的值需要由輕節點計算,所以標記位為1。
-
左子節點 HABCDEFGH 的值來自默克爾區塊指令中的雜湊欄位,所以其標記位為0。
-
此時,我們需要遍歷的是 HIJKLMNOP ,而不是 HABCD 和 HEFGH 。因為我們並不需要這兩個節點的值。
-
右子節點 HIJKLMNOP 也是需要通過計算得到,所以其標記位為1。
-
計算 HIJKLMNOP 需要 HIJKL 和 HMNOP (9)。根據深度優先搜索,下一個節點是左子節點 HIJKL (4)。
-
HIJKL 是中間節點,需要計算,所以標記位為1。
-
之後,我們遍歷到左子節點 HIJ (5)。當我們返回到此此節點時,再遍歷右子節點 HKL (6)。
-
HIJ 的值在雜湊欄位中已經提供,所以標記位為0。
-
HKL 是需要計算的中間節點,所以其標記位為1。
-
HK (7)是一個葉子節點,也是存在性證明要證明的節點,所以其位標記位1。
-
HL (8)是在雜湊欄位中提供的雜湊值的節點,所以標記位為0。
-
回到 HKL ,由於此時已知 HK 和 HL ,我們可以計算它的值了。
-
回到 HIJKL ,由於此時已知 HIJ 和 HKL ,我們可以計算他的值了。
-
回到 HIJKLMNOP ,由於我們還沒有遍歷右字節點 HMNOP ,無法計算 HIJKLMNOP 。
-
之後遍歷到 HMNOP (9),該節點也是中間節點。所以標記位為1。
-
HMN (10)也是一個需要計算的中間節點,所以標記位為1。
-
HM (11) 的值由雜湊欄位提供,所以標記位為0。
-
HN (12) 是存在性證明要證明的節點。所以標記位為1,其值也由雜湊欄位提供。
-
回到 HMN ,此時已知 HM 和 HN ,我們可以計算 HMN 的值了。
-
回到 HMNOP ,由於還沒有遍歷右子節點 HOP ,所以還不能計算。
-
HOP (13) 的值由雜湊欄位提供,所以標記位1,這也是雜湊欄位中最後一個雜湊值。
-
回到 HMNOP ,此時我們可以計算 HMN 的值了。
-
回到 HHIJKLMNOP ,其雜湊值也可以進行計算了。
-
最後,回到默克爾根 HABCDEFGHIJKLMNOP 並計算它。
那麼從1 到13號節點的標記位為:
1,0,1,1,0,1,1,0,1,1,0,1,0
對應的雜湊欄位中的雜湊有七個,依次為:
-
HABCDEFGH
-
HIJ
-
HK
-
HL
-
HM
-
HN
-
HOP
注意字母下標,從A到P都依次出現了。這意味著這些信息足以證明 HK 和 HN ([figure-11-7]中的綠色框)存在於區塊中。
如圖[figure-11-7],標記位使用深度優先遍歷的順序。任何時候給出一個雜湊,比如 HABCDEFGH 我們將跳過其子節點,並繼續遍歷 HIJKLMNOP 而不是 HABCD 。標記位是一個非常優秀的工具,他能將我們掌握哪些雜湊的信息進行編碼。
至此,當給定雜湊欄位和標記位時,我們就可以重構默克爾樹和計算默克爾根了:
class MerkleTree: ...
def populate_tree(self, flag_bits, hashes):
while self.root() is None:#1
if self.is_leaf():#2
flag_bits.pop(0)#3
self.set_current_node(hashes.pop(0))#4
self.up()
else:
left_hash = self.get_left_node()
if left_hash is None:#5
if flag_bits.pop(0) == 0: #6
self.set_current_node(hashes.pop(0))
self.up()
else:
self.left()#7
elif self.right_exists():#8
right_hash = self.get_right_node()
if right_hash is None:#9
self.right()
else:#10
self.set_current_node(merkle_parent(left_hash,
right_hash))
self.up()
else:#11
self.set_current_node(merkle_parent(left_hash, left_hash))
self.up()
if len(hashes) != 0:#12
raise RuntimeError('hashes not all consumed {}'.format(len(hashes)))
for flag_bit in flag_bits:#13
if flag_bit != 0:
raise RuntimeError('flag bits not all consumed')#1 構建默克爾樹的目的是為了計算默克爾根,每次循環將遍歷到一個節點,直到計算出默克爾根。
#2 如果循環到葉子節點,我們總是能給出其雜湊值。
#3 python 使用 flag_bits.pop(0) 的方法來出列並指向下一個標記位。我們可能會利用比特位來跟蹤定位我們需要驗證的節點,但目前還不需要。
#4 使用hashes.pop(0)來獲取雜湊欄位中的下一個雜湊,我們需要將其雜湊值設為當前節點的值。
[[209 ]]
#5 如果我們沒有左子節點的值,那麼有兩種可能。節點雜湊值可能在雜湊欄位中,或者通過計算才能獲得。
#6 下一個比特位可以幫我們判斷該節點是否需要計算。如果比特位為0,則該節點的雜湊值則為雜湊欄位下一個雜湊值。如果比特位為1,我們需要計算左子節點的值(可能也需要計算右子節點)。
#7 我們可以確信必然有左子節點,所以我們遍歷到左子節點,並計算該節點的雜湊值。
#8 判斷是否有右子節點。
#9 我們有左子節點的值,但沒有右子節點的值,這需要我們遍歷到右子節點。
#10 我們有左右兩個子節點的值後,我們可以計算兩個子節點的父節點的雜湊值,並賦值到當前節點。
#11 我們有左子節點的值,但是不存在右子節點,這種情況下,根據默克爾樹的規則,我們需要使用兩個左子節點的值來計算父節點的雜湊值。
#12 所有的雜湊值和比特位應當都被恰好消耗,否則意味著我們的數據有問題。
12. 第十二章 布隆過濾器
在第11章中,我們學習了如何驗證默克爾區塊。一個全節點會通過默克爾區塊指令(merkleblock command)為相關的交易提供存在性證明。但是全節點如何知道哪一些區塊是輕節點需要的呢?
輕節點可以選擇告訴全節點它的地址(或者公鑰腳本)。全節點可以檢索跟該地址相關的交易,但是這需要輕節點在隱私上做一點妥協。輕節點並不會向全節點透露它持有1000個比特幣。隱私的洩露就是安全上的洩露,在比特幣的系統中我們認為任何時候都不應該洩露隱私。
在這個場景下,一個解決辦法就是輕節點告訴全節點足夠的信息來創建相關交易的超集。為了創建這樣的超集,我們需要用到的工具是布隆過濾器。
12.1. 什麼是布隆過濾器
布隆過濾器是用來過濾出所有相關交易的工具。全節點通過使用布隆過濾器來過濾交易然後發送相關交易的默克爾區塊指令。
假設我們一共有50筆交易並且其中有1筆交易是輕節點關心的交易。輕節點希望將它關心的那一筆交易藏在一組由5筆交易構成的交易組中,而這需要一個將50筆交易分入10個組,然後全節點就可以按照輕節點要求的發送某一組交易給輕節點。在這裡的分組一定是確定性的,也就是說每次分組都會是這樣分。那我們需要怎樣做才能達到這個效果呢?
我們的解決方法是使用雜湊函數來計算出一個確定的值,然後用模運算將交易分組到不同的組別中去。
布隆過濾器是一種被應用於集合中任意數據的數據結構;假設有一個打算創建布隆過濾器來過濾的元素,「hello world」。我們需要一個雜湊函數,因此我們會用我們程序中已有的那一個:hash256。計算出我們的這個元素應該放在哪個組的過程如下:
>>> from helper import hash256
>>> bit_field_size = 10 #1
>>> bit_field = [0] * bit_field_size
>>> h = hash256(b'hello world') #2
>>> bit = int.from_bytes(h, 'big') % bit_field_size #3
>>> bit_field[bit] = 1 #4
>>> print(bit_field) [0,0,0,0,0,0,0,0,0,1]-
我們的bit_field指的就是關於「組」的列表,在這裡我們假設有10個組
-
我們使用hash256做雜湊計算
-
我們用大端序整型來表示並且對10取模來決定該元素應該放在哪一個組中
-
我們標示出布隆過濾器中我們想要的組別
直觀上而言,我們完成了圖12-1所表示的步驟
Figure 12-1. 10 bit布隆過濾器以及其中的一個元素
我們的布隆過濾器由以下部分構成:
-
bit field的大小
-
使用的雜湊函數(就是說我們如何將其轉化為一個數字)
-
bit field本身,也就是我們關心的那個分組
這樣的運算對單一元素而言十分有效,因此它也對我們關心的某一地址/公鑰腳本/交易ID也同樣有效。當我們對多個要素感興趣時應該怎麼做呢?
我們仍然可以對第二個元素使用同樣的布隆過濾器並且把bit field設置為1。此時全節點並不會僅發送一組相關信息,取而代之的是多組相關信息。假設我們要創建一個布隆過濾器過濾出兩個元素,「hello world」和「goodbye」,我們會用下面的代碼:
>>> from helper import hash256
>>> bit_field_size = 10
>>> bit_field = [0] * bit_field_size
>>> for item in (b'hello world', b'goodbye'): #1
... h = hash256(item)
... bit = int.from_bytes(h, 'big') % bit_field_size
... bit_field[bit] = 1
>>> print(bit_field)
[0,0,1,0,0,0,0,0,0,1]-
在這裡我們只創建了一個針對兩個元素的過濾器,事實上我們可以將它拓展至更多
圖12-2展示了直觀上我們的過濾器是什麼樣的
圖12-2. 10 bit布隆過濾器以及其中的兩個元素
如果我們一共有50個元素,那麼當我們只關心其中1個元素時,平均會有10個元素會通過過濾器而不是5個,因為我們會返回2組元素而不是1組。
12.1.2. 布隆過濾器進階
假設我們一共有100萬個元素而我們希望將它們分入5組。我們需要一個1,000,000/5 = 200,000 比特長度的布隆過濾器。每個組里平均會有5個元素於是我們需要5乘以我們所關心的元素的數量,例如有20%的元素是我們需要的。那麼就是200,000比特,也就是25,000字節的數據需要被傳輸,而這樣的數據量有些大,我們是否有可能做的更好?
使用多個雜湊函數的布隆過濾器可以有效地縮短bit field的長度。如果我們對32位的bit field使用5個雜湊函數,那麼我們可以處理32!/(27!5!) ≈ 200,000 種可能的5比特的組合。對於一百萬個元素,平均5個元素一組就會有5比特的組合。於是我們只需要傳輸32比特也就是4字節的數據,而不是25K字節!
以下是相關代碼。為了方便演示,我們仍然使用10比特的bit field但是我們有2個相關的元素:
>>> from helper import hash256, hash160
>>> bit_field_size = 10
>>> bit_field = [0] * bit_field_size
>>> for item in (b'hello world', b'goodbye'):
... for hash_function in (hash256, hash160): #1
... h = hash_function(item)
... bit = int.from_bytes(h, 'big') % bit_field_size
... bit_field[bit] = 1
>>> print(bit_field)
[1,1,1,0,0,0,0,0,0,1]-
我們使用兩個不同的雜湊函數(hash256和hash160),我們也可以很輕易的使用更多雜湊函數
直觀上而言,圖12-3展示了上面的代碼都做了哪些事情
Figure 12-3. 10bit 布隆過濾器以及其中的兩個元素和兩個雜湊函數
我們可以通過改變雜湊函數的數量以及bit field的大小來控制布隆過濾器假陽性率(false-positive rate,即布隆過濾器判定存在,但實際上不存在的概率)。
12.2. BIP0037 布隆過濾器
BIP0037介紹了網路通訊中的布隆過濾器。布隆過濾器中包含的信息有:
-
bit field的大小,或者說我們需要將信息分成幾組。這個值由字節來表示,在必要的時候會被省略
-
雜湊函數的數量
-
當元素數量太大時,針對布隆過濾器的一些調整
-
由我們所關心的元素而計算出來的bit field
儘管我們可以定義許多雜湊函數(sha512, keccak384, ripemd160,blake256等等),在現實中我們是使用同一個雜湊函數與不同的隨機數種子。這會讓我們的實現更簡單一些。
這這裡我們使用的雜湊函數是murmur3。不同於sha256,murmur3在密碼學上不是安全的,但是它的計算更快。過濾並獲取一個確定性的,平均分布的取模結果並不要求密碼學上的安全性,計算速度反而更重要,因此murmur3對這樣的任務而言是個不錯的工具。隨機數種子的公式有以下定義
i*0xfba4c795 + tweak0xfba4c795是比特幣中布隆過濾器的一個常數。對於第一個雜湊函數i等於0,對於第二個雜湊函數i等於1,對於第三個函數i等於2並以此類推。tweak指的是一些當一次調整的結果不滿意時添加進隨機性的熵。這裡雜湊函數與bit field的大小被用於計算bit field,然後被發送出去:
>>> from helper import murmur3 #1
>>> from bloomfilter import BIP37_CONSTANT #2
>>> field_size = 2
>>> num_functions = 2
>>> tweak = 42
>>> bit_field_size = field_size * 8
>>> bit_field = [0] * bit_field_size
>>> for phrase in (b'hello world', b'goodbye'): #3
... for i in range(num_functions): #4
... seed = i * BIP37_CONSTANT + tweak #5
... h = murmur3(phrase, seed=seed) #6
... bit = h % bit_field_size
... bit_field[bit] = 1
>>> print(bit_field)
[0,0,0,0,0,1,1,0,0,1,1,0,0,0,0,0]-
murmur3在helper.py中用Python語言來實現
-
BIP37_CONSTANT指的是BIP0037中定義的fba4c795的值
-
我們遞歸計算我們所關心的元素
-
我們使用2種雜湊函數
-
這是隨機數種子公式
-
murmur3會返回一個數字,因此我們不需要將其轉化為一個整型
這個2字節的布隆過濾器有4比特的集合來區分16個元素中的1個,因此任何隨機元素通過它的概率是1/4× 1/4 = 1/16。如果一共有160個元素,那麼輕節點平均會收到10個元素,其中有2個會是它關心的。
我們可以開始編寫BloomFilter類:
class BloomFilter:
def __init__(self, size, function_count, tweak): self.size = size
self.bit_field = [0] * (size * 8)
self.function_count = function_count
self.tweak = tweak12.3. 載入一個布隆過濾器
輕節點創建布隆過濾器後,需要讓整個節點知道過濾器的詳細信息,以便整個節點可以發送存在性證明。 輕節點必須做的第一件事是將版本消息(請參閱第10章)中的廣播可選項設置為0。這告訴整個節點不要發送事務消息,除非它們與布隆過濾器匹配或已被特別請求。 在廣播標記之後,輕節點隨後將布隆過濾器本身與整個節點進行通信。 設置布隆過濾器的指令稱為filterload。 信息內容如圖12-4所示。

Figure 12-4. 解析後的filterload
布隆過濾器的元素被編碼為字節。 該消息中的bit欄位,雜湊函數計數和調整值(tweak)都進行了編碼。 最後一個欄位,已匹配元素標記,是一種要求整個節點將任何匹配的事務添加到布隆過濾器的方法。
12.4. 獲取默克爾區塊
輕節點需要另外一個指令:全節點發來的默克爾區塊中相關交易的信息。 getdata指令用於傳達區塊和事務。 輕節點將從完整節點中獲取的特定數據類型稱為濾後區塊。 濾後區塊里裝的是以默克爾區塊的形式通過布隆過濾器的交易。 換句話說,輕節點可以請求含有符合布隆過濾器的相關交易的默克爾區塊。
圖12-5解釋getdata中的信息。

Figure 12-5. 解析後的getdata
我們用number of items作為一個解釋有多少我們關心的元素的變量。每一個元素都有一個類型。類型值為1時表示的是交易(章節5),類型值為2時表示的是正常區塊(章節9),類型值為3時表示的是默克爾區塊(章節11)而類型4表示的是緊密區塊(在本書中並不涉及)。
我們可以在network.py中創建這樣的信息類型:
class GetDataMessage:
command = b'getdata'
def __init__(self):
self.data = [] #1
def add_data(self, data_type, identifier):
self.data.append((data_type, identifier)) #2-
我們存入我們希望的元素
-
我們使用add_data函數將該元素加入到信息中
12.5. 獲取相關交易
載入布隆過濾器的輕節點將會得到所有相關交易的信息來證明相關交易存在於某個特定的區塊中:
>>> from bloomfilter import BloomFilter
>>> from helper import decode_base58
>>> from merkleblock import MerkleBlock
>>> from network import FILTERED_BLOCK_DATA_TYPE, GetHeadersMessage, GetDataMessage, HeadersMessage, SimpleNode
>>> from tx import Tx
>>> last_block_hex = '00000000000538d5c2246336644f9a4956551afb44ba47278759ec55ea912e19'
>>> address = 'mwJn1YPMq7y5F8J3LkC5Hxg9PHyZ5K4cFv'
>>> h160 = decode_base58(address)
>>> node = SimpleNode('testnet.programmingbitcoin.com', testnet=True, logging=False)
>>> bf = BloomFilter(size=30, function_count=5, tweak=90210)#1
>>> bf.add(h160)#2
>>> node.handshake()
>>> node.send(bf.filterload())#3
>>> start_block = bytes.fromhex(last_block_hex)
>>> getheaders = GetHeadersMessage(start_block=start_block)
>>> node.send(getheaders)#4
>>> headers = node.wait_for(HeadersMessage)
>>> getdata = GetDataMessage()#5
>>> for b in headers.blocks:
... if not b.check_pow():
... raise RuntimeError('proof of work is invalid')
... getdata.add_data(FILTERED_BLOCK_DATA_TYPE, b.hash())#6
>>> node.send(getdata)#7
>>> found = False
>>> while not found:
... message = node.wait_for(MerkleBlock, Tx) #8
... if message.command == b'merkleblock':
... if not message.is_valid():#9
... raise RuntimeError('invalid merkle proof')
... else:
... for i, tx_out in enumerate(message.tx_outs):
... if tx_out.script_pubkey.address(testnet=True) == address:#10
... print('found:{}:{}'.format(message.id(),i))
... found = True
... break
found:e3930e1e566ca9b75d53b0eb9acb7607f547e1182d1d22bd4b661cfe18dcddf1:0#1 這裡我們創建了一個30字節的,使用5個雜湊函數以及有90秒調整的布隆過濾器
#2 我們過濾上面這些地址
#3 我們由創建的布隆過濾器發送filterload指令
#4 我們在last_block_hex之後獲得區塊頭
#5 我們為可能含有相關交易的默克爾區塊創建getdata信息
#6 我們請求一個能夠證明相關交易存在性的默克爾區塊。大部分區塊很可能被完全忽視
#7 getdata信息請求在last_block_hex之後的2000個默克爾區塊
#8 我們等待包含存在性證明的merkleblock指令以及包含相關交易的tx指令
#9 我們檢查默克爾區塊中的交易存在性證明
#10 我們根據地址檢索UTXO並且在找到後打印出來
我們所做的就是在2000個區塊中尋找到一個區塊中的一條UTXO對應的一個特定的地址。在沒有區塊瀏覽器的幫助下,在某種程度上它保護了我們的隱私。
13. 第十三章 隔離見證
隔離見證(Segwit)代表 「segregated witness」 ,是向後兼容的升級或「軟分叉」,於2017年8月在比特幣網路上激活。儘管這次激活有很多爭議,其帶來的特性也需要我們解釋。在本章中,我們將探討隔離見證的運作原理,為什麼這是一次向後兼容的升級以及隔離見證帶啓用了什麼功能。
簡要概述,Segwit實現了許多改進:
-
區塊的擴容
-
修復交易延展性
-
為乾淨的升級路徑實現了隔離見證的版本管理
-
修復二次雜湊問題
-
離線錢包手續費計算的安全
如果沒有仔細瞭解隔離驗證的實現細節很難直觀地瞭解隔離見證是什麼。我們將從隔離見證最基礎的交易類型pay-to-witness-pubkey-hash 開始探討。
13.1. 支付到見證公鑰雜湊(p2wpkh)
支付到見證公鑰雜湊(Pay-to-wintness-pubkey-hash, p2wpkh)是在BIP0141和BIP0143中的隔離見證定義的四類新腳本之一。如其名字暗示的那樣,支付到見證公鑰雜湊的交易和支付到公鑰雜湊類似。唯一的變動是將簽名腳本的數據遷移到了見證欄位(witness field)。通過這一設計,我們修復了交易的延展性問題。
13.1.1. 交易的延展性
交易延展性 (Transaction malleability)指在不修改交易的基礎內容的情況下變更交易ID。Mt.Gox 的CEO Mark Karpeles 在解釋2013年其交易所停止提款時將原因歸因於交易的延展性問題。
在構建交易通道(payment channels)時需要重點考慮交易延展性的修改交易ID 的問題,交易通道則是閃電網路的原子單位。可以修改交易ID 的交易在構建支付通道時引入非常多的困難。
交易延展性問題產生的原因是交易ID的計算是對整個交易的計算。對交易數據做hash256計算即為交易ID。在不修改交易簽名(以及交易內容本身)的情況下,大多數欄位是不能修改的,從延展性的角度來看,這些欄位都不是問題。
但每個Input的簽名腳本欄位可以在不修改簽名的情況下修改交易ID。在計算交易簽名雜湊時簽名腳本欄位是空置的(參見第七章)。所以存在修改簽名腳本但改交易簽名仍然有效的可能性。而且如我們在第三章學到的那樣,簽名的構成包含一個隨機數。這意味著兩個在字節數據上不同的簽名本質上可能指的是同一件事情。
這使得簽名腳本容易被延展性攻擊,在不修改交易內容(即整個交易)的情況下,修改交易ID。可延展交易意味著任何相關交易(即使用可延展交易的output之一的交易)都不能保證交易有效的條件下構造交易。由於前序交易雜湊的不確定,所以後序的交易的input欄位不能確證有效。
日常情況下,這也不是一個嚴重的問題,交易一旦進入區塊鏈其交易ID就確定了,也不再有延展性的問題(除非通過工作量證明進行攻擊)。但對支付通道來說,需要使用還沒有進入區塊鏈的funding交易的Output。
(譯注:Mt.Gox 是比特幣早期的交易所之一。該交易所被延展性攻擊。具體來說,攻擊者對交易所發起一個提款請求,在交易所通過節點廣播交易時,通過延展性漏洞修改了交易雜湊,並讓修改後的交易比交易所搶先進入區塊鏈(由於比特幣節點網路的不確定性,是有可能修改後的交易先抵達挖礦節點,當然也可以直接收買礦工)。則交易所簽發的交易不會進入區塊,此時攻擊者則向交易所的客服要求重新完成提款請求。此時攻擊者獲得了而外的收益。發現攻擊後,Mt.Gox 則停止處理提款請求。)
13.1.2. 修復延展性問題
隔離見證修復了延展性問題,將簽名腳本欄位空置後並將簽名欄位的數據放置到另一個不參與交易雜湊計算的欄位。對於p2wpkh 來說,簽名和公鑰屬於簽名腳本,我們將其移入見證欄位,所以不再參與雜湊的計算。這樣,交易ID不會被修改,阻止了延展性交易的攻擊手段。 見證欄位和交易的隔離見證方式的序列化數據只發送需要它的節點。換句話說,尚未升級到隔離見證的舊節點不會收到見證欄位,也不會驗證公鑰和簽名。
這和我們之前遇到的類似。隔離見證使用了類似p2sh的運作方式(第8章)。更新了的節點會做額外的驗證,舊節點則不需要。這就是為什麼隔離見證是一個軟分叉(向前兼容升級)而不是一個硬分叉(向後兼容升級)。
13.2. p2wpkh交易
為了更好的理解隔離見證,我們可以把同一個隔離見證交易發送舊節點(Figure 13-1)和新節點(Figure 13-2)做一個比較。
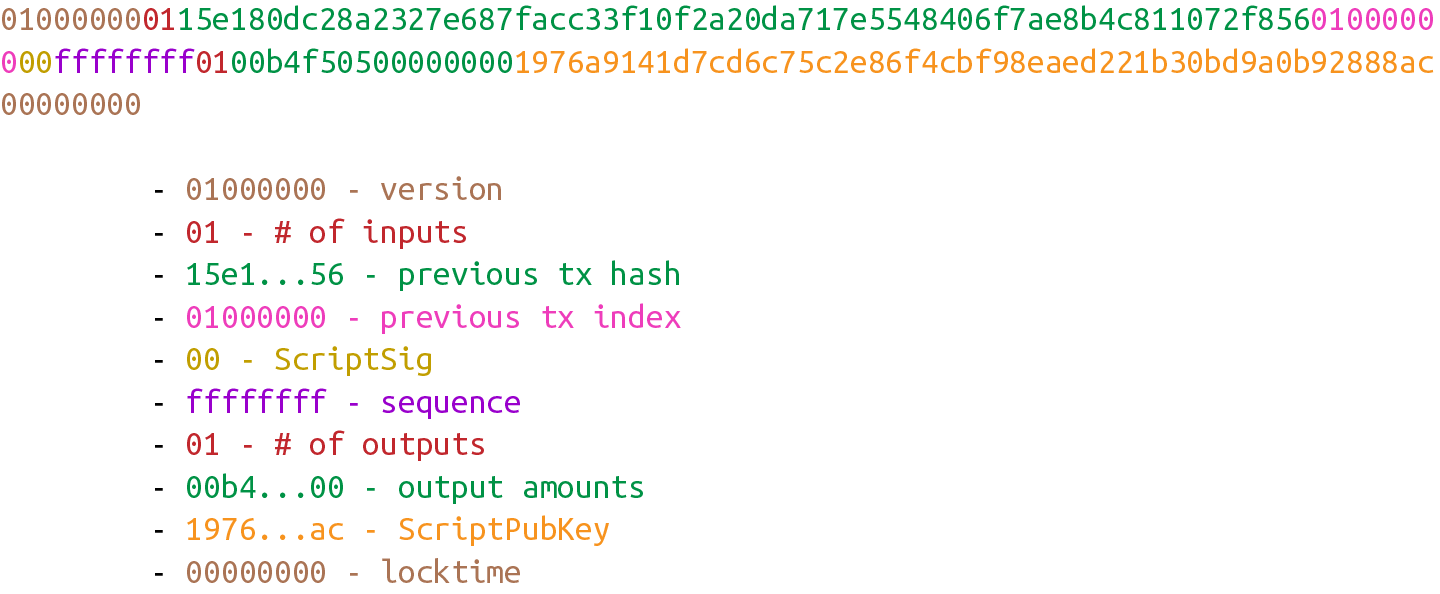
Figure 13-1. 沒有升級BIP0141節點眼中的支付到見證公鑰雜湊交易(p2wpkh)
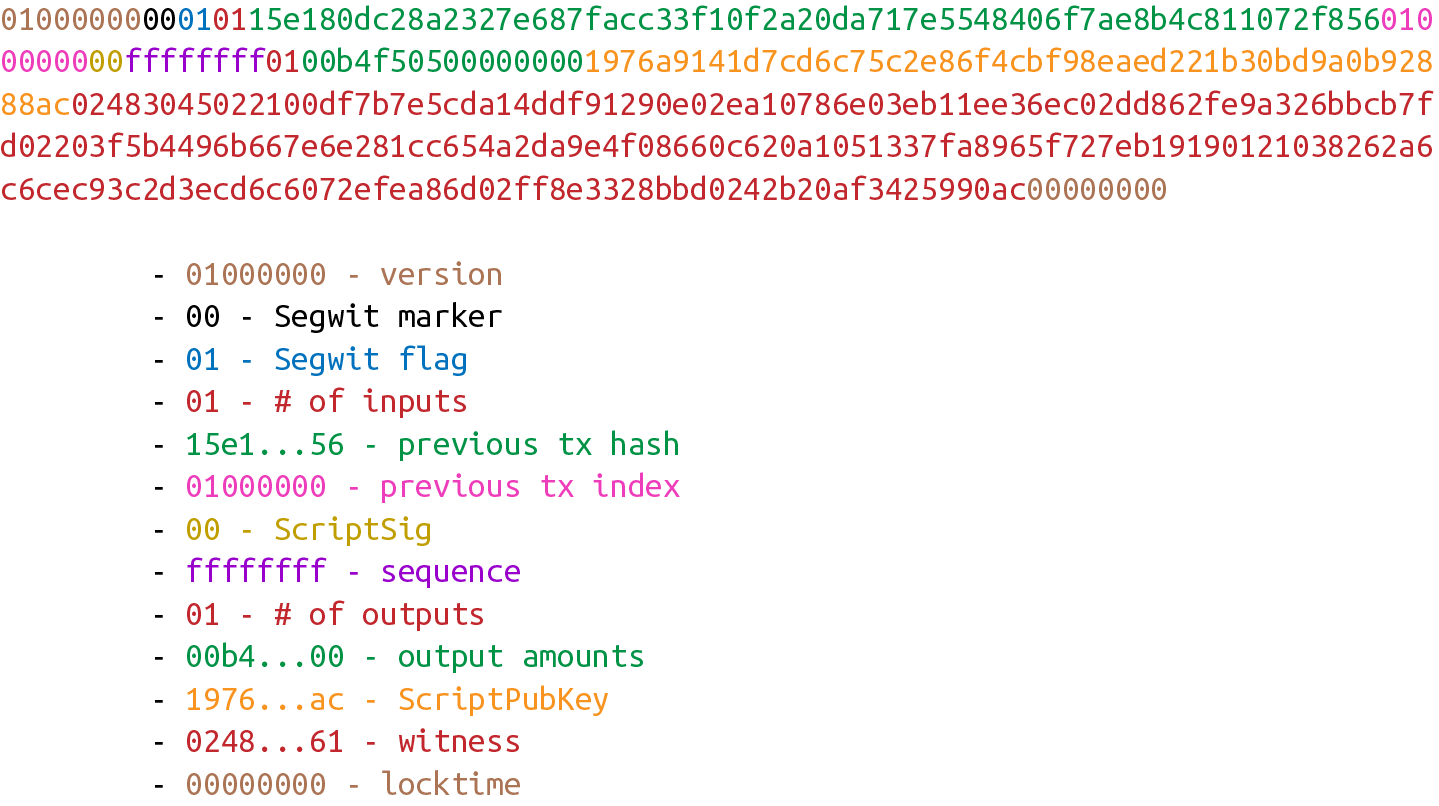
Figure 13-2. 升級了BIP0141節點眼中的支付到見證公鑰雜湊交易(p2wpkh)
兩個序列化數據的不同是後一個交易(隔離見證方式的序列化)有maker,flag 和見證欄位。除此之外是一致的。交易ID沒有延展性問題的原因是我們計算交易ID採用的是第一個序列化方法。
p2wpkh 的見證欄位中包含簽名和公鑰兩個元素。見證欄位只用來升級後的節點的驗證工作。
p2wpkh 交易的公鑰簽名使用了OP_0<20-byte hash> 的操作碼。簽名腳本欄位在兩種序列化方法中都是空置的。將兩個腳本合併後如圖(Figure 13-3)。

Figure 13-3. 支付到見證公鑰雜湊 (p2wpkh) 的公鑰腳本
合併後腳本的初始狀態如圖Figure 13-4。
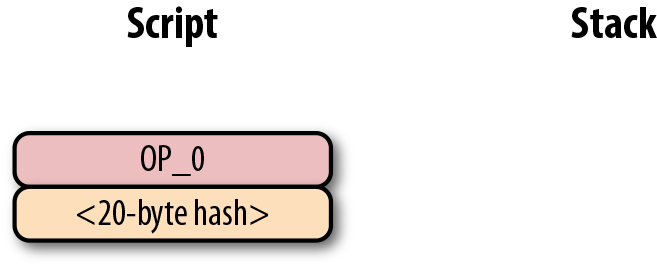
Figure 13-4. p2wpkh開始計算
將OP_0 壓入棧(Figure 13-5)。
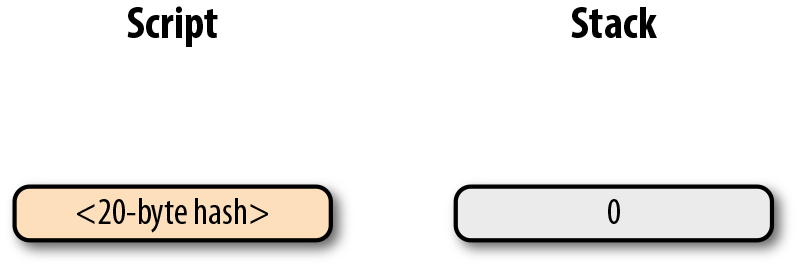
Figure 13-5. p2wpkh 的第一步
20個字節的雜湊屬於元素,所以我們將其壓入棧(Figure 13-6)。
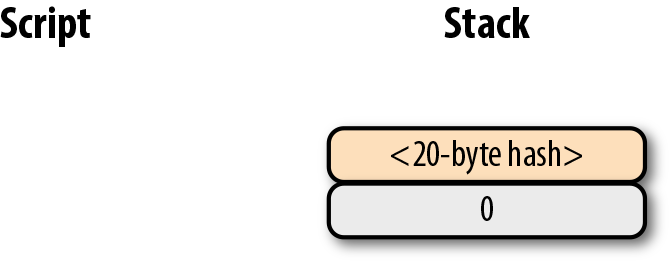
Figure 13-6. p2wpkh 的第二步
此時因為Script的指令集已經沒有指令了,舊節點將會停止計算。由於棧頂不為0,腳本計算結果為有效腳本。這和第八章的p2sh 類似,舊節點不能對其驗證。和p2sh的特殊規則類似(參見第8章),新節點則會有一個特殊的針對隔離見證的規則。回顧p2sh,腳本中如果存在\<RedeemScript\> OP_HASH160 \<OP_EQUAL\>的序列會出發特殊規則。
對於p2wpkh,出發特殊規則的序列為 OP_0<20-byte hash>。當在腳本中存在這個序列時隔離見證欄位的公鑰和簽名以及20個字節的雜湊將加入到指令集,這和p2pkh的指令序列一樣,即\<signature\>\<pubkey\> OP_DUP OP_HASH160 <20-byte hash> OP_EQUALVERIFY OP_CHECKSIG。Figure 13-7展示了接下來的狀態。
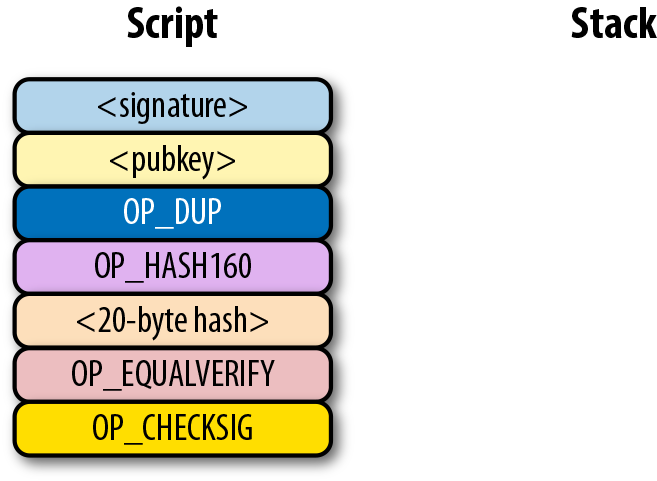
Figure 13-7. p2wpkh 的第三步
後序的處理過程和p2pkh一樣,可以參考第六章。當且僅當20字節的雜湊和公鑰的hash160一致時,最終棧頂為1,即簽名是有效的(Figure 13-8)。

Figure 13-8. p2wpkh 的第四步
對於舊節點,由於其不知道隔離見證的特殊規則,其在處理<20-byte hash> 0 就結束了。和p2sh一樣,只有升級了的新節點才會繼續進行驗證的計算。注意,發送給網路上舊節點的數據更少。此外,節點可以選擇不下載其不想要的已經存在x個欄位的交易(因此不做交易的驗證)。從某種意義上說,簽名已經被一群人所見證,並且節點可以選擇相信它是有效的,而不是選擇自己驗證它。
注意對於版本號為1的隔離見證交易,我們還有額外的特殊規則。版本號為1的隔離見證有完全不同的處理方法。即<20-byte hash> 1會觸發一個完全不同的隔離見證規則。升級版的隔離見證可以使用 Schnorr 簽名,Graftroot 甚至採用不同的腳本體系,比如 Simplicity。隔離見證為我們帶來了乾淨的升級路徑。可以理解如何驗證版本X 的隔離見證的軟體將對該版本的交易做驗證。不能處理版本X 的隔離見證腳本將只會按照其最新的版本的特殊規則處理交易。
13.3. p2sh-p2wpkh
p2wpkh 非常好,但不幸的是,這是一種新的交易類型,舊的錢包則不能發送比特幣到p2wpkh 的公鑰腳本。p2wpkh採用了一個新的地址格式 Bech32,在BIP0173中定義,舊的錢包不能生成p2wpkh 的公鑰腳本。
隔離見證的作者發明一種巧妙的方法,可以通過將p2wpkh(wrapped)「包裝」 到p2sh內,從而使隔離見證向後兼容。因為隔離見證腳本嵌套在p2sh 的贖回腳本中,所以被稱為「嵌套(nested)」的隔離見證。
p2sh-p2wpkh 地址是普通的p2sh地址。但贖回腳本是OP_0<20-byte hash>,即p2wpkh 的公鑰腳本。由於是p2wpkh交易,發送給舊節點(Figure 13-9)和發送給新節點(Figure 13-10)也不同。
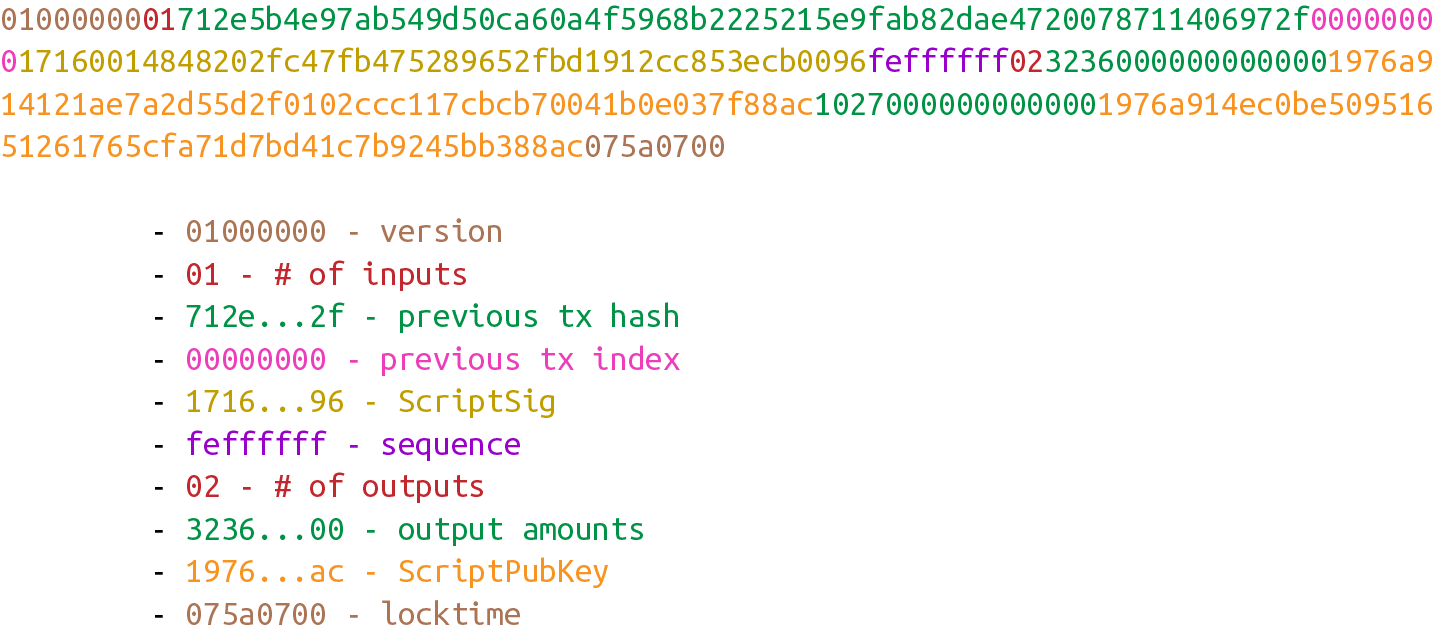
Figure 13-9. 發送給未升級BIP0141的 Pay-to-script-hash-pay-to-witness-pubkey-hash (p2sh-p2wpkh) 交易
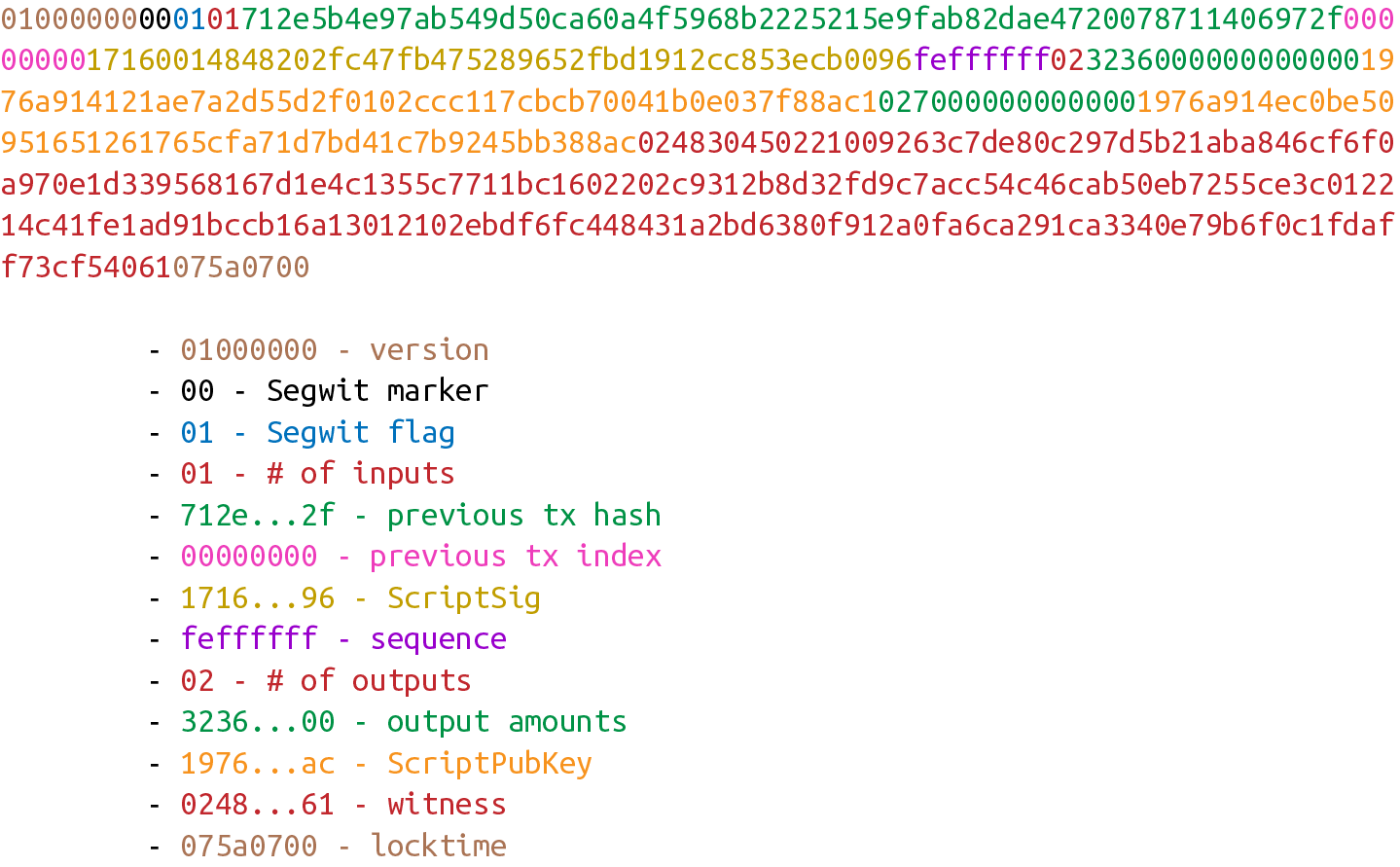
Figure 13-10. 發送給升級了BIP0141 的p2sh-p2wpkh的交易
與p2wpkh的區別在於簽名腳本不為空。 簽名腳本中有一個贖回腳本,它等同於p2wpkh中的公鑰腳本。由於這是一個p2sh腳本,因此公鑰腳本與任何其他p2sh腳本相同。組合後的腳本如圖Figure 13-11所示。

Figure 13-11. p2sh-p2wpkh 的公鑰腳本 和 普通的 p2sh 公鑰腳本一樣
我們將開始計算腳本,如圖Figure 13-12。
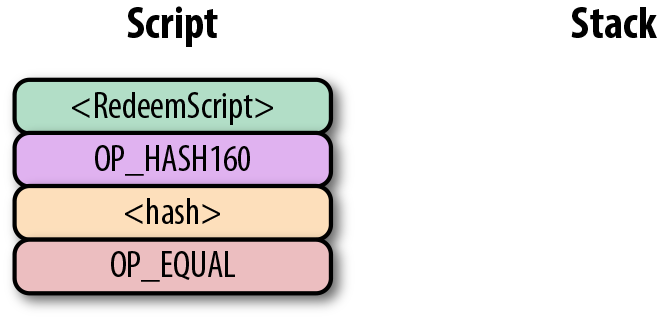
Figure 13-12. 開始計算p2sh-p2wpkh 的腳本
注意,指令集的序列觸發了p2sh 的特殊規則,贖回腳本將被追加到棧中(Figure 13-13)。
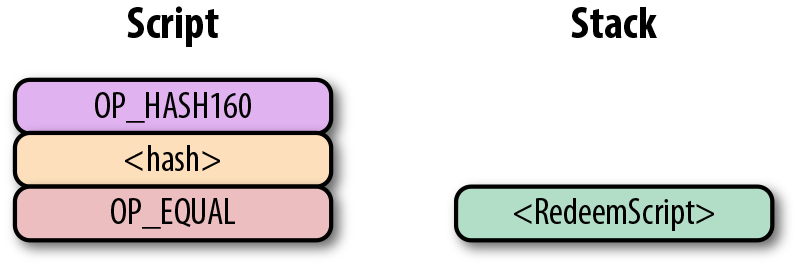
Figure 13-13. p2sh-p2wpkh 第一步
OP_HASH160 會返回贖回腳本的雜湊(Figure 13-14)。
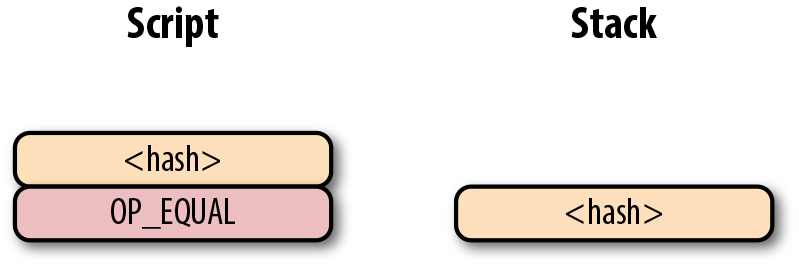
Figure 13-14. p2sh-p2wpkh 第二步
雜湊將加入到棧中, 接下來處理 操作符OP_EQUAL (Figure 13-15) 。
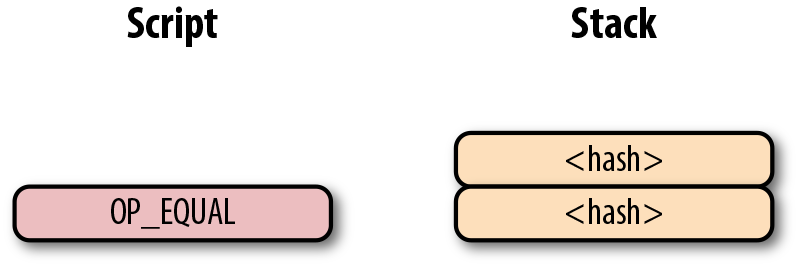
Figure 13-15. p2sh-p2wpkh 第三步
此時, 如果兩個雜湊相等,未升級BIP0016的節點將交易標記未有效,因為節點不瞭解p2sh 的驗證規則。升級了BIP0016的節點將會解析為p2sh特殊的腳本規則。因此對贖回腳本將追加到Script 的指令集進行驗證。贖回腳本是OP_0<20-byte hash>和p2wpkh 的公鑰腳本一致。腳本的狀態將轉換成Figure 13-16。
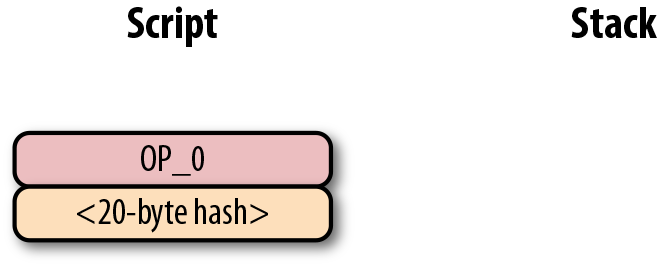
Figure 13-16. p2sh-p2wpkh 第四步
這對我們也不陌生,這是p2wpkh 的初始狀態。在處理過OP_0 和 20-byte hash 後腳本計算轉換成圖Figure 13-17。
Figure 13-17. p2sh-p2wpkh 第五步
此時,由於不知道隔離見證的特殊規則,未升級隔離見證的節點將標記input 是有效的。但升級了隔離見證的節點將以隔離見證的特殊規則處理。見證欄位中的簽名和公鑰以及20字節的雜湊將被追加到p2pkh指令集(Figure 13-18)。
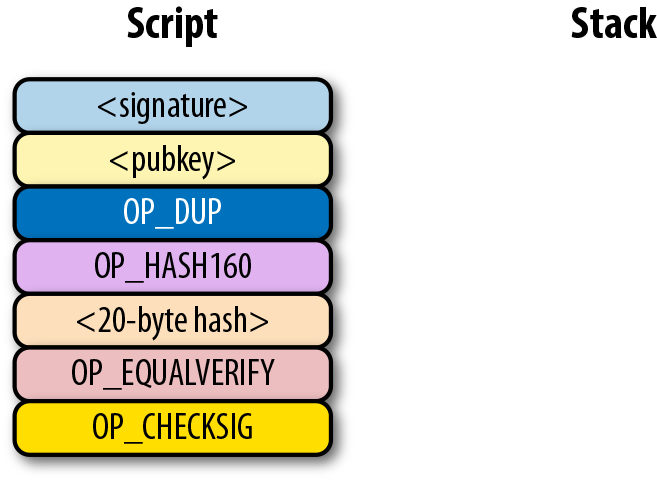
Figure 13-18. p2sh-p2wpkh 第六步
後續的步驟和p2pkh(第六章)一致。假設簽名和公鑰都是有效的,則計算結果如圖Figure 13-19。

Figure 13-19. p2sh-p2wpkh 結束計算
我們可以發現,p2sh-p2wpkh交易對BIP0016之前的節點是向後兼容的,一個未升級BIP0016的節點在贖回腳本相等後就判斷未有效,一個升級了BIP0016但未升級隔離見證的節點則只會驗證20個字節的雜湊。這兩種節點都不能完整的驗證交易,會驗證交易未有效。而升級了隔離見證的節點則會完整地驗證交易,包括對弓腰和簽名的校驗。
|
任何人都可以使用Segwit 的output 嗎?
隔離見證的批評者聲稱隔離見證的交易產生的output 是「任何人可以使用的」。如果比特幣社區拒絕升級隔離見證,那麼該批評是正確的。換句話說,如果一個在比特幣社區有影響力的實體拒絕接受隔離見證並對其進行驗證,則會接受無效的隔離見證交易,進而從比特幣網路中分離出來,此時的該交易的output可以被任何人使用。但由於各種經濟激勵,隔離見證在網路上生效了並且沒有導致分叉產生。許多比特幣現已鎖定在隔離見證的output中,佔絕大多數的升級隔離見證的節點將按軟分叉後的隔離見證的特殊規則對交易驗證。我們現在可以自信地說反對者是錯誤的了。 |
13.4. 實現 p2wpkh 和 p2sh-p2wpkh 交易
我們首先要修改Tx 類,我們需要先標記交易是否是隔離見證:
class Tx:
command = b'tx'
def __init__(self, version, tx_ins, tx_outs, locktime, testnet=False, segwit=False):
self.version = version
self.tx_ins = tx_ins
self.tx_outs = tx_outs
self.locktime = locktime
self.testnet = testnet
self.segwit = segwit
self._hash_prevouts = None
self._hash_sequence = None
self._hash_outputs = None接下來根據我們接收到的序列化數據來修改parse 方法:
class Tx:
...
@classmethod
def parse(cls, s, testnet=False):
s.read(4)#1
if s.read(1) == b'\x00':#2
parse_method = cls.parse_segwit
else:
parse_method = cls.parse_legacy
s.seek(-5, 1)#3
return parse_method(s, testnet=testnet)
@classmethod
def parse_legacy(cls, s, testnet=False):
version = little_endian_to_int(s.read(4))#4
num_inputs = read_varint(s)
inputs = []
for _ in range(num_inputs):
inputs.append(TxIn.parse(s))
num_outputs = read_varint(s)
outputs = []
for _ in range(num_outputs):
outputs.append(TxOut.parse(s))
locktime = little_endian_to_int(s.read(4))
return cls(version, inputs, outputs, locktime,testnet=testnet, segwit=False)#1 判斷交易是否是隔離見證類型,我們需要獲取第五個字節。前四個字節是版本號,第五個是隔離見證的標記。
#2 第五個字節是0時,我們可以判斷這是隔離見證交易(雖然這個方法並不是萬無一失,但我們仍然使用該方法)。我們將根據交易是否是隔離見證交易採用不同的解析方法。
#3 我們將流的讀取位置重置到已經檢查過的五個字節之前。
#4 我們將舊的解析方法放置到parse_legacy方法中。
接下來我們解析隔離見證交易的序列化數據:
class Tx: ...
@classmethod
def parse_segwit(cls, s, testnet=False):
version = little_endian_to_int(s.read(4))
marker = s.read(2)
if marker != b'\x00\x01':#1
raise RuntimeError('Not a segwit transaction {}'.format(marker))
num_inputs = read_varint(s)
inputs = []
for _ in range(num_inputs):
inputs.append(TxIn.parse(s))
num_outputs = read_varint(s)
outputs = []
for _ in range(num_outputs):
outputs.append(TxOut.parse(s))
for tx_in in inputs:#2
num_items = read_varint(s)
items = []
for _ in range(num_items):
item_len = read_varint(s)
if item_len == 0:
items.append(0)
else:
items.append(s.read(item_len))
tx_in.witness = items
locktime = little_endian_to_int(s.read(4))
return cls(version, inputs, outputs, locktime,
testnet=testnet, segwit=True)#1 有兩個欄位,其中之一是隔離見證的標記(marker)。
#2 另一個欄位是見證欄位,包含了每個input 對應的內容。
接下來修改對應的序列化方法:
class Tx:
...
def serialize(self):
if self.segwit:
return self.serialize_segwit()
else:
return self.serialize_legacy()
def serialize_legacy(self):#1
result = int_to_little_endian(self.version, 4)
result += encode_varint(len(self.tx_ins))
for tx_in in self.tx_ins:
result += tx_in.serialize()
result += encode_varint(len(self.tx_outs))
for tx_out in self.tx_outs:
result += tx_out.serialize()
result += int_to_little_endian(self.locktime, 4)
return result
def serialize_segwit(self):
result = int_to_little_endian(self.version, 4)
result += b'\x00\x01'#2
result += encode_varint(len(self.tx_ins))
for tx_in in self.tx_ins:
result += tx_in.serialize()
result += encode_varint(len(self.tx_outs))
for tx_out in self.tx_outs:
result += tx_out.serialize()
for tx_in in self.tx_ins:#3
result += int_to_little_endian(len(tx_in.witness), 1)
for item in tx_in.witness:
if type(item) == int:
result += int_to_little_endian(item, 1)
else:
result += encode_varint(len(item)) + item
result += int_to_little_endian(self.locktime, 4)
return result#1 之前的serialize 方法修改為serialize_legacy。
#2 隔離見證序列化增加了標記(marker)。
#3 最後進行見證欄位的序列化。
我們還需要對應的修改hash 方法,使之採用舊版的序列化數據後進行雜湊計算。這樣對隔離見證交易來說其交易ID 是不可變的:
class Tx:
...
def hash(self):
'''Binary hash of the legacy serialization'''
return hash256(self.serialize_legacy())[::-1]對於隔離見證交易,verify_input需要一個不同的 z。隔離見證的簽名雜湊計算在BIP0143中定義。此外見證欄位將被傳遞到腳本計算引擎中:
class Tx:
...
def verify_input(self, input_index):
tx_in = self.tx_ins[input_index]
script_pubkey = tx_in.script_pubkey(testnet=self.testnet)
if script_pubkey.is_p2sh_script_pubkey():
command = tx_in.script_sig.commands[-1]
raw_redeem = int_to_little_endian(len(command), 1) + command
redeem_script = Script.parse(BytesIO(raw_redeem))
if redeem_script.is_p2wpkh_script_pubkey():#1
z = self.sig_hash_bip143(input_index, redeem_script)#2
witness = tx_in.witness
else:
z = self.sig_hash(input_index, redeem_script)
witness = None
else:
if script_pubkey.is_p2wpkh_script_pubkey():#3
z = self.sig_hash_bip143(input_index) #2
witness = tx_in.witness
else:
z = self.sig_hash(input_index)
witness = None
combined_script = tx_in.script_sig + tx_in.script_pubkey(self.testnet)
return combined_script.evaluate(z, witness)#4
#1 處理p2sh-pw2pkh
#2 BIP0143 的簽名雜湊聲稱代碼在本章代碼中的tx.py 內。
#3 處理p2wpkh
#4 見證欄位將被傳遞到Script計算引擎中,這樣我們可以構建正確的p2wpkh的指令集。
我們還需要在script.py中定義p2wpkh 腳本:
def p2wpkh_script(h160):
'''Takes a hash160 and returns the p2wpkh ScriptPubKey'''
return Script([0x00, h160])#1
...
def is_p2wpkh_script_pubkey(self):#2
return len(self.cmds) == 2 and self.cmds[0] == 0x00 \
and type(self.cmds[1]) == bytes and len(self.cmds[1]) == 20#1 即 OP_0 <20-byte-hash>。 #2 用來判斷當前腳本是否是 p2wpkh 的公鑰腳本。
最後,我們需要在evaluate方法中實現隔離見證的特殊規則。
class Script:
...
def evaluate(self, z, witness):
...
while len(commands) > 0:
...
else:
stack.append(command)
...
if len(stack) == 2 and stack[0] == b'' and len(stack[1]) == 20:#1
h160 = stack.pop()
stack.pop()
cmds.extend(witness)
cmds.extend(p2pkh_script(h160).cmds)#1 我們從這裡開始執行版本0的p2wpkh隔離見證代碼。我們將p2pkh的腳本 和20個字節的雜湊,簽名,公鑰合併後進行計算。
13.5. 支付到見證腳本雜湊
雖然p2wpkh 已經能處理大部分場景,當我們想要使用一些複雜的腳本(比如多重簽名腳本)時,需要更加靈活的工具。我們需要引入的是支付到見證腳本雜湊(pay-to-witness-hash,p2wsh)。p2wsh和p2sh類似,不同的是簽名腳本的數據遷移到了見證欄位。
p2wkh 發送給未升級BIP0141(Figure 13-20) 和升級後的腳本(Figure 13-21)的數據是不同的。
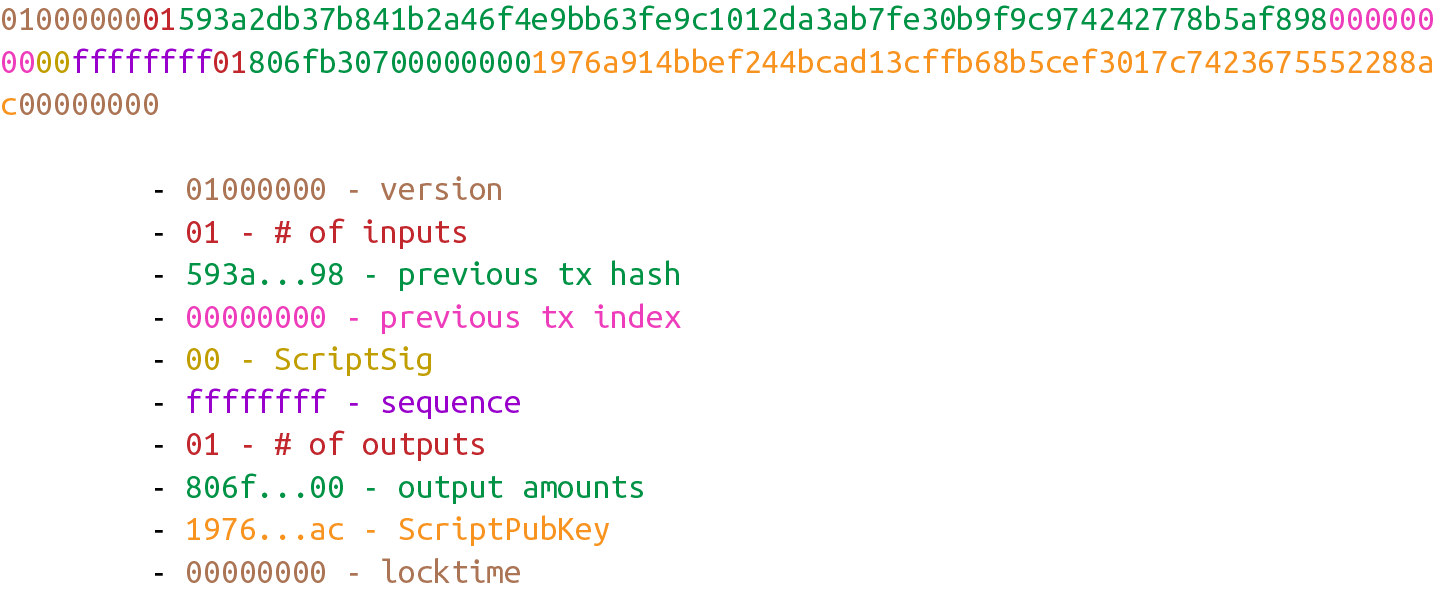
Figure 13-20. 未升級BIP0141 節點眼中的Pay-to-witness-script-hash
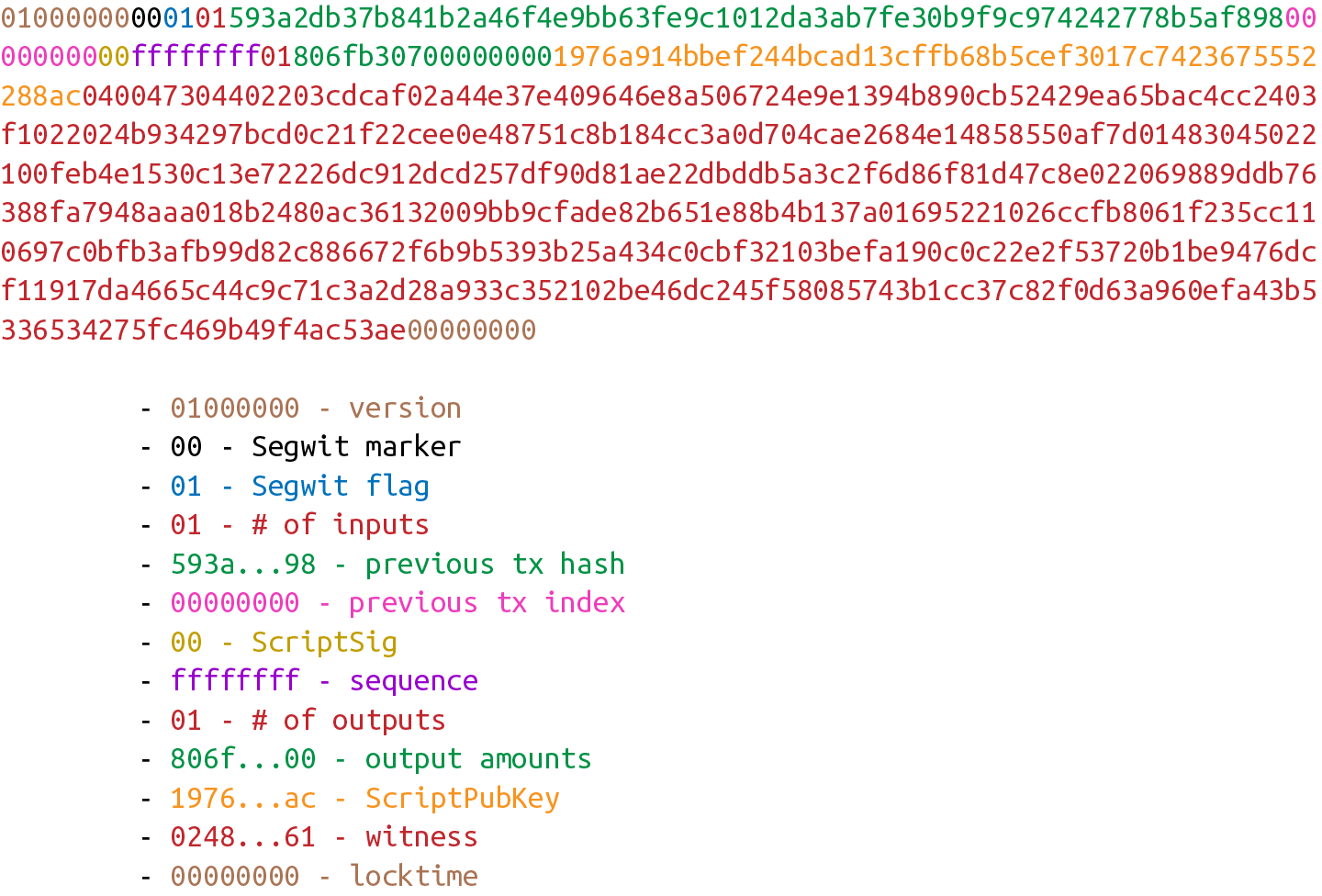
Figure 13-21. 升級的BIP0141 節點眼中的Pay-to-witness-script-hash
p2wsh 的公鑰腳本為 OP_0 <32-byte hash>。這個指令序列將觸發特殊的解析規則。簽名腳本和p2wpkh一樣為空。當p2wsh 的output 被使用時,合併後的腳本如圖Figure 13-22。

Figure13-22. Pay-to-witness-script-hash (p2wsh) 的公鑰腳本
腳本的初始計算和p2wpkh類似(Figure 13-23和Figure 13-24)。
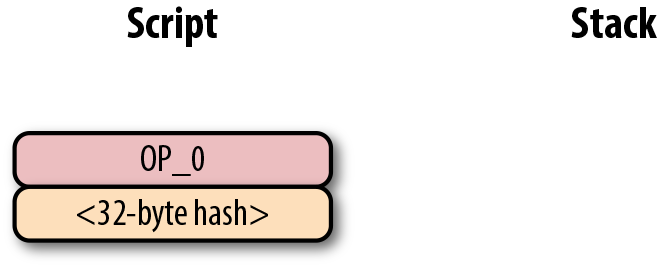
Figure 13-23. p2wsh 開始計算
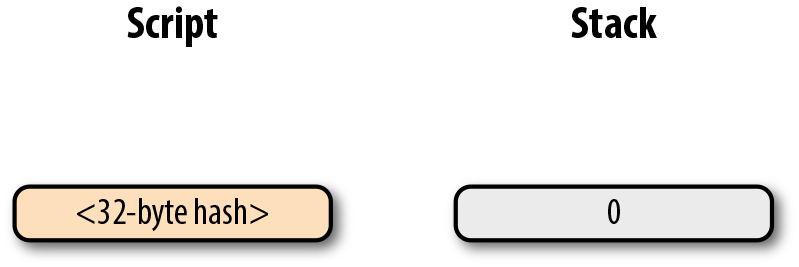
Figure 13-24. p2wsh 第一步
32個字節的的雜湊是一個元素,將被壓入棧中(Figure 13-25)。
Figure 13-25. p2wsh 第二步
和p2wpkh一樣,由於指令集沒有要處理的指令,舊節點此時結束計算。升級後的新節點則能識別這個特殊的序列,從而查找見證欄位並做額外的驗證。 在我們的例子中,見證欄位內的p2wsh 是一個2-of-3 的多重簽名(Figure 13-26)。

Figure 13-26. p2wsh 見證欄位
見證欄位的最後一項被稱為見證腳本(WitnessScript),其sha256 後的雜湊值必須和公鑰腳本的雜湊一致。注意這裡使用的雜湊函數是sha256而不是hash256。一旦公鑰腳本中的雜湊和見證腳本的雜湊一致,則見證腳本有效,將其加入到指令集。見證腳本如圖Figure 13-27。

Figure 13-27. p2wsh 的見證腳本
將見證欄位中的指令壓入指令集的頂部 如圖Figure 13-28。
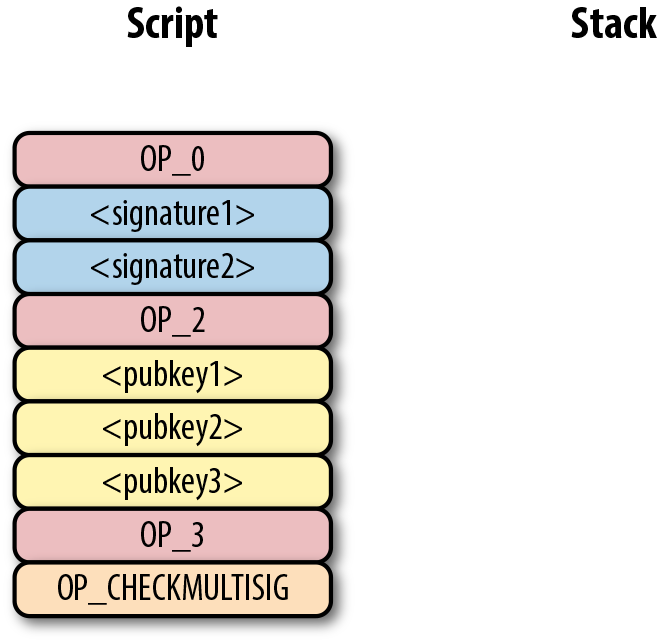
Figure 13-28. p2wsh 第三步
這是一個2-of-3 的多重簽名,和我們在第八章學習的差不多(Figure 13-29)。
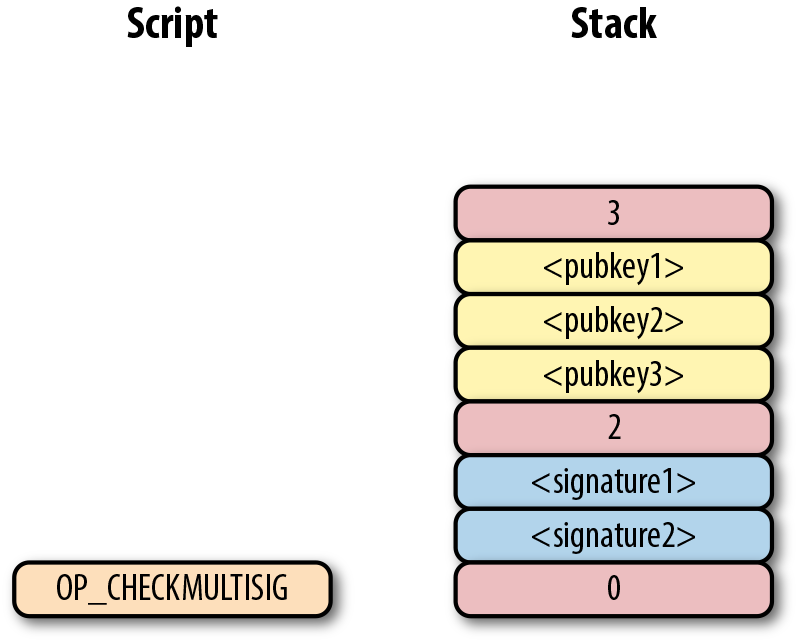
Figure 13-29. p2wsh 第四步
如果簽名有效,我們如圖Figure 13-30結束結算。

Figure 13-30. p2wsh 第五步
見證腳本和贖回腳本非常相似,序列化數據sha256後的雜湊儲存在公鑰腳本中,但只當output 被使用時才公開原始腳本。一旦見證腳本的sha256和32字節的雜湊一致時,見證腳本將被解析為Script 的指令,追加到指令集中。見證欄位的其餘部分也會添加到指令集中,構造了最總要計算的指令集。p2wsh非常重要,它是提供了非延展性的多重簽名交易,這將是閃電網路中的構造雙向支付通道所必備的。
13.6. p2sh-p2wsh
和 p2sh-p2wpkh 類似,p2sh-p2wsh 可以將p2wsh 變得向後兼容。類似的,給節點(Figure 13-31)和新節點(Figure 13-32)的交易是不同的。
Figure 13-31. 發送給未升級BIP0141節點的Pay-to-script-hash-pay-to-witness-script-hash (p2sh-p2wsh)交易
Figure 13-32. 發送給升級BIP0141節點的p2sh-p2wsh交易
和p2sh-p2wpkh一樣,無法從公鑰腳本來區分p2sh-p2wsh和其他p2sh。簽名腳本是唯一的贖回腳本(Figure 13-33)。

Figure 13-33. p2sh-p2wsh 的公鑰腳本
使用和p2sh-p2wpkh一樣的方法來進行腳本的計算(Figure 13-34) 。
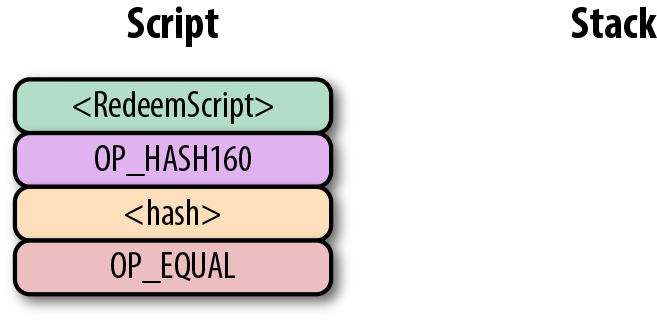
Figure 13-34. p2sh-p2wsh 開始計算
將贖回腳本壓入棧(Figure 13-35)。
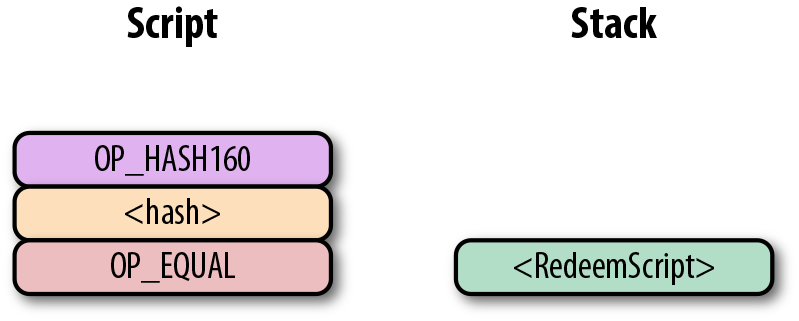
Figure 13-35. p2sh-p2wsh 第一步
OP_HASH160 將會向棧返回贖回腳本的雜湊(Figure 13-36)。
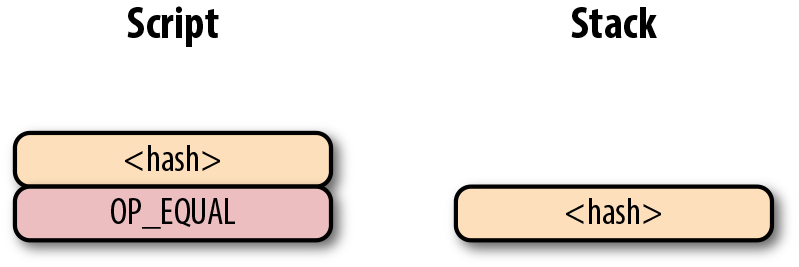
Figure 13-36. p2sh-p2wsh 第二步
將雜湊壓入棧後,我們接下來要處理的操作符是OP_EQUAL(Figure 13-37)。
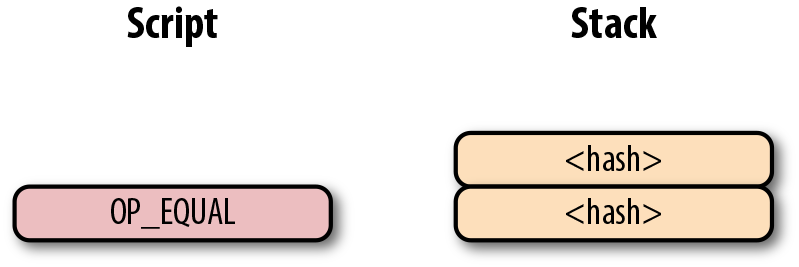
Figure 13-37. p2sh-p2wsh 第三步
和p2sh-p2wpkh一樣, 如果兩個雜湊相等,由於未升級BIP0016的節點不瞭解p2sh 的驗證規則,將標記此input為有效。升級了BIP0016的節點會識別出這是p2sh的指令序列,贖回腳本將被解析為新的腳本指令。贖回腳本的內容是OP_0 32-bytehash。這和p2wsh的公鑰腳本一樣。(Figure 13-38)。

Figure 13-38. p2sh-p2wsh 的贖回腳本
這會把腳本的狀態轉換成Figure 13-39。
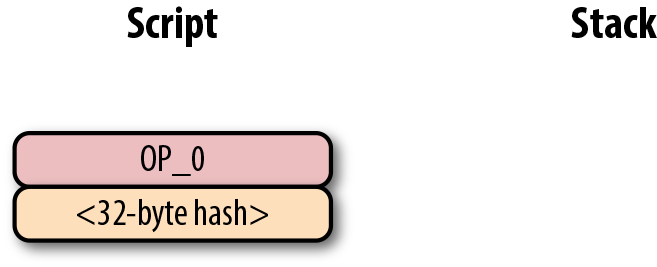
Figure 13-39. p2sh-p2wsh 第四步
理所當然,當前的腳本狀態和p2wsh的初始狀態是一樣的(Figure 13-40)。
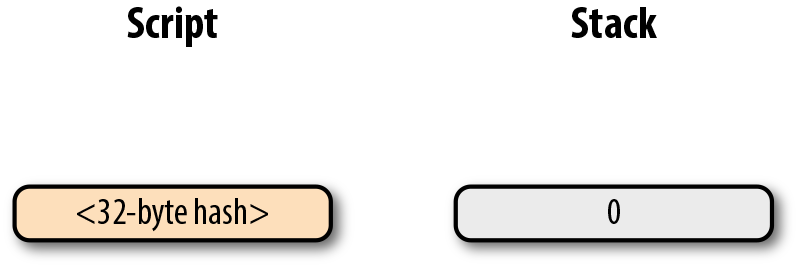
Figure 13-40. p2sh-p2wsh 第五步
32位的雜湊是一個元素,所以將其壓入棧(Figure 13-41)。
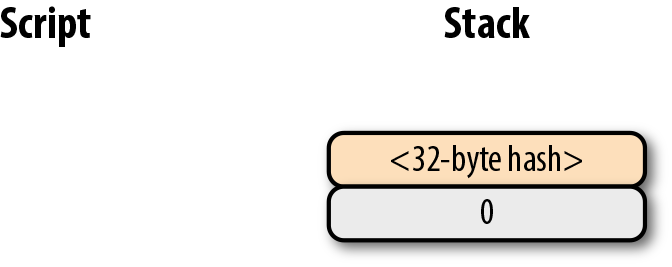
Figure 13-41. p2sh-p2wsh 第六步
此時,沒有升級隔離見證的節點由於不知道隔離見證的驗證規則,節點將會標記此input 為有效。但升級隔離見證的節點會識別出這是隔離見證的指令序列。見證欄位(Figure13-42)儲存了見證腳本(Figure 13-43)。見證腳本的sha256雜湊值將和32位的雜湊做比對。如果兩者相同,見證腳本將被解析為腳本指令,追加到指令集中(Figure 13-44)。
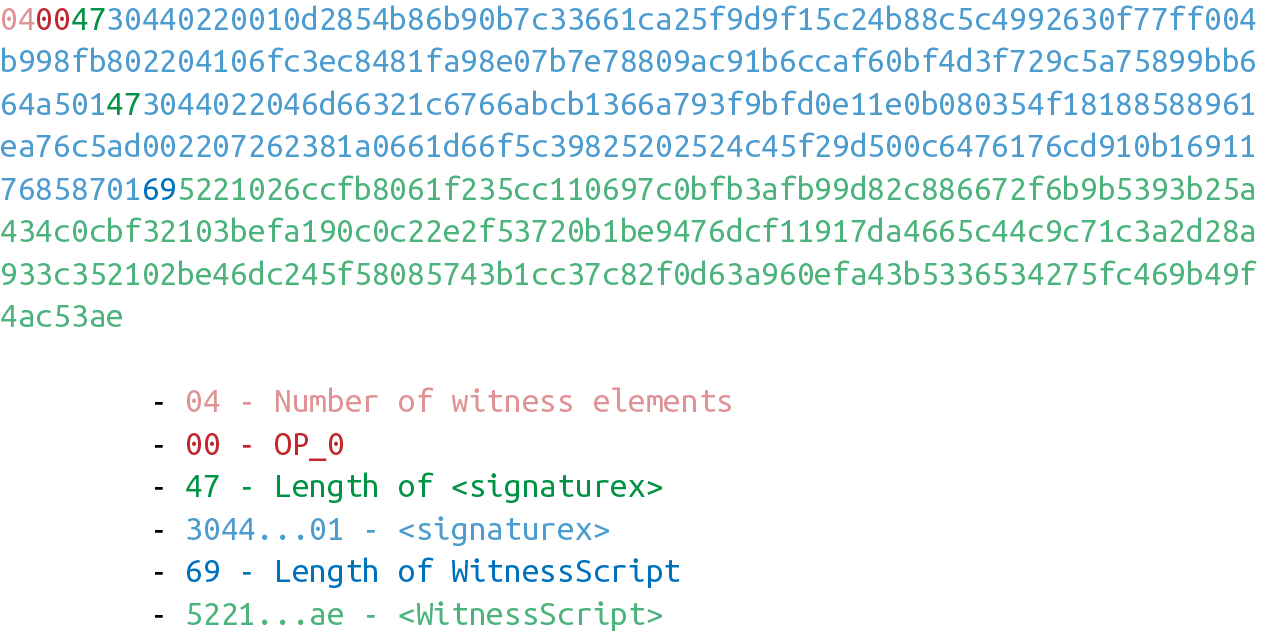
Figure 13-42. p2sh-p2wsh 見證欄位

Figure 13-43. p2sh-p2wsh 的見證腳本
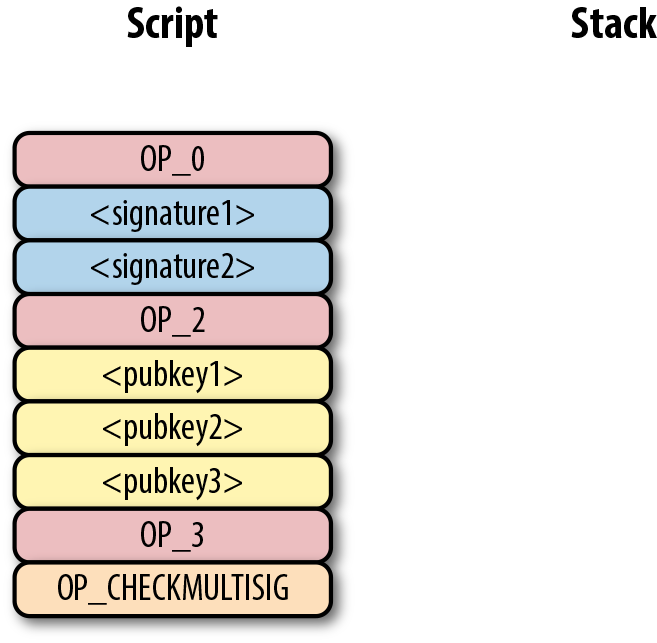
Figure 13-44. p2sh-p2wsh 第七步
如你所見,這是一個在第八章見過的2-of-3 的多重簽名。如果簽名有效,我們將如圖Figure 13-45結束腳本的計算
Figure 13-45. p2sh-p2wsh 結束計算
p2sh-p2wsh 使得p2wsh 可以向後兼容,允許舊版本的錢包支付到錢包可以處理的p2sh的公鑰腳本中。
13.7. 實現 p2wsh 和 p2sh-p2wsh 交易
解析和序列化和之前一致,不需要改動。主要的變動是tx.py 中的verify_input 函數和 script.py 的evaluate 函數。
class Tx:
...
def verify_input(self, input_index):
tx_in = self.tx_ins[input_index]
script_pubkey = tx_in.script_pubkey(testnet=self.testnet)
if script_pubkey.is_p2sh_script_pubkey():
command = tx_in.script_sig.commands[-1]
raw_redeem = int_to_little_endian(len(command), 1) + command
redeem_script = Script.parse(BytesIO(raw_redeem))
if redeem_script.is_p2wpkh_script_pubkey():
z = self.sig_hash_bip143(input_index, redeem_script)
witness = tx_in.witness
elif redeem_script.is_p2wsh_script_pubkey():#1
command = tx_in.witness[-1]
raw_witness = encode_varint(len(command)) + command
witness_script = Script.parse(BytesIO(raw_witness))
z = self.sig_hash_bip143(input_index,witness_script=witness_script)
witness = tx_in.witness
else:
z = self.sig_hash(input_index, redeem_script)
witness = None
else:
if script_pubkey.is_p2wpkh_script_pubkey():
z = self.sig_hash_bip143(input_index)
witness = tx_in.witness
elif script_pubkey.is_p2wsh_script_pubkey():#2
command = tx_in.witness[-1]
raw_witness = encode_varint(len(command)) + command
witness_script = Script.parse(BytesIO(raw_witness))
z = self.sig_hash_bip143(input_index,
witness_script=witness_script)
witness = tx_in.witness
else:
z = self.sig_hash(input_index)
witness = None
combined_script = tx_in.script_sig + tx_in.script_pubkey(self.testnet)
return combined_script.evaluate(z, witness)#1 此處代碼處理p2sh-p2wsh。
#2 此處代碼處理 p2wsh。
接下來我們要修改script.py,使其能識別 p2wsh:
def p2wsh_script(h256):
'''Takes a hash160 and returns the p2wsh ScriptPubKey'''
return Script([0x00, h256])
...
class Script:
...
def is_p2wsh_script_pubkey(self):
return len(self.cmds) == 2 and self.cmds[0] == 0x00 \
and type(self.cmds[1]) == bytes and len(self.cmds[1]) == 32#1 即我們所說的 OP_0 <32-byte script>。
接下來我們要處理p2wsh 腳本的特殊計算規則:
class Script:
...
def evaluate(self, z, witness):
...
while len(commands) > 0:
...
else:
stack.append(command)
...
if len(stack) == 2 and stack[0] == b'' and len(stack[1]) == 32:
s256 = stack.pop()#1
stack.pop() #2
cmds.extend(witness[:-1]) #3
witness_script = witness[-1]#4
if s256 != sha256(witness_script):#5
print('bad sha256 {} vs {}'.format (s256.hex(), sha256(witness_script).hex()))
return False
stream = BytesIO(encode_varint(len(witness_script))
+ witness_script)
witness_script_cmds = Script.parse(stream).cmds#6
cmds.extend(witness_script_cmds)#1 頂部的元素是見證腳本的sha256雜湊。
#2 第二個元素是見證版本號,0。
#3 除了見證腳本,都放置到指令集中。
#4 見證腳本是見證欄位的最後一個元素。
#5 見證腳本的sha256雜湊必須和棧頂的雜湊一致。
#6 解析見證腳本並將其放置到指令集中。
14. 第十四章 高級主題和下一步
如果你已經掌握了本書之前的內容,恭喜你!你已經掌握了很多的比特幣的內部工作原理的知識,可能也激發了你想要學習更多相關知識。本書只勾勒了表層的知識。在本章中,我們將討論一些你可能想要瞭解的其他主題,如何引導您成為比特幣開發者以及如何為社區貢獻代碼。
14.1. 推薦的下一步學習主題
以下是一些值得深入研究的主題。
14.1.1. 錢包
從頭構造錢包是一個有挑戰性的工作,因為保障私鑰安全是非常困難。好在我們有許多的標準來幫助我們創建錢包。
分層確定性錢包
考慮到隱私的保護,重復使用地址是一個非常差的選擇(見第七章討論)。這要求我們能夠構造許多地址,如果這些地址對應的私鑰不同,則儲存這些地址需要考慮安全和備份的問題。我們如何安全的備份私鑰?先生成很多私鑰再備份私鑰嗎?當你事先生成的私鑰用光後怎麼辦?我們對新生成的私鑰如何保存呢?是否有一個成系統的方法來保證當前的私鑰備份是最新的?
為瞭解決這一系列的問題,比特幣早期的錢包Armory率先採用的確定性錢包(deterministic wallet)。確定性錢包的設計思路是生成一個種子,並以此生成許多許多不同的地址。Armory 類的確定性的錢包雖然設計的很好,但不能滿足一些用戶對地址分組管理需求。於是分層確定性錢包(hierarchical wallet ,HD)標準,即BIP0032 誕生了。BIP0032錢包有多個層級和私鑰,每個私鑰都有唯一的路徑。在BIP0032中詳細定義了具體規範和測試工具。所以在測試鏈中實現你自己的HD 錢包是一個很好的學習方法。
此外 BIP0044 定義了 當使用一個HD種子來管理多個不同加密貨幣時,BIP0032標準中每層的意義和最佳實踐。實現BIP0044 也能很好地幫助你進一步理解HD 錢包的基礎設施。很多錢包(比如 Trezor,Coinmi 等)採用來BIP0032 和 BIP0044 這兩個標準。但也有一些錢包則放棄了BIP0044 的分層方案,使用其自己的分層方案(比如 Electrum 和 Edge)。
14.1.2. 支付通道和閃電網路
支付通道是指閃電網路的原子構成(atomic unit)。學習支付通道的運作原理也是下一步學習的好選擇。共建支付通道有很多選擇,其中BOLT 標準是閃電網路規範所採用的。其詳細規範在本書寫作時仍在不斷完善,可以從https://github.com/lightningnetwork/lightning-rfc/獲取相關信息。
14.2. 貢獻代碼
回饋比特幣社區是比特幣社區倫理的重要部分。開源項目是你為比特幣做出自己的貢獻主要途徑。有很多值得列出的比特幣開源項目,以下只是部分例子:
Bitcoin Core 比特幣的推薦客戶端
Libbitcoin 一個C++ 語言的比特幣實現。
btcd 一個go-lang實現的比特幣客戶端。
Bcoin 一個基於 JavaScript 的比特幣實現,由pruse.io維護。
pycoin 比特幣的python 庫
BitcoinJ 比特幣的java 庫
BitcoinJS 比特幣的JavaScript 庫。
BTCPay 比特幣的支付處理引擎。由C#實現。
貢獻開源項目是非常有好處的。比如未來的工作機會,學習,獲得商業靈感等。
14.3. 推薦的項目
如果此時你仍然在思考進入什麼樣的項目,下面是一些推薦的項目
14.3.1. 測試鏈錢包
理解比特幣安全的重要性是比較困難的。即使是在測試鏈中實現一個錢包也會幫助理解很多考量的細節,比如 用戶界面,地址簿,歷史交易,這些都是你要必須實現的部分。錢包也是比特幣相關的最熱門的應用,構造比特幣錢包可以幫助你深入理解用戶的需求。
14.3.2. 區塊鏈瀏覽器
自己實現區塊鏈瀏覽器則是一個更有難度的項目。實現一個區塊鏈瀏覽器的核心是儲存區塊鏈數據並使之易於訪問。可以使用傳統的數據庫比如Postgres 和 MySQL。由於Bitcoin Core 的客戶端並沒有對地址進行索引,為地址增加索引有助於對UTXO 的查詢和根據地址對歷史交易進行查詢,這兩類查詢也是大部分用戶想要的服務。
14.3.3. 網上商店
基於比特幣的商店也是一個有助於學習比特幣的項目。尤其適合web 開發者,因為他們瞭解如何開發web 應用。使用比特幣作為後端的web應用是避免第三方依賴進行支付的有效途徑。這裡我們再強調一下,建議在項目開始時,在測試鏈上進行開發,並使用可用於加密付款的加密安全的代碼庫。
14.3.4. 工具庫
如同本書中構建的工具庫也是一個學習比特幣的好選擇。比如實現BIP0143中對隔離見證簽名雜湊的序列化,可以指導你逐漸習慣協議的開發。將本書的代碼用另一種語言實現也是很好的方法。
14.3.5. 尋找工作
如果你想更深入的瞭解相關行業,對開發者來說也有很多機會。向他人證明自己瞭解相關知識的關鍵是自己完成了一些相關的項目。向開源項目貢獻代碼或者開發自己的項目會吸引一些公司的注意。此外針對特定公司的API編程也是獲取該公司工作面試的好方法。 證明您知道某事的關鍵是擁有自己完成的項目組合。
通常來說,獲取一個公司的當地工作要比獲取遠程工作機會要容易的多,很多公司不願意承擔遠程工作的風險。參見當地見面會(meet up),並與在那裡遇到的人建立關係,得到一份當地的比特幣工作將變得容易得多。
同樣地,獲得一份遠程工作也需要讓別人有機會瞭解你。除了貢獻開源項目外,還可以參加會議,網上社交,構思自己的技術相關內容(比如YouTube視頻,博客等)這些也會幫助你得到他人的注意並最終獲得一份遠程的工作。
14.4. 總結
對於你能讀到這裡我很開心。如果您願意,可以發送在本書中的收穫,我很想收到您的反饋和來信。可以通過郵件地址[email protected] 聯繫到我。
Appendix A: 附錄 A 習題解答
A.1. 第一章:有限域
以下為第一章各練習題的解答。
A.1.1. Exercise 1
題目請參閱對應章節。
class FieldElement:
...
def __ne__(self, other):
# this should be the inverse of the == operator
return not (self == other)A.1.2. Exercise 2
題目請參閱對應章節。
>>> prime = 57
>>> print((44+33)%prime)
20
>>> print((9-29)%prime)
37
>>> print((17+42+49)%prime)
51
>>> print((52-30-38)%prime)
41A.1.3. Exercise 3
題目請參閱對應章節。
class FieldElement:
...
def __sub__(self, other):
if self.prime != other.prime:
raise TypeError('Cannot subtract two numbers in different Fields')
# self.num and other.num are the actual values
# self.prime is what we need to mod against
num = (self.num - other.num) % self.prime
# we return an element of the same class
return self.__class__(num, self.prime)A.1.4. Exercise 4
題目請參閱對應章節。
>>> prime = 97
>>> print(95*45*31 % prime)
23
>>> print(17*13*19*44 % prime)
68
>>> print(12**7*77**49 % prime)
63A.1.5. Exercise 5
題目請參閱對應章節。
>>> prime = 19
>>> for k in (1,3,7,13,18):
... print([k*i % prime for i in range(prime)])
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]
[0, 3, 6, 9, 12, 15, 18, 2, 5, 8, 11, 14, 17, 1, 4, 7, 10, 13, 16]
[0, 7, 14, 2, 9, 16, 4, 11, 18, 6, 13, 1, 8, 15, 3, 10, 17, 5, 12]
[0, 13, 7, 1, 14, 8, 2, 15, 9, 3, 16, 10, 4, 17, 11, 5, 18, 12, 6]
[0, 18, 17, 16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
>>> for k in (1,3,7,13,18):
... print(sorted([k*i % prime for i in range(prime)]))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18]A.1.6. Exercise 6
題目請參閱對應章節。
class FieldElement:
...
def __mul__(self, other):
if self.prime != other.prime:
raise TypeError('Cannot multiply two numbers in different Fields')
# self.num and other.num are the actual values
# self.prime is what we need to mod against
num = (self.num * other.num) % self.prime
# we return an element of the same class
return self.__class__(num, self.prime)A.1.7. Exercise 7
題目請參閱對應章節。
>>> for prime in (7, 11, 17, 31):
... print([pow(i, prime-1, prime) for i in range(1, prime)])
[1, 1, 1, 1, 1, 1]
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, \
1, 1, 1, 1, 1, 1]A.1.8. Exercise 8
題目請參閱對應章節。
>>> prime = 31
>>> print(3*pow(24, prime-2, prime) % prime)
4
>>> print(pow(17, prime-4, prime))
29
>>> print(pow(4, prime-5, prime)*11 % prime)
13A.1.9. Exercise 9
題目請參閱對應章節。
class FieldElement:
...
def __truediv__(self, other):
if self.prime != other.prime:
raise TypeError('Cannot divide two numbers in different Fields')
# use Fermat's little theorem:
# self.num**(p-1) % p == 1
# this means:
# 1/n == pow(n, p-2, p)
# we return an element of the same class
num = self.num * pow(other.num, self.prime - 2, self.prime) % self.prime
return self.__class__(num, self.prime)A.2. 第二章:橢圓曲線
以下為第二章各練習題的解答。
A.2.1. Exercise 1
題目請參閱對應章節。
>>> def on_curve(x, y):
... return y**2 == x**3 + 5*x + 7
>>> print(on_curve(2,4))
False
>>> print(on_curve(-1,-1))
True
>>> print(on_curve(18,77))
True
>>> print(on_curve(5,7))
FalseA.2.3. Exercise 3
題目請參閱對應章節。
class Point:
...
if self.x == other.x and self.y != other.y:
return self.__class__(None, None, self.a, self.b)A.2.4. Exercise 4
題目請參閱對應章節。
>>> x1, y1 = 2, 5
>>> x2, y2 = -1, -1
>>> s = (y2 - y1) / (x2 - x1)
>>> x3 = s**2 - x1 - x2
>>> y3 = s * (x1 - x3) - y1
>>> print(x3, y3)
3.0 -7.0A.2.5. Exercise 5
題目請參閱對應章節。
class Point:
...
def __add__(self, other):
...
if self.x != other.x:
s = (other.y - self.y) / (other.x - self.x)
x = s**2 - self.x - other.x
y = s * (self.x - x) - self.y
return self.__class__(x, y, self.a, self.b)A.3. 第三章:橢圓曲線密碼學
以下為第三章各練習題的解答。
A.3.1. Exercise 1
題目請參閱對應章節。
>>> from ecc import FieldElement
>>> prime = 223
>>> a = FieldElement(0, prime)
>>> b = FieldElement(7, prime)
>>> def on_curve(x,y):
... return y**2 == x**3 + a*x + b
>>> print(on_curve(FieldElement(192, prime), FieldElement(105, prime)))
True
>>> print(on_curve(FieldElement(17, prime), FieldElement(56, prime)))
True
>>> print(on_curve(FieldElement(200, prime), FieldElement(119, prime)))
False
>>> print(on_curve(FieldElement(1, prime), FieldElement(193, prime)))
True
>>> print(on_curve(FieldElement(42, prime), FieldElement(99, prime)))
FalseA.3.2. Exercise 2
題目請參閱對應章節。
>>> from ecc import FieldElement, Point
>>> prime = 223
>>> a = FieldElement(0, prime)
>>> b = FieldElement(7, prime)
>>> p1 = Point(FieldElement(170, prime), FieldElement(142, prime), a, b)
>>> p2 = Point(FieldElement(60, prime), FieldElement(139, prime), a, b)
>>> print(p1+p2)
Point(220,181)_0_7 FieldElement(223)
>>> p1 = Point(FieldElement(47, prime), FieldElement(71, prime), a, b)
>>> p2 = Point(FieldElement(17, prime), FieldElement(56, prime), a, b)
>>> print(p1+p2)
Point(215,68)_0_7 FieldElement(223)
>>> p1 = Point(FieldElement(143, prime), FieldElement(98, prime), a, b)
>>> p2 = Point(FieldElement(76, prime), FieldElement(66, prime), a, b)
>>> print(p1+p2)
Point(47,71)_0_7 FieldElement(223)A.3.3. Exercise 3
題目請參閱對應章節。
def test_add(self):
prime = 223
a = FieldElement(0, prime)
b = FieldElement(7, prime)
additions = (
(192, 105, 17, 56, 170, 142),
(47, 71, 117, 141, 60, 139),
(143, 98, 76, 66, 47, 71),
)
for x1_raw, y1_raw, x2_raw, y2_raw, x3_raw, y3_raw in additions:
x1 = FieldElement(x1_raw, prime)
y1 = FieldElement(y1_raw, prime)
p1 = Point(x1, y1, a, b)
x2 = FieldElement(x2_raw, prime)
y2 = FieldElement(y2_raw, prime)
p2 = Point(x2, y2, a, b)
x3 = FieldElement(x3_raw, prime)
y3 = FieldElement(y3_raw, prime)
p3 = Point(x3, y3, a, b)
self.assertEqual(p1 + p2, p3)A.3.4. Exercise 4
題目請參閱對應章節。
>>> from ecc import FieldElement, Point
>>> prime = 223
>>> a = FieldElement(0, prime)
>>> b = FieldElement(7, prime)
>>> x1 = FieldElement(num=192, prime=prime)
>>> y1 = FieldElement(num=105, prime=prime)
>>> p = Point(x1,y1,a,b)
>>> print(p+p)
Point(49,71)_0_7 FieldElement(223)
>>> x1 = FieldElement(num=143, prime=prime)
>>> y1 = FieldElement(num=98, prime=prime)
>>> p = Point(x1,y1,a,b)
>>> print(p+p)
Point(64,168)_0_7 FieldElement(223)
>>> x1 = FieldElement(num=47, prime=prime)
>>> y1 = FieldElement(num=71, prime=prime)
>>> p = Point(x1,y1,a,b)
>>> print(p+p)
Point(36,111)_0_7 FieldElement(223)
>>> print(p+p+p+p)
Point(194,51)_0_7 FieldElement(223)
>>> print(p+p+p+p+p+p+p+p)
Point(116,55)_0_7 FieldElement(223)
>>> print(p+p+p+p+p+p+p+p+p+p+p+p+p+p+p+p+p+p+p+p+p)
Point(infinity)A.3.5. Exercise 5
題目請參閱對應章節。
>>> prime = 223
>>> a = FieldElement(0, prime)
>>> b = FieldElement(7, prime)
>>> x = FieldElement(15, prime)
>>> y = FieldElement(86, prime)
>>> p = Point(x, y, a, b)
>>> inf = Point(None, None, a, b)
>>> product = p
>>> count = 1
>>> while product != inf:
... product += p
... count += 1
>>> print(count)
7A.3.6. Exercise 6
題目請參閱對應章節。
>>> from ecc import S256Point, N, G
>>> point = S256Point(
... 0x887387e452b8eacc4acfde10d9aaf7f6d9a0f975aabb10d006e4da568744d06c,
... 0x61de6d95231cd89026e286df3b6ae4a894a3378e393e93a0f45b666329a0ae34)
>>> z = 0xec208baa0fc1c19f708a9ca96fdeff3ac3f230bb4a7ba4aede4942ad003c0f60
>>> r = 0xac8d1c87e51d0d441be8b3dd5b05c8795b48875dffe00b7ffcfac23010d3a395
>>> s = 0x68342ceff8935ededd102dd876ffd6ba72d6a427a3edb13d26eb0781cb423c4
>>> u = z * pow(s, N-2, N) % N
>>> v = r * pow(s, N-2, N) % N
>>> print((u*G + v*point).x.num == r)
True
>>> z = 0x7c076ff316692a3d7eb3c3bb0f8b1488cf72e1afcd929e29307032997a838a3d
>>> r = 0xeff69ef2b1bd93a66ed5219add4fb51e11a840f404876325a1e8ffe0529a2c
>>> s = 0xc7207fee197d27c618aea621406f6bf5ef6fca38681d82b2f06fddbdce6feab6
>>> u = z * pow(s, N-2, N) % N
>>> v = r * pow(s, N-2, N) % N
>>> print((u*G + v*point).x.num == r)
TrueA.3.7. Exercise 7
題目請參閱對應章節。
>>> from ecc import S256Point, G, N
>>> from helper import hash256
>>> e = 12345
>>> z = int.from_bytes(hash256(b'Programming Bitcoin!'), 'big')
>>> k = 1234567890
>>> r = (k*G).x.num
>>> k_inv = pow(k, N-2, N)
>>> s = (z+r*e) * k_inv % N
>>> print(e*G)
S256Point(f01d6b9018ab421dd410404cb869072065522bf85734008f105cf385a023a80f, \
0eba29d0f0c5408ed681984dc525982abefccd9f7ff01dd26da4999cf3f6a295)
>>> print(hex(z))
0x969f6056aa26f7d2795fd013fe88868d09c9f6aed96965016e1936ae47060d48
>>> print(hex(r))
0x2b698a0f0a4041b77e63488ad48c23e8e8838dd1fb7520408b121697b782ef22
>>> print(hex(s))
0x1dbc63bfef4416705e602a7b564161167076d8b20990a0f26f316cff2cb0bc1aA.4. 第四章:序列化
以下為第四章各練習題的解答。
A.4.1. Exercise 1
題目請參閱對應章節。
>>> from ecc import PrivateKey
>>> priv = PrivateKey(5000)
>>> print(priv.point.sec(compressed=False).hex())
04ffe558e388852f0120e46af2d1b370f85854a8eb0841811ece0e3e03d282d57c315dc72890a4\
f10a1481c031b03b351b0dc79901ca18a00cf009dbdb157a1d10
>>> priv = PrivateKey(2018**5)
>>> print(priv.point.sec(compressed=False).hex())
04027f3da1918455e03c46f659266a1bb5204e959db7364d2f473bdf8f0a13cc9dff87647fd023\
c13b4a4994f17691895806e1b40b57f4fd22581a4f46851f3b06
>>> priv = PrivateKey(0xdeadbeef12345)
>>> print(priv.point.sec(compressed=False).hex())
04d90cd625ee87dd38656dd95cf79f65f60f7273b67d3096e68bd81e4f5342691f842efa762fd5\
9961d0e99803c61edba8b3e3f7dc3a341836f97733aebf987121A.4.2. Exercise 2
題目請參閱對應章節。
>>> from ecc import PrivateKey
>>> priv = PrivateKey(5001)
>>> print(priv.point.sec(compressed=True).hex())
0357a4f368868a8a6d572991e484e664810ff14c05c0fa023275251151fe0e53d1
>>> priv = PrivateKey(2019**5)
>>> print(priv.point.sec(compressed=True).hex())
02933ec2d2b111b92737ec12f1c5d20f3233a0ad21cd8b36d0bca7a0cfa5cb8701
>>> priv = PrivateKey(0xdeadbeef54321)
>>> print(priv.point.sec(compressed=True).hex())
0296be5b1292f6c856b3c5654e886fc13511462059089cdf9c479623bfcbe77690A.4.3. Exercise 3
題目請參閱對應章節。
>>> from ecc import Signature
>>> r = 0x37206a0610995c58074999cb9767b87af4c4978db68c06e8e6e81d282047a7c6
>>> s = 0x8ca63759c1157ebeaec0d03cecca119fc9a75bf8e6d0fa65c841c8e2738cdaec
>>> sig = Signature(r,s)
>>> print(sig.der().hex())
3045022037206a0610995c58074999cb9767b87af4c4978db68c06e8e6e81d282047a7c6022100\
8ca63759c1157ebeaec0d03cecca119fc9a75bf8e6d0fa65c841c8e2738cdaecA.4.4. Exercise 4
題目請參閱對應章節。
>>> from helper import encode_base58
>>> h = '7c076ff316692a3d7eb3c3bb0f8b1488cf72e1afcd929e29307032997a838a3d'
>>> print(encode_base58(bytes.fromhex(h)))
9MA8fRQrT4u8Zj8ZRd6MAiiyaxb2Y1CMpvVkHQu5hVM6
>>> h = 'eff69ef2b1bd93a66ed5219add4fb51e11a840f404876325a1e8ffe0529a2c'
>>> print(encode_base58(bytes.fromhex(h)))
4fE3H2E6XMp4SsxtwinF7w9a34ooUrwWe4WsW1458Pd
>>> h = 'c7207fee197d27c618aea621406f6bf5ef6fca38681d82b2f06fddbdce6feab6'
>>> print(encode_base58(bytes.fromhex(h)))
EQJsjkd6JaGwxrjEhfeqPenqHwrBmPQZjJGNSCHBkcF7A.4.5. Exercise 5
題目請參閱對應章節。
>>> from ecc import PrivateKey
>>> priv = PrivateKey(5002)
>>> print(priv.point.address(compressed=False, testnet=True))
mmTPbXQFxboEtNRkwfh6K51jvdtHLxGeMA
>>> priv = PrivateKey(2020**5)
>>> print(priv.point.address(compressed=True, testnet=True))
mopVkxp8UhXqRYbCYJsbeE1h1fiF64jcoH
>>> priv = PrivateKey(0x12345deadbeef)
>>> print(priv.point.address(compressed=True, testnet=False))
1F1Pn2y6pDb68E5nYJJeba4TLg2U7B6KF1A.4.6. Exercise 6
題目請參閱對應章節。
>>> from ecc import PrivateKey
>>> priv = PrivateKey(5003)
>>> print(priv.wif(compressed=True, testnet=True))
cMahea7zqjxrtgAbB7LSGbcQUr1uX1ojuat9jZodMN8rFTv2sfUK
>>> priv = PrivateKey(2021**5)
>>> print(priv.wif(compressed=False, testnet=True))
91avARGdfge8E4tZfYLoxeJ5sGBdNJQH4kvjpWAxgzczjbCwxic
>>> priv = PrivateKey(0x54321deadbeef)
>>> print(priv.wif(compressed=True, testnet=False))
KwDiBf89QgGbjEhKnhXJuH7LrciVrZi3qYjgiuQJv1h8Ytr2S53aA.4.7. Exercise 7
題目請參閱對應章節。
def little_endian_to_int(b):
'''little_endian_to_int takes byte sequence as a little-endian number.
Returns an integer'''
return int.from_bytes(b, 'little')A.4.8. Exercise 8
題目請參閱對應章節。
def int_to_little_endian(n, length):
'''endian_to_little_endian takes an integer and returns the little-endian
byte sequence of length'''
return n.to_bytes(length, 'little')A.4.9. Exercise 9
題目請參閱對應章節。
>>> from ecc import PrivateKey
>>> from helper import hash256, little_endian_to_int
>>> passphrase = b'[email protected] my secret'
>>> secret = little_endian_to_int(hash256(passphrase))
>>> priv = PrivateKey(secret)
>>> print(priv.point.address(testnet=True))
mft9LRNtaBNtpkknB8xgm17UvPedZ4ecYLA.5. 第五章:交易
以下為第五章各練習題的解答。
A.5.1. Exercise 1
題目請參閱對應章節。
class Tx:
...
@classmethod
def parse(cls, s, testnet=False):
version = little_endian_to_int(s.read(4))
return cls(version, None, None, None, testnet=testnet)A.5.2. Exercise 2
題目請參閱對應章節。
class Tx:
...
@classmethod
def parse(cls, s, testnet=False):
version = little_endian_to_int(s.read(4))
num_inputs = read_varint(s)
inputs = []
for _ in range(num_inputs):
inputs.append(TxIn.parse(s))
return cls(version, inputs, None, None, testnet=testnet)
...
class TxIn:
...
@classmethod
def parse(cls, s):
'''Takes a byte stream and parses the tx_input at the start.
Returns a TxIn object.
'''
prev_tx = s.read(32)[::-1]
prev_index = little_endian_to_int(s.read(4))
script_sig = Script.parse(s)
sequence = little_endian_to_int(s.read(4))
return cls(prev_tx, prev_index, script_sig, sequence)A.5.3. Exercise 3
題目請參閱對應章節。
class Tx:
...
@classmethod
def parse(cls, s, testnet=False):
version = little_endian_to_int(s.read(4))
num_inputs = read_varint(s)
inputs = []
for _ in range(num_inputs):
inputs.append(TxIn.parse(s))
num_outputs = read_varint(s)
outputs = []
for _ in range(num_outputs):
outputs.append(TxOut.parse(s))
return cls(version, inputs, outputs, None, testnet=testnet)
...
class TxOut:
...
@classmethod
def parse(cls, s):
'''Takes a byte stream and parses the tx_output at the start.
Returns a TxOut object.
'''
amount = little_endian_to_int(s.read(8))
script_pubkey = Script.parse(s)
return cls(amount, script_pubkey)A.5.4. Exercise 4
題目請參閱對應章節。
class Tx:
...
@classmethod
def parse(cls, s, testnet=False):
version = little_endian_to_int(s.read(4))
num_inputs = read_varint(s)
inputs = []
for _ in range(num_inputs):
inputs.append(TxIn.parse(s))
num_outputs = read_varint(s)
outputs = []
for _ in range(num_outputs):
outputs.append(TxOut.parse(s))
locktime = little_endian_to_int(s.read(4))
return cls(version, inputs, outputs, locktime, testnet=testnet)A.5.5. Exercise 5
題目請參閱對應章節。
>>> from io import BytesIO
>>> from tx import Tx
>>> hex_transaction = '010000000456919960ac691763688d3d3bcea9ad6ecaf875df5339e\
148a1fc61c6ed7a069e010000006a47304402204585bcdef85e6b1c6af5c2669d4830ff86e42dd\
205c0e089bc2a821657e951c002201024a10366077f87d6bce1f7100ad8cfa8a064b39d4e8fe4e\
a13a7b71aa8180f012102f0da57e85eec2934a82a585ea337ce2f4998b50ae699dd79f5880e253\
dafafb7feffffffeb8f51f4038dc17e6313cf831d4f02281c2a468bde0fafd37f1bf882729e7fd\
3000000006a47304402207899531a52d59a6de200179928ca900254a36b8dff8bb75f5f5d71b1c\
dc26125022008b422690b8461cb52c3cc30330b23d574351872b7c361e9aae3649071c1a716012\
1035d5c93d9ac96881f19ba1f686f15f009ded7c62efe85a872e6a19b43c15a2937feffffff567\
bf40595119d1bb8a3037c356efd56170b64cbcc160fb028fa10704b45d775000000006a4730440\
2204c7c7818424c7f7911da6cddc59655a70af1cb5eaf17c69dadbfc74ffa0b662f02207599e08\
bc8023693ad4e9527dc42c34210f7a7d1d1ddfc8492b654a11e7620a0012102158b46fbdff65d0\
172b7989aec8850aa0dae49abfb84c81ae6e5b251a58ace5cfeffffffd63a5e6c16e620f86f375\
925b21cabaf736c779f88fd04dcad51d26690f7f345010000006a47304402200633ea0d3314bea\
0d95b3cd8dadb2ef79ea8331ffe1e61f762c0f6daea0fabde022029f23b3e9c30f080446150b23\
852028751635dcee2be669c2a1686a4b5edf304012103ffd6f4a67e94aba353a00882e563ff272\
2eb4cff0ad6006e86ee20dfe7520d55feffffff0251430f00000000001976a914ab0c0b2e98b1a\
b6dbf67d4750b0a56244948a87988ac005a6202000000001976a9143c82d7df364eb6c75be8c80\
df2b3eda8db57397088ac46430600'
>>> stream = BytesIO(bytes.fromhex(hex_transaction))
>>> tx_obj = Tx.parse(stream)
>>> print(tx_obj.tx_ins[1].script_sig)
304402207899531a52d59a6de200179928ca900254a36b8dff8bb75f5f5d71b1cdc26125022008\
b422690b8461cb52c3cc30330b23d574351872b7c361e9aae3649071c1a71601 035d5c93d9ac9\
6881f19ba1f686f15f009ded7c62efe85a872e6a19b43c15a2937
>>> print(tx_obj.tx_outs[0].script_pubkey)
OP_DUP OP_HASH160 ab0c0b2e98b1ab6dbf67d4750b0a56244948a879 \
OP_EQUALVERIFY OP_CHECKSIG
>>> print(tx_obj.tx_outs[1].amount)
40000000A.6. 第六章:Script
以下為第六章各練習題的解答。
A.6.1. Exercise 1
題目請參閱對應章節。
def op_hash160(stack):
if len(stack) < 1:
return False
element = stack.pop()
h160 = hash160(element)
stack.append(h160)
return TrueA.6.2. Exercise 2
題目請參閱對應章節。
def op_checksig(stack, z):
if len(stack) < 2:
return False
sec_pubkey = stack.pop()
der_signature = stack.pop()[:-1]
try:
point = S256Point.parse(sec_pubkey)
sig = Signature.parse(der_signature)
except (ValueError, SyntaxError) as e:
return False
if point.verify(z, sig):
stack.append(encode_num(1))
else:
stack.append(encode_num(0))
return TrueA.6.3. Exercise 3
題目請參閱對應章節。
>>> from script import Script
>>> script_pubkey = Script([0x76, 0x76, 0x95, 0x93, 0x56, 0x87])
>>> script_sig = Script([0x52])
>>> combined_script = script_sig + script_pubkey
>>> print(combined_script.evaluate(0))
TrueA.6.4. Exercise 4
題目請參閱對應章節。
>>> from script import Script
>>> script_pubkey = Script([0x6e, 0x87, 0x91, 0x69, 0xa7, 0x7c, 0xa7, 0x87])
>>> c1 = '255044462d312e330a25e2e3cfd30a0a0a312030206f626a0a3c3c2f576964746820\
32203020522f4865696768742033203020522f547970652034203020522f537562747970652035\
203020522f46696c7465722036203020522f436f6c6f7253706163652037203020522f4c656e67\
74682038203020522f42697473506572436f6d706f6e656e7420383e3e0a73747265616d0affd8\
fffe00245348412d3120697320646561642121212121852fec092339759c39b1a1c63c4c97e1ff\
fe017f46dc93a6b67e013b029aaa1db2560b45ca67d688c7f84b8c4c791fe02b3df614f86db169\
0901c56b45c1530afedfb76038e972722fe7ad728f0e4904e046c230570fe9d41398abe12ef5bc\
942be33542a4802d98b5d70f2a332ec37fac3514e74ddc0f2cc1a874cd0c78305a215664613097\
89606bd0bf3f98cda8044629a1'
>>> c2 = '255044462d312e330a25e2e3cfd30a0a0a312030206f626a0a3c3c2f576964746820\
32203020522f4865696768742033203020522f547970652034203020522f537562747970652035\
203020522f46696c7465722036203020522f436f6c6f7253706163652037203020522f4c656e67\
74682038203020522f42697473506572436f6d706f6e656e7420383e3e0a73747265616d0affd8\
fffe00245348412d3120697320646561642121212121852fec092339759c39b1a1c63c4c97e1ff\
fe017346dc9166b67e118f029ab621b2560ff9ca67cca8c7f85ba84c79030c2b3de218f86db3a9\
0901d5df45c14f26fedfb3dc38e96ac22fe7bd728f0e45bce046d23c570feb141398bb552ef5a0\
a82be331fea48037b8b5d71f0e332edf93ac3500eb4ddc0decc1a864790c782c76215660dd3097\
91d06bd0af3f98cda4bc4629b1'
>>> collision1 = bytes.fromhex(c1)
>>> collision2 = bytes.fromhex(c2)
>>> script_sig = Script([collision1, collision2])
>>> combined_script = script_sig + script_pubkey
>>> print(combined_script.evaluate(0))
TrueA.7. 第七章:交易的創建與驗證
以下為第七章各練習題的解答。
A.7.1. Exercise 1
題目請參閱對應章節。
class Tx:
...
def sig_hash(self, input_index):
s = int_to_little_endian(self.version, 4)
s += encode_varint(len(self.tx_ins))
for i, tx_in in enumerate(self.tx_ins):
if i == input_index:
s += TxIn(
prev_tx=tx_in.prev_tx,
prev_index=tx_in.prev_index,
script_sig=tx_in.script_pubkey(self.testnet),
sequence=tx_in.sequence,
).serialize()
else:
s += TxIn(
prev_tx=tx_in.prev_tx,
prev_index=tx_in.prev_index,
sequence=tx_in.sequence,
).serialize()
s += encode_varint(len(self.tx_outs))
for tx_out in self.tx_outs:
s += tx_out.serialize()
s += int_to_little_endian(self.locktime, 4)
s += int_to_little_endian(SIGHASH_ALL, 4)
h256 = hash256(s)
return int.from_bytes(h256, 'big')A.7.2. Exercise 2
題目請參閱對應章節。
class Tx:
...
def verify_input(self, input_index):
tx_in = self.tx_ins[input_index]
script_pubkey = tx_in.script_pubkey(testnet=self.testnet)
z = self.sig_hash(input_index)
combined = tx_in.script_sig + script_pubkey
return combined.evaluate(z)A.7.3. Exercise 3
題目請參閱對應章節。
class Tx:
...
def sign_input(self, input_index, private_key):
z = self.sig_hash(input_index)
der = private_key.sign(z).der()
sig = der + SIGHASH_ALL.to_bytes(1, 'big')
sec = private_key.point.sec()
self.tx_ins[input_index].script_sig = Script([sig, sec])
return self.verify_input(input_index)A.7.4. Exercise 4
題目請參閱對應章節。
>>> from ecc import PrivateKey
>>> from helper import decode_base58, SIGHASH_ALL
>>> from script import p2pkh_script, Script
>>> from tx import TxIn, TxOut, Tx
>>> prev_tx = bytes.fromhex('75a1c4bc671f55f626dda1074c7725991e6f68b8fcefcfca7\
b64405ca3b45f1c')
>>> prev_index = 1
>>> target_address = 'miKegze5FQNCnGw6PKyqUbYUeBa4x2hFeM'
>>> target_amount = 0.01
>>> change_address = 'mzx5YhAH9kNHtcN481u6WkjeHjYtVeKVh2'
>>> change_amount = 0.009
>>> secret = 8675309
>>> priv = PrivateKey(secret=secret)
>>> tx_ins = []
>>> tx_ins.append(TxIn(prev_tx, prev_index))
>>> tx_outs = []
>>> h160 = decode_base58(target_address)
>>> script_pubkey = p2pkh_script(h160)
>>> target_satoshis = int(target_amount*100000000)
>>> tx_outs.append(TxOut(target_satoshis, script_pubkey))
>>> h160 = decode_base58(change_address)
>>> script_pubkey = p2pkh_script(h160)
>>> change_satoshis = int(change_amount*100000000)
>>> tx_outs.append(TxOut(change_satoshis, script_pubkey))
>>> tx_obj = Tx(1, tx_ins, tx_outs, 0, testnet=True)
>>> print(tx_obj.sign_input(0, priv))
True
>>> print(tx_obj.serialize().hex())
01000000011c5fb4a35c40647bcacfeffcb8686f1e9925774c07a1dd26f6551f67bcc4a1750100\
00006b483045022100a08ebb92422b3599a2d2fcdaa11f8f807a66ccf33e7f4a9ff0a3c51f1b1e\
c5dd02205ed21dfede5925362b8d9833e908646c54be7ac6664e31650159e8f69b6ca539012103\
935581e52c354cd2f484fe8ed83af7a3097005b2f9c60bff71d35bd795f54b67ffffffff024042\
0f00000000001976a9141ec51b3654c1f1d0f4929d11a1f702937eaf50c888ac9fbb0d00000000\
001976a914d52ad7ca9b3d096a38e752c2018e6fbc40cdf26f88ac00000000A.7.5. Exercise 5
題目請參閱對應章節。
>>> from ecc import PrivateKey
>>> from helper import decode_base58, SIGHASH_ALL
>>> from script import p2pkh_script, Script
>>> from tx import TxIn, TxOut, Tx
>>> prev_tx_1 = bytes.fromhex('11d05ce707c1120248370d1cbf5561d22c4f83aeba04367\
92c82e0bd57fe2a2f')
>>> prev_index_1 = 1
>>> prev_tx_2 = bytes.fromhex('51f61f77bd061b9a0da60d4bedaaf1b1fad0c11e65fdc74\
4797ee22d20b03d15')
>>> prev_index_2 = 1
>>> target_address = 'mwJn1YPMq7y5F8J3LkC5Hxg9PHyZ5K4cFv'
>>> target_amount = 0.0429
>>> secret = 8675309
>>> priv = PrivateKey(secret=secret)
>>> tx_ins = []
>>> tx_ins.append(TxIn(prev_tx_1, prev_index_1))
>>> tx_ins.append(TxIn(prev_tx_2, prev_index_2))
>>> tx_outs = []
>>> h160 = decode_base58(target_address)
>>> script_pubkey = p2pkh_script(h160)
>>> target_satoshis = int(target_amount*100000000)
>>> tx_outs.append(TxOut(target_satoshis, script_pubkey))
>>> tx_obj = Tx(1, tx_ins, tx_outs, 0, testnet=True)
>>> print(tx_obj.sign_input(0, priv))
True
>>> print(tx_obj.sign_input(1, priv))
True
>>> print(tx_obj.serialize().hex())
01000000022f2afe57bde0822c793604baae834f2cd26155bf1c0d37480212c107e75cd0110100\
00006a47304402204cc5fe11b2b025f8fc9f6073b5e3942883bbba266b71751068badeb8f11f03\
64022070178363f5dea4149581a4b9b9dbad91ec1fd990e3fa14f9de3ccb421fa5b26901210393\
5581e52c354cd2f484fe8ed83af7a3097005b2f9c60bff71d35bd795f54b67ffffffff153db020\
2de27e7944c7fd651ec1d0fab1f1aaed4b0da60d9a1b06bd771ff651010000006b483045022100\
b7a938d4679aa7271f0d32d83b61a85eb0180cf1261d44feaad23dfd9799dafb02205ff2f366dd\
d9555f7146861a8298b7636be8b292090a224c5dc84268480d8be1012103935581e52c354cd2f4\
84fe8ed83af7a3097005b2f9c60bff71d35bd795f54b67ffffffff01d0754100000000001976a9\
14ad346f8eb57dee9a37981716e498120ae80e44f788ac00000000A.8. 第八章:支付到腳本雜湊(P2SH)
以下為第八章各練習題的解答。
A.8.1. Exercise 1
題目請參閱對應章節。
def op_checkmultisig(stack, z):
if len(stack) < 1:
return False
n = decode_num(stack.pop())
if len(stack) < n + 1:
return False
sec_pubkeys = []
for _ in range(n):
sec_pubkeys.append(stack.pop())
m = decode_num(stack.pop())
if len(stack) < m + 1:
return False
der_signatures = []
for _ in range(m):
der_signatures.append(stack.pop()[:-1])
stack.pop()
try:
points = [S256Point.parse(sec) for sec in sec_pubkeys]
sigs = [Signature.parse(der) for der in der_signatures]
for sig in sigs:
if len(points) == 0:
return False
while points:
point = points.pop(0)
if point.verify(z, sig):
break
stack.append(encode_num(1))
except (ValueError, SyntaxError):
return False
return TrueA.8.2. Exercise 2
題目請參閱對應章節。
def h160_to_p2pkh_address(h160, testnet=False):
if testnet:
prefix = b'\x6f'
else:
prefix = b'\x00'
return encode_base58_checksum(prefix + h160)A.8.3. Exercise 3
題目請參閱對應章節。
def h160_to_p2sh_address(h160, testnet=False):
if testnet:
prefix = b'\xc4'
else:
prefix = b'\x05'
return encode_base58_checksum(prefix + h160)A.8.4. Exercise 4
題目請參閱對應章節。
>>> from io import BytesIO
>>> from ecc import S256Point, Signature
>>> from helper import hash256, int_to_little_endian
>>> from script import Script
>>> from tx import Tx, SIGHASH_ALL
>>> hex_tx = '0100000001868278ed6ddfb6c1ed3ad5f8181eb0c7a385aa0836f01d5e4789e6\
bd304d87221a000000db00483045022100dc92655fe37036f47756db8102e0d7d5e28b3beb83a8\
fef4f5dc0559bddfb94e02205a36d4e4e6c7fcd16658c50783e00c341609977aed3ad00937bf4e\
e942a8993701483045022100da6bee3c93766232079a01639d07fa869598749729ae323eab8eef\
53577d611b02207bef15429dcadce2121ea07f233115c6f09034c0be68db99980b9a6c5e754022\
01475221022626e955ea6ea6d98850c994f9107b036b1334f18ca8830bfff1295d21cfdb702103\
b287eaf122eea69030a0e9feed096bed8045c8b98bec453e1ffac7fbdbd4bb7152aeffffffff04\
d3b11400000000001976a914904a49878c0adfc3aa05de7afad2cc15f483a56a88ac7f40090000\
0000001976a914418327e3f3dda4cf5b9089325a4b95abdfa0334088ac722c0c00000000001976\
a914ba35042cfe9fc66fd35ac2224eebdafd1028ad2788acdc4ace020000000017a91474d691da\
1574e6b3c192ecfb52cc8984ee7b6c568700000000'
>>> hex_sec = '03b287eaf122eea69030a0e9feed096bed8045c8b98bec453e1ffac7fbdbd4b\
b71'
>>> hex_der = '3045022100da6bee3c93766232079a01639d07fa869598749729ae323eab8ee\
f53577d611b02207bef15429dcadce2121ea07f233115c6f09034c0be68db99980b9a6c5e75402\
2'
>>> hex_redeem_script = '475221022626e955ea6ea6d98850c994f9107b036b1334f18ca88\
30bfff1295d21cfdb702103b287eaf122eea69030a0e9feed096bed8045c8b98bec453e1ffac7f\
bdbd4bb7152ae'
>>> sec = bytes.fromhex(hex_sec)
>>> der = bytes.fromhex(hex_der)
>>> redeem_script = Script.parse(BytesIO(bytes.fromhex(hex_redeem_script)))
>>> stream = BytesIO(bytes.fromhex(hex_tx))
>>> tx_obj = Tx.parse(stream)
>>> s = int_to_little_endian(tx_obj.version, 4)
>>> s += encode_varint(len(tx_obj.tx_ins))
>>> i = tx_obj.tx_ins[0]
>>> s += TxIn(i.prev_tx, i.prev_index, redeem_script, i.sequence).serialize()
>>> s += encode_varint(len(tx_obj.tx_outs))
>>> for tx_out in tx_obj.tx_outs:
... s += tx_out.serialize()
>>> s += int_to_little_endian(tx_obj.locktime, 4)
>>> s += int_to_little_endian(SIGHASH_ALL, 4)
>>> z = int.from_bytes(hash256(s), 'big')
>>> point = S256Point.parse(sec)
>>> sig = Signature.parse(der)
>>> print(point.verify(z, sig))
TrueA.8.5. Exercise 5
題目請參閱對應章節。
class Tx:
...
def sig_hash(self, input_index, redeem_script=None):
'''Returns the integer representation of the hash that needs to get
signed for index input_index'''
s = int_to_little_endian(self.version, 4)
s += encode_varint(len(self.tx_ins))
for i, tx_in in enumerate(self.tx_ins):
if i == input_index:
if redeem_script:
script_sig = redeem_script
else:
script_sig = tx_in.script_pubkey(self.testnet)
else:
script_sig = None
s += TxIn(
prev_tx=tx_in.prev_tx,
prev_index=tx_in.prev_index,
script_sig=script_sig,
sequence=tx_in.sequence,
).serialize()
s += encode_varint(len(self.tx_outs))
for tx_out in self.tx_outs:
s += tx_out.serialize()
s += int_to_little_endian(self.locktime, 4)
s += int_to_little_endian(SIGHASH_ALL, 4)
h256 = hash256(s)
return int.from_bytes(h256, 'big')
def verify_input(self, input_index):
tx_in = self.tx_ins[input_index]
script_pubkey = tx_in.script_pubkey(testnet=self.testnet)
if script_pubkey.is_p2sh_script_pubkey():
cmd = tx_in.script_sig.cmds[-1]
raw_redeem = encode_varint(len(cmd)) + cmd
redeem_script = Script.parse(BytesIO(raw_redeem))
else:
redeem_script = None
z = self.sig_hash(input_index, redeem_script)
combined = tx_in.script_sig + script_pubkey
return combined.evaluate(z)A.9. 第九章:區塊
以下為第九章各練習題的解答。
A.9.1. Exercise 1
題目請參閱對應章節。
class Tx:
...
def is_coinbase(self):
if len(self.tx_ins) != 1:
return False
first_input = self.tx_ins[0]
if first_input.prev_tx != b'\x00' * 32:
return False
if first_input.prev_index != 0xffffffff:
return False
return TrueA.9.2. Exercise 2
題目請參閱對應章節。
class Tx:
...
def coinbase_height(self):
if not self.is_coinbase():
return None
element = self.tx_ins[0].script_sig.cmds[0]
return little_endian_to_int(element)A.9.3. Exercise 3
題目請參閱對應章節。
class Block:
...
@classmethod
def parse(cls, s):
version = little_endian_to_int(s.read(4))
prev_block = s.read(32)[::-1]
merkle_root = s.read(32)[::-1]
timestamp = little_endian_to_int(s.read(4))
bits = s.read(4)
nonce = s.read(4)
return cls(version, prev_block, merkle_root, timestamp, bits, nonce)A.9.4. Exercise 4
題目請參閱對應章節。
class Block:
...
def serialize(self):
result = int_to_little_endian(self.version, 4)
result += self.prev_block[::-1]
result += self.merkle_root[::-1]
result += int_to_little_endian(self.timestamp, 4)
result += self.bits
result += self.nonce
return resultA.9.5. Exercise 5
題目請參閱對應章節。
class Block:
...
def hash(self):
s = self.serialize()
sha = hash256(s)
return sha[::-1]A.9.9. Exercise 9
題目請參閱對應章節。
def bits_to_target(bits):
exponent = bits[-1]
coefficient = little_endian_to_int(bits[:-1])
return coefficient * 256**(exponent - 3)A.9.10. Exercise 10
題目請參閱對應章節。
class Block:
...
def difficulty(self):
lowest = 0xffff * 256**(0x1d - 3)
return lowest / self.target()A.9.11. Exercise 11
題目請參閱對應章節。
class Block:
...
def check_pow(self):
sha = hash256(self.serialize())
proof = little_endian_to_int(sha)
return proof < self.target()A.9.12. Exercise 12
題目請參閱對應章節。
>>> from io import BytesIO
>>> from block import Block
>>> from helper import TWO_WEEKS
>>> from helper import target_to_bits
>>> block1_hex = '000000203471101bbda3fe307664b3283a9ef0e97d9a38a7eacd88000000\
00000000000010c8aba8479bbaa5e0848152fd3c2289ca50e1c3e58c9a4faaafbdf5803c5448dd\
b845597e8b0118e43a81d3'
>>> block2_hex = '02000020f1472d9db4b563c35f97c428ac903f23b7fc055d1cfc26000000\
000000000000b3f449fcbe1bc4cfbcb8283a0d2c037f961a3fdf2b8bedc144973735eea707e126\
4258597e8b0118e5f00474'
>>> last_block = Block.parse(BytesIO(bytes.fromhex(block1_hex)))
>>> first_block = Block.parse(BytesIO(bytes.fromhex(block2_hex)))
>>> time_differential = last_block.timestamp - first_block.timestamp
>>> if time_differential > TWO_WEEKS * 4:
... time_differential = TWO_WEEKS * 4
>>> if time_differential < TWO_WEEKS // 4:
... time_differential = TWO_WEEKS // 4
>>> new_target = last_block.target() * time_differential // TWO_WEEKS
>>> new_bits = target_to_bits(new_target)
>>> print(new_bits.hex())
80df6217A.9.13. Exercise 13
題目請參閱對應章節。
def calculate_new_bits(previous_bits, time_differential):
if time_differential > TWO_WEEKS * 4:
time_differential = TWO_WEEKS * 4
if time_differential < TWO_WEEKS // 4:
time_differential = TWO_WEEKS // 4
new_target = bits_to_target(previous_bits) * time_differential // TWO_WEEKS
return target_to_bits(new_target)A.10. 第十章:比特幣網路通訊
以下為第十章各練習題的解答。
A.10.1. Exercise 1
題目請參閱對應章節。
@classmethod
def parse(cls, s, testnet=False):
magic = s.read(4)
if magic == b'':
raise IOError('Connection reset!')
if testnet:
expected_magic = TESTNET_NETWORK_MAGIC
else:
expected_magic = NETWORK_MAGIC
if magic != expected_magic:
raise SyntaxError('magic is not right {} vs {}'.format(magic.hex(),
expected_magic.hex()))
command = s.read(12)
command = command.strip(b'\x00')
payload_length = little_endian_to_int(s.read(4))
checksum = s.read(4)
payload = s.read(payload_length)
calculated_checksum = hash256(payload)[:4]
if calculated_checksum != checksum:
raise IOError('checksum does not match')
return cls(command, payload, testnet=testnet)A.10.2. Exercise 2
題目請參閱對應章節。
>>> from network import NetworkEnvelope
>>> from io import BytesIO
>>> message_hex = 'f9beb4d976657261636b000000000000000000005df6e0e2'
>>> stream = BytesIO(bytes.fromhex(message_hex))
>>> envelope = NetworkEnvelope.parse(stream)
>>> print(envelope.command)
b'verack'
>>> print(envelope.payload)
b''A.10.3. Exercise 3
題目請參閱對應章節。
class NetworkEnvelope:
...
def serialize(self):
result = self.magic
result += self.command + b'\x00' * (12 - len(self.command))
result += int_to_little_endian(len(self.payload), 4)
result += hash256(self.payload)[:4]
result += self.payload
return resultA.10.4. Exercise 4
題目請參閱對應章節。
class VersionMessage:
...
def serialize(self):
result = int_to_little_endian(self.version, 4)
result += int_to_little_endian(self.services, 8)
result += int_to_little_endian(self.timestamp, 8)
result += int_to_little_endian(self.receiver_services, 8)
result += b'\x00' * 10 + b'\xff\xff' + self.receiver_ip
result += self.receiver_port.to_bytes(2, 'big')
result += int_to_little_endian(self.sender_services, 8)
result += b'\x00' * 10 + b'\xff\xff' + self.sender_ip
result += self.sender_port.to_bytes(2, 'big')
result += self.nonce
result += encode_varint(len(self.user_agent))
result += self.user_agent
result += int_to_little_endian(self.latest_block, 4)
if self.relay:
result += b'\x01'
else:
result += b'\x00'
return resultA.11. 第十一章:簡單支付驗證
以下為第十一章各練習題的解答。
A.11.1. Exercise 1
題目請參閱對應章節。
def merkle_parent(hash1, hash2):
'''Takes the binary hashes and calculates the hash256'''
return hash256(hash1 + hash2)A.11.2. Exercise 2
題目請參閱對應章節。
def merkle_parent_level(hashes):
'''Takes a list of binary hashes and returns a list that's half
the length'''
if len(hashes) == 1:
raise RuntimeError('Cannot take a parent level with only 1 item')
if len(hashes) % 2 == 1:
hashes.append(hashes[-1])
parent_level = []
for i in range(0, len(hashes), 2):
parent = merkle_parent(hashes[i], hashes[i + 1])
parent_level.append(parent)
return parent_levelA.11.3. Exercise 3
題目請參閱對應章節。
def merkle_root(hashes):
'''Takes a list of binary hashes and returns the merkle root
'''
current_level = hashes
while len(current_level) > 1:
current_level = merkle_parent_level(current_level)
return current_level[0]A.11.4. Exercise 4
題目請參閱對應章節。
class Block:
...
def validate_merkle_root(self):
hashes = [h[::-1] for h in self.tx_hashes]
root = merkle_root(hashes)
return root[::-1] == self.merkle_rootA.11.5. Exercise 5
題目請參閱對應章節。
>>> import math
>>> total = 27
>>> max_depth = math.ceil(math.log(total, 2))
>>> merkle_tree = []
>>> for depth in range(max_depth + 1):
... num_items = math.ceil(total / 2**(max_depth - depth))
... level_hashes = [None] * num_items
... merkle_tree.append(level_hashes)
>>> for level in merkle_tree:
... print(level)
[None]
[None, None]
[None, None, None, None]
[None, None, None, None, None, None, None]
[None, None, None, None, None, None, None, None, None, None, None, None, None,\
None]
[None, None, None, None, None, None, None, None, None, None, None, None, None,\
None, None, None, None, None, None, None, None, None, None, None, None, None,\
None]A.11.6. Exercise 6
題目請參閱對應章節。
class MerkleBlock:
...
@classmethod
def parse(cls, s):
version = little_endian_to_int(s.read(4))
prev_block = s.read(32)[::-1]
merkle_root = s.read(32)[::-1]
timestamp = little_endian_to_int(s.read(4))
bits = s.read(4)
nonce = s.read(4)
total = little_endian_to_int(s.read(4))
num_hashes = read_varint(s)
hashes = []
for _ in range(num_hashes):
hashes.append(s.read(32)[::-1])
flags_length = read_varint(s)
flags = s.read(flags_length)
return cls(version, prev_block, merkle_root, timestamp, bits,
nonce, total, hashes, flags)A.12. 第十二章:布隆過濾器
以下為第十二章各練習題的解答。
A.12.1. Exercise 1
題目請參閱對應章節。
>>> from helper import hash160
>>> bit_field_size = 10
>>> bit_field = [0] * bit_field_size
>>> for item in (b'hello world', b'goodbye'):
... h = hash160(item)
... bit = int.from_bytes(h, 'big') % bit_field_size
... bit_field[bit] = 1
>>> print(bit_field)
[1, 1, 0, 0, 0, 0, 0, 0, 0, 0]A.12.2. Exercise 2
題目請參閱對應章節。
>>> from bloomfilter import BloomFilter, BIP37_CONSTANT
>>> from helper import bit_field_to_bytes, murmur3
>>> field_size = 10
>>> function_count = 5
>>> tweak = 99
>>> items = (b'Hello World', b'Goodbye!')
>>> bit_field_size = field_size * 8
>>> bit_field = [0] * bit_field_size
>>> for item in items:
... for i in range(function_count):
... seed = i * BIP37_CONSTANT + tweak
... h = murmur3(item, seed=seed)
... bit = h % bit_field_size
... bit_field[bit] = 1
>>> print(bit_field_to_bytes(bit_field).hex())
4000600a080000010940A.12.3. Exercise 3
題目請參閱對應章節。
class BloomFilter:
...
def add(self, item):
for i in range(self.function_count):
seed = i * BIP37_CONSTANT + self.tweak
h = murmur3(item, seed=seed)
bit = h % (self.size * 8)
self.bit_field[bit] = 1A.12.4. Exercise 4
題目請參閱對應章節。
class BloomFilter:
...
def filterload(self, flag=1):
payload = encode_varint(self.size)
payload += self.filter_bytes()
payload += int_to_little_endian(self.function_count, 4)
payload += int_to_little_endian(self.tweak, 4)
payload += int_to_little_endian(flag, 1)
return GenericMessage(b'filterload', payload)A.12.5. Exercise 5
題目請參閱對應章節。
class GetDataMessage:
...
def serialize(self):
result = encode_varint(len(self.data))
for data_type, identifier in self.data:
result += int_to_little_endian(data_type, 4)
result += identifier[::-1]
return resultA.12.6. Exercise 6
題目請參閱對應章節。
>>> import time
>>> from block import Block
>>> from bloomfilter import BloomFilter
>>> from ecc import PrivateKey
>>> from helper import (
... decode_base58,
... encode_varint,
... hash256,
... little_endian_to_int,
... read_varint,
... )
>>> from merkleblock import MerkleBlock
>>> from network import (
... GetDataMessage,
... GetHeadersMessage,
... HeadersMessage,
... NetworkEnvelope,
... SimpleNode,
... TX_DATA_TYPE,
... FILTERED_BLOCK_DATA_TYPE,
... )
>>> from script import p2pkh_script, Script
>>> from tx import Tx, TxIn, TxOut
>>> last_block_hex = '00000000000000a03f9432ac63813c6710bfe41712ac5ef6faab093f\
e2917636'
>>> secret = little_endian_to_int(hash256(b'Jimmy Song'))
>>> private_key = PrivateKey(secret=secret)
>>> addr = private_key.point.address(testnet=True)
>>> h160 = decode_base58(addr)
>>> target_address = 'mwJn1YPMq7y5F8J3LkC5Hxg9PHyZ5K4cFv'
>>> target_h160 = decode_base58(target_address)
>>> target_script = p2pkh_script(target_h160)
>>> fee = 5000 # fee in satoshis
>>> # connect to testnet.programmingbitcoin.com in testnet mode
>>> node = SimpleNode('testnet.programmingbitcoin.com', testnet=True, logging=\
False)
>>> # Create a Bloom Filter of size 30 and 5 functions. Add a tweak.
>>> bf = BloomFilter(30, 5, 90210)
>>> # add the h160 to the Bloom Filter
>>> bf.add(h160)
>>> # complete the handshake
>>> node.handshake()
>>> # load the Bloom Filter with the filterload command
>>> node.send(bf.filterload())
>>> # set start block to last_block from above
>>> start_block = bytes.fromhex(last_block_hex)
>>> # send a getheaders message with the starting block
>>> getheaders = GetHeadersMessage(start_block=start_block)
>>> node.send(getheaders)
>>> # wait for the headers message
>>> headers = node.wait_for(HeadersMessage)
>>> # store the last block as None
>>> last_block = None
>>> # initialize the GetDataMessage
>>> getdata = GetDataMessage()
>>> # loop through the blocks in the headers
>>> for b in headers.blocks:
... # check that the proof of work on the block is valid
... if not b.check_pow():
... raise RuntimeError('proof of work is invalid')
... # check that this block's prev_block is the last block
... if last_block is not None and b.prev_block != last_block:
... raise RuntimeError('chain broken')
... # add a new item to the getdata message
... # should be FILTERED_BLOCK_DATA_TYPE and block hash
... getdata.add_data(FILTERED_BLOCK_DATA_TYPE, b.hash())
... # set the last block to the current hash
... last_block = b.hash()
>>> # send the getdata message
>>> node.send(getdata)
>>> # initialize prev_tx, prev_index, and prev_amount to None
>>> prev_tx, prev_index, prev_amount = None, None, None
>>> # loop while prev_tx is None
>>> while prev_tx is None:
... # wait for the merkleblock or tx commands
... message = node.wait_for(MerkleBlock, Tx)
... # if we have the merkleblock command
... if message.command == b'merkleblock':
... # check that the MerkleBlock is valid
... if not message.is_valid():
... raise RuntimeError('invalid merkle proof')
... # else we have the tx command
... else:
... # set the tx's testnet to be True
... message.testnet = True
... # loop through the tx outs
... for i, tx_out in enumerate(message.tx_outs):
... # if our output has the same address as our address we found it
... if tx_out.script_pubkey.address(testnet=True) == addr:
... # we found our utxo; set prev_tx, prev_index, and tx
... prev_tx = message.hash()
... prev_index = i
... prev_amount = tx_out.amount
... print('found: {}:{}'.format(prev_tx.hex(), prev_index))
found: b2cddd41d18d00910f88c31aa58c6816a190b8fc30fe7c665e1cd2ec60efdf3f:7
>>> # create the TxIn
>>> tx_in = TxIn(prev_tx, prev_index)
>>> # calculate the output amount (previous amount minus the fee)
>>> output_amount = prev_amount - fee
>>> # create a new TxOut to the target script with the output amount
>>> tx_out = TxOut(output_amount, target_script)
>>> # create a new transaction with the one input and one output
>>> tx_obj = Tx(1, [tx_in], [tx_out], 0, testnet=True)
>>> # sign the only input of the transaction
>>> print(tx_obj.sign_input(0, private_key))
True
>>> # serialize and hex to see what it looks like
>>> print(tx_obj.serialize().hex())
01000000013fdfef60ecd21c5e667cfe30fcb890a116688ca51ac3880f91008dd141ddcdb20700\
00006b483045022100ff77d2559261df5490ed00d231099c4b8ea867e6ccfe8e3e6d077313ed4f\
1428022033a1db8d69eb0dc376f89684d1ed1be75719888090388a16f1e8eedeb8067768012103\
dc585d46cfca73f3a75ba1ef0c5756a21c1924587480700c6eb64e3f75d22083ffffffff019334\
e500000000001976a914ad346f8eb57dee9a37981716e498120ae80e44f788ac00000000
>>> # send this signed transaction on the network
>>> node.send(tx_obj)
>>> # wait a sec so this message goes through with time.sleep(1)
>>> time.sleep(1)
>>> # now ask for this transaction from the other node
>>> # create a GetDataMessage
>>> getdata = GetDataMessage()
>>> # ask for our transaction by adding it to the message
>>> getdata.add_data(TX_DATA_TYPE, tx_obj.hash())
>>> # send the message
>>> node.send(getdata)
>>> # now wait for a Tx response
>>> received_tx = node.wait_for(Tx)
>>> # if the received tx has the same id as our tx, we are done!
>>> if received_tx.id() == tx_obj.id():
... print('success!')
success!15. 關於作者
Jimmy Song 有超過20年的開發經驗,從本出版社(譯注:指ORILLY)的《Programming Perl》入門稱為程序員。他參與了多個創業項目並在2014全職參與了比特幣的開發工作。多年來他為多個比特幣的開源項目貢獻了代碼,包括 Armory,Bitcoin Core,btcd 和 pycoin。
如果你見到Jimmy,和他聊下面的這些話題都會讓他變得健談起來:比特幣,金屬貨幣(sound money),法幣(fiat money)是如何是一切變得糟糕的,齋戒,食肉,舉重,舉起孩子 以及牛仔帽。
15.1. 關於封面
(colonphon)
本書封面的動物是蜜獾 (honey badger, 學名 Mellivora capensis)
它遍布非洲,印度次大陸和西南亞。蜜獾是食肉動物,少有天敵,因為當蜜獾防禦時,會展現難以置信的暴烈的本性。如果只看封面而不看它的名字,看上去和黃鼠狼或者臭鼬類似,很難將之歸類於蜜獾。
蜜獾的名字來源於這種動物習慣突襲蜂巢來獲取蜂蜜(和蜂的幼蟲)。蜜獾有非常厚的表皮,用來盡量減少蜜蜂叮咬影響。蜜獾的食物來源非常多樣化,其中有 蛇(包括有毒的品種),嚙齒動物,昆蟲,蛋,鳥類,果實,植物的根,植物的鱗莖。有人曾觀察到蜜獾正追逐捕獵幼獅。蜜獾也是少見的幾個會使用工具的動物之一。
蜜獾是一個非常強壯的動物,有一個常長的軀乾,寬的背部,和一個小的扁平的頭部。蜜獾的腿非常短,腳上有強壯爪子,這使其成為不同尋常的挖掘好手。蜜獾不僅挖掘來獲得食物,蜜獾還為會自己挖掘一個洞穴(平均3-10英尺長)。在它的尾巴底部有一個分泌腺,其分泌的臭味會來標記領土和警告其他動物。
在後頸處的皮膚時鬆弛的,當它被擒拿時,蜜獾可以扭轉頭部並撕咬。
2011年,蜜獾成為一個病毒視頻的主題,國家地理的以其特色的幽默的鏡頭語言展現了蜜獾無畏行為。
O’Reilly 封面上的許多動物瀕臨滅絕,這些動物對這個世界也至關重要。請訪問animals.oreilly.com來瞭解如何對這些動物施以援手。
封面圖片來自Karen Montgomery的《自然動物史》中的黑白版畫。封面字體是Gilroy Semibold 和 Guardian Sans。正文字體是 Adobe Minion Pro, 標題字體是Adobe Myriad Condensed, 代碼使用的字體為 Dalton Maag’s Ubuntu Mono.